 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBERT and PALs: Projected Attention Layers for Efficient Adaptation in Multi-Task Learning
Feb 07, 2019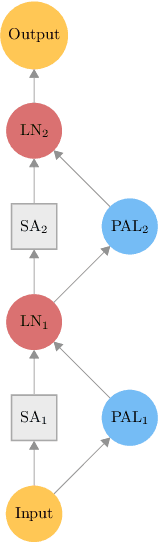


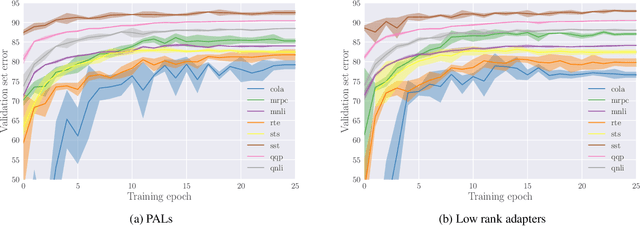
Multi-task learning allows the sharing of useful information between multiple related tasks. In natural language processing several recent approaches have successfully leveraged unsupervised pre-training on large amounts of data to perform well on various tasks, such as those in the GLUE benchmark. These results are based on fine-tuning on each task separately. We explore the multi-task learning setting for the recent BERT model on the GLUE benchmark, and how to best add task-specific parameters to a pre-trained BERT network, with a high degree of parameter sharing between tasks. We introduce new adaptation modules, PALs or `projected attention layers', which use a low-dimensional multi-head attention mechanism, based on the idea that it is important to include layers with inductive biases useful for the input domain. By using PALs in parallel with BERT layers, we match the performance of fine-tuned BERT on the GLUE benchmark with roughly 7 times fewer parameters, and obtain state-of-the-art results on the Recognizing Textual Entailment dataset.
Bayesian Adversarial Spheres: Bayesian Inference and Adversarial Examples in a Noiseless Setting
Nov 29, 2018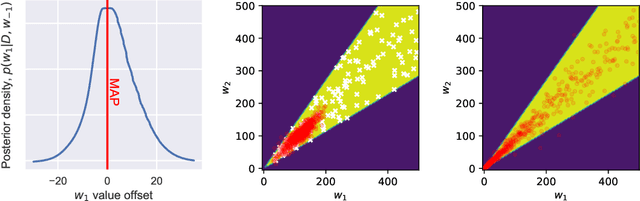
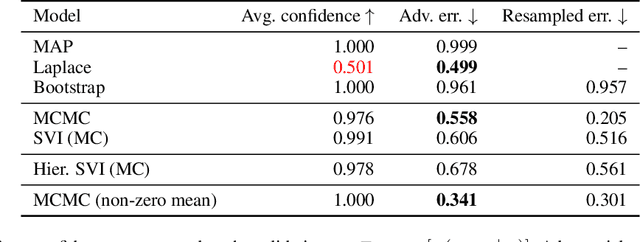
Modern deep neural network models suffer from adversarial examples, i.e. confidently misclassified points in the input space. It has been shown that Bayesian neural networks are a promising approach for detecting adversarial points, but careful analysis is problematic due to the complexity of these models. Recently Gilmer et al. (2018) introduced adversarial spheres, a toy set-up that simplifies both practical and theoretical analysis of the problem. In this work, we use the adversarial sphere set-up to understand the properties of approximate Bayesian inference methods for a linear model in a noiseless setting. We compare predictions of Bayesian and non-Bayesian methods, showcasing the advantages of the former, although revealing open challenges for deep learning applications.
Sequential Neural Methods for Likelihood-free Inference
Nov 21, 2018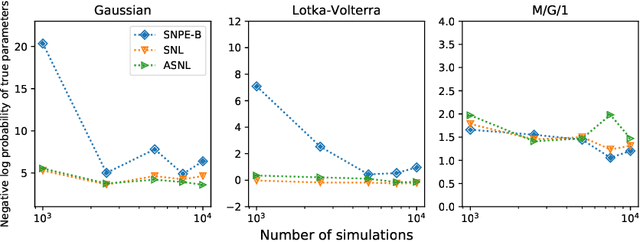
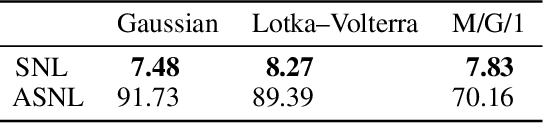
Likelihood-free inference refers to inference when a likelihood function cannot be explicitly evaluated, which is often the case for models based on simulators. Most of the literature is based on sample-based `Approximate Bayesian Computation' methods, but recent work suggests that approaches based on deep neural conditional density estimators can obtain state-of-the-art results with fewer simulations. The neural approaches vary in how they choose which simulations to run and what they learn: an approximate posterior or a surrogate likelihood. This work provides some direct controlled comparisons between these choices.
