 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance Monitoring for End-to-End Speech Recognition
Apr 09, 2019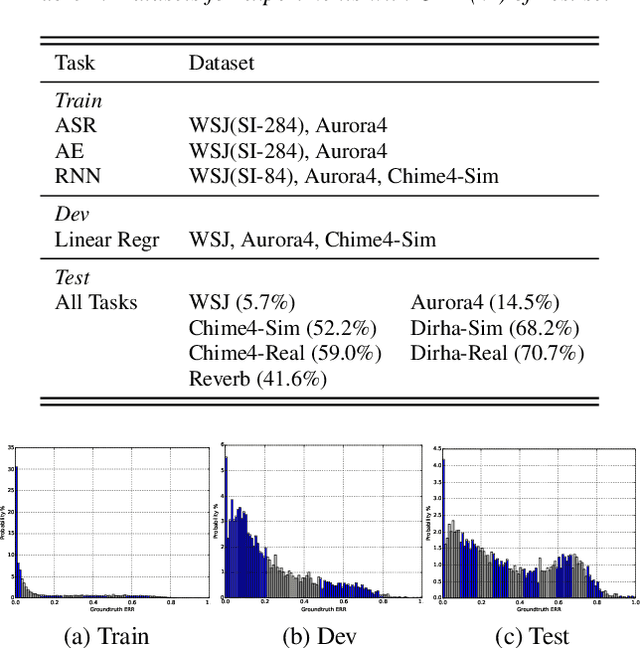
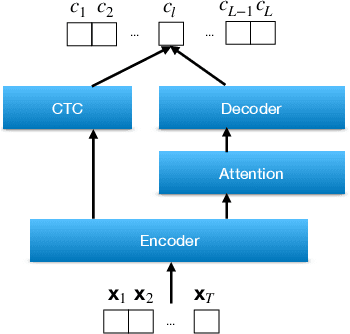
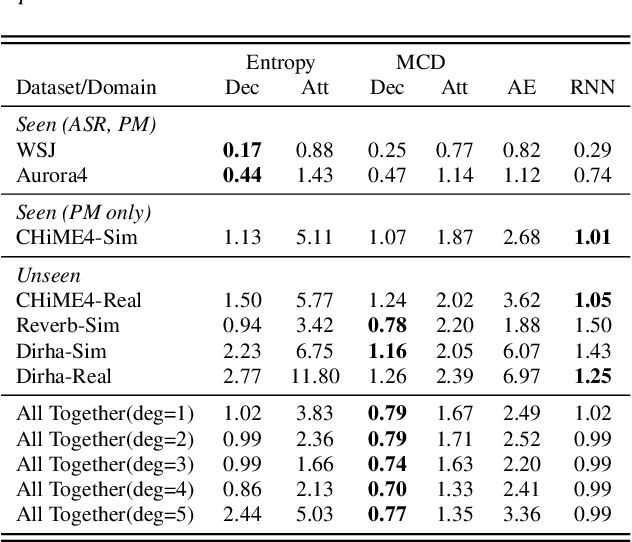
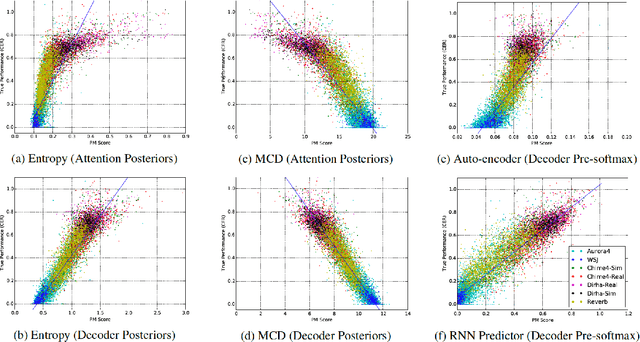
Measuring performance of an automatic speech recognition (ASR) system without ground-truth could be beneficial in many scenarios, especially with data from unseen domains, where performance can be highly inconsistent. In conventional ASR systems, several performance monitoring (PM) techniques have been well-developed to monitor performance by looking at tri-phone posteriors or pre-softmax activations from neural network acoustic modeling. However, strategies for monitoring more recently developed end-to-end ASR systems have not yet been explored, and so that is the focus of this paper. We adapt previous PM measures (Entropy, M-measure and Auto-encoder) and apply our proposed RNN predictor in the end-to-end setting. These measures utilize the decoder output layer and attention probability vectors, and their predictive power is measured with simple linear models. Our findings suggest that decoder-level features are more feasible and informative than attention-level probabilities for PM measures, and that M-measure on the decoder posteriors achieves the best overall predictive performance with an average prediction error 8.8%. Entropy measures and RNN-based prediction also show competitive predictability, especially for unseen conditions.
Exploring Methods for the Automatic Detection of Errors in Manual Transcription
Apr 08, 2019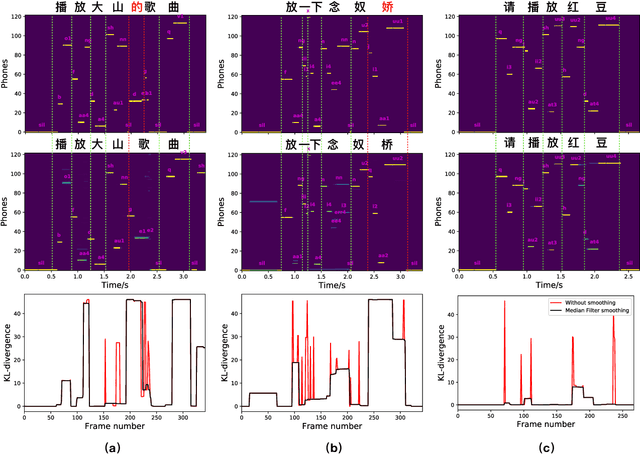

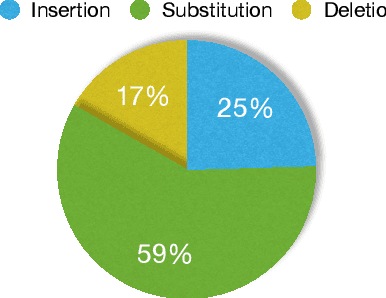

Quality of data plays an important role in most deep learning tasks. In the speech community, transcription of speech recording is indispensable. Since the transcription is usually generated artificially, automatically finding errors in manual transcriptions not only saves time and labors but benefits the performance of tasks that need the training process. Inspired by the success of hybrid automatic speech recognition using both language model and acoustic model, two approaches of automatic error detection in the transcriptions have been explored in this work. Previous study using a biased language model approach, relying on a strong transcription-dependent language model, has been reviewed. In this work, we propose a novel acoustic model based approach, focusing on the phonetic sequence of speech. Both methods have been evaluated on a completely