Mode Normalization
Oct 12, 2018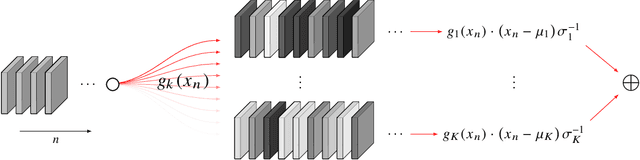
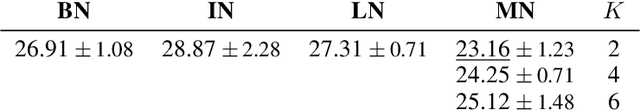
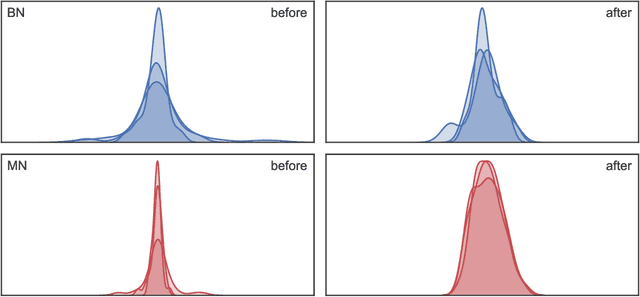

Normalization methods are a central building block in the deep learning toolbox. They accelerate and stabilize training, while decreasing the dependence on manually tuned learning rate schedules. When learning from multi-modal distributions, the effectiveness of batch normalization (BN), arguably the most prominent normalization method, is reduced. As a remedy, we propose a more flexible approach: by extending the normalization to more than a single mean and variance, we detect modes of data on-the-fly, jointly normalizing samples that share common features. We demonstrate that our method outperforms BN and other widely used normalization techniques in several experiments, including single and multi-task datasets.
Model Criticism in Latent Space
Jul 02, 2018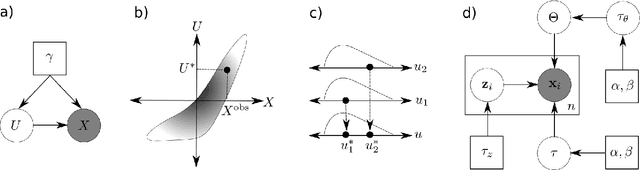


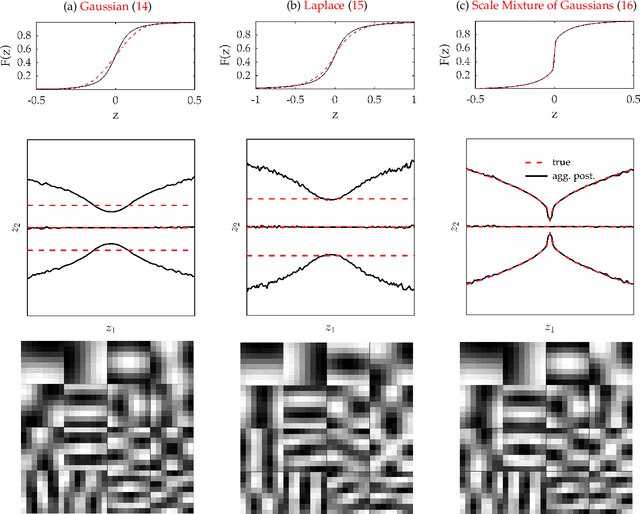
Model criticism is usually carried out by assessing if replicated data generated under the fitted model looks similar to the observed data, see e.g. Gelman, Carlin, Stern, and Rubin [2004, p. 165]. This paper presents a method for latent variable models by pulling back the data into the space of latent variables, and carrying out model criticism in that space. Making use of a model's structure enables a more direct assessment of the assumptions made in the prior and likelihood. We demonstrate the method with examples of model criticism in latent space applied to factor analysis, linear dynamical systems and Gaussian processes.
Masked Autoregressive Flow for Density Estimation
Jun 14, 2018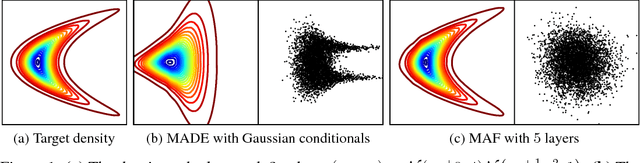

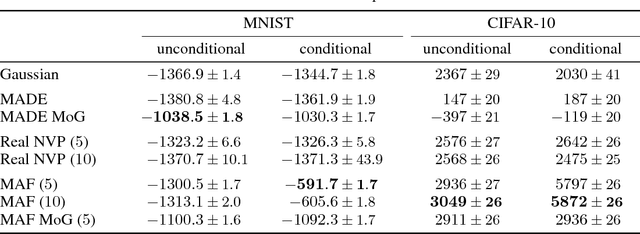
Autoregressive models are among the best performing neural density estimators. We describe an approach for increasing the flexibility of an autoregressive model, based on modelling the random numbers that the model uses internally when generating data. By constructing a stack of autoregressive models, each modelling the random numbers of the next model in the stack, we obtain a type of normalizing flow suitable for density estimation, which we call Masked Autoregressive Flow. This type of flow is closely related to Inverse Autoregressive Flow and is a generalization of Real NVP. Masked Autoregressive Flow achieves state-of-the-art performance in a range of general-purpose density estimation tasks.
Sequential Neural Likelihood: Fast Likelihood-free Inference with Autoregressive Flows
May 18, 2018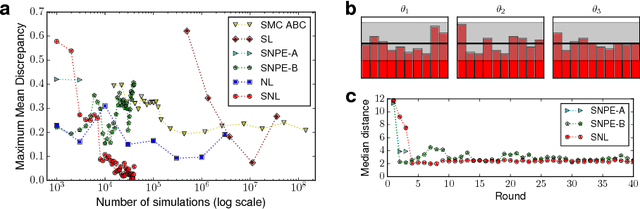
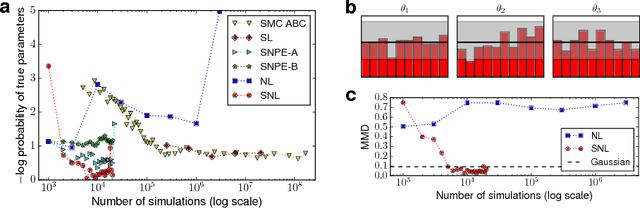
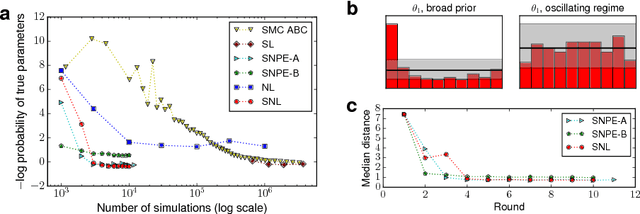
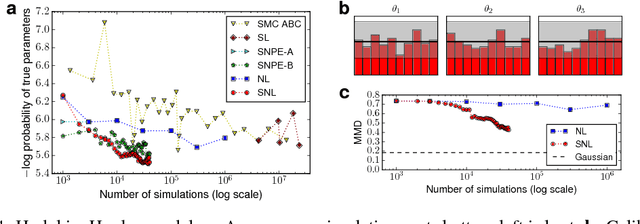
We present Sequential Neural Likelihood (SNL), a new method for Bayesian inference in simulator models, where the likelihood is intractable but simulating data from the model is possible. SNL trains an autoregressive flow on simulated data in order to learn a model of the likelihood in the region of high posterior density. A sequential training procedure guides simulations and reduces simulation cost by orders of magnitude. We show that SNL is more robust, more accurate and requires less tuning than related state-of-the-art methods which target the posterior, and discuss diagnostics for assessing calibration, convergence and goodness-of-fit.
Fast $ε$-free Inference of Simulation Models with Bayesian Conditional Density Estimation
Apr 02, 2018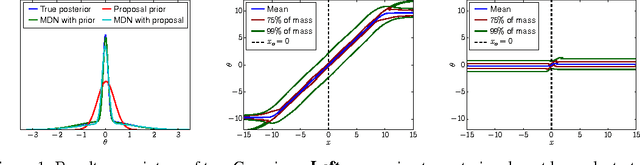
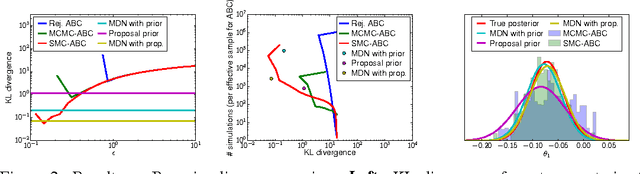
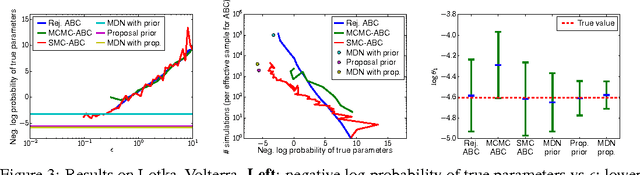
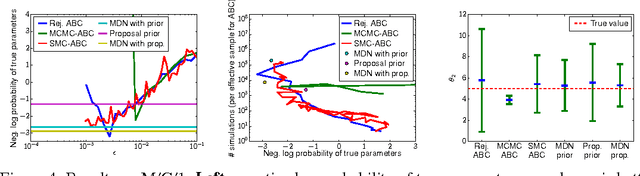
Many statistical models can be simulated forwards but have intractable likelihoods. Approximate Bayesian Computation (ABC) methods are used to infer properties of these models from data. Traditionally these methods approximate the posterior over parameters by conditioning on data being inside an $\epsilon$-ball around the observed data, which is only correct in the limit $\epsilon\!\rightarrow\!0$. Monte Carlo methods can then draw samples from the approximate posterior to approximate predictions or error bars on parameters. These algorithms critically slow down as $\epsilon\!\rightarrow\!0$, and in practice draw samples from a broader distribution than the posterior. We propose a new approach to likelihood-free inference based on Bayesian conditional density estimation. Preliminary inferences based on limited simulation data are used to guide later simulations. In some cases, learning an accurate parametric representation of the entire true posterior distribution requires fewer model simulations than Monte Carlo ABC methods need to produce a single sample from an approximate posterior.
Dynamic Evaluation of Neural Sequence Models
Oct 25, 2017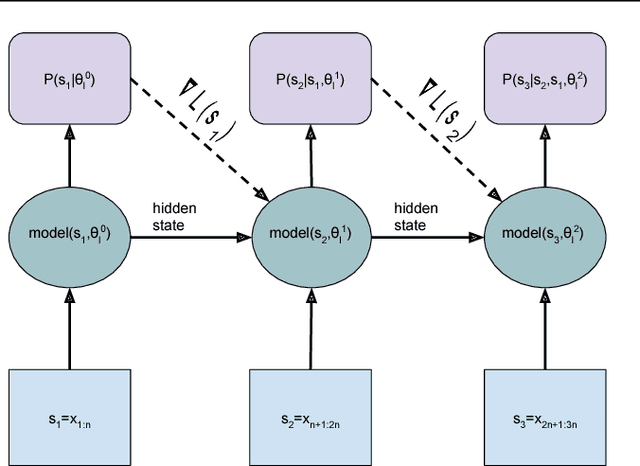
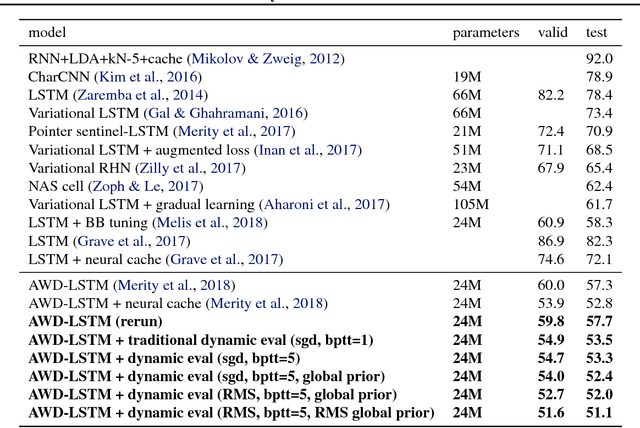
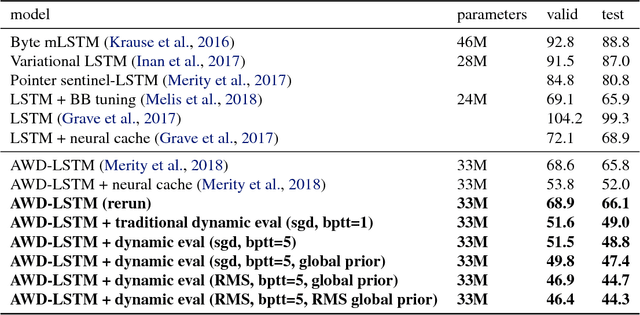
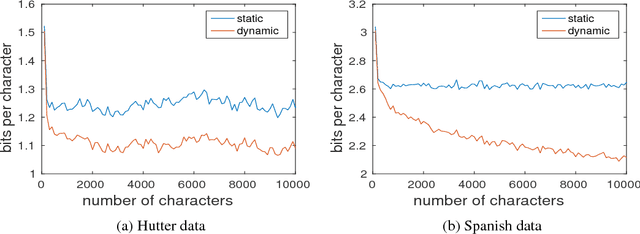
We present methodology for using dynamic evaluation to improve neural sequence models. Models are adapted to recent history via a gradient descent based mechanism, causing them to assign higher probabilities to re-occurring sequential patterns. Dynamic evaluation outperforms existing adaptation approaches in our comparisons. Dynamic evaluation improves the state-of-the-art word-level perplexities on the Penn Treebank and WikiText-2 datasets to 51.1 and 44.3 respectively, and the state-of-the-art character-level cross-entropies on the text8 and Hutter Prize datasets to 1.19 bits/char and 1.08 bits/char respectively.
Multiplicative LSTM for sequence modelling
Oct 12, 2017
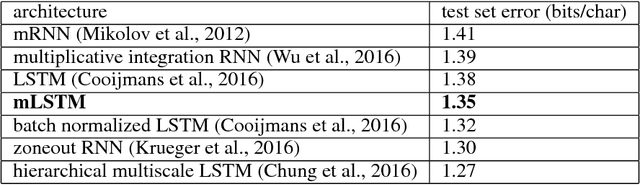
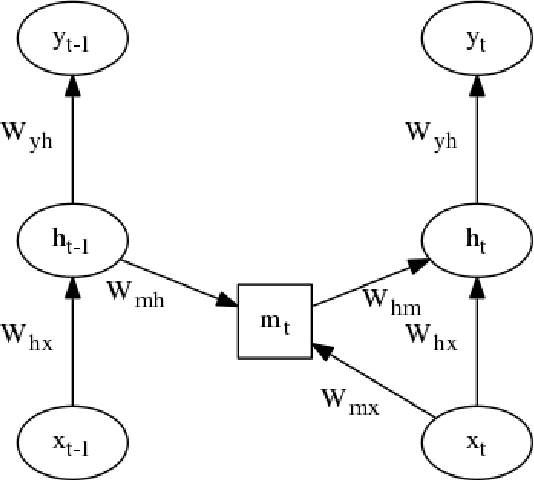

We introduce multiplicative LSTM (mLSTM), a recurrent neural network architecture for sequence modelling that combines the long short-term memory (LSTM) and multiplicative recurrent neural network architectures. mLSTM is characterised by its ability to have different recurrent transition functions for each possible input, which we argue makes it more expressive for autoregressive density estimation. We demonstrate empirically that mLSTM outperforms standard LSTM and its deep variants for a range of character level language modelling tasks. In this version of the paper, we regularise mLSTM to achieve 1.27 bits/char on text8 and 1.24 bits/char on Hutter Prize. We also apply a purely byte-level mLSTM on the WikiText-2 dataset to achieve a character level entropy of 1.26 bits/char, corresponding to a word level perplexity of 88.8, which is comparable to word level LSTMs regularised in similar ways on the same task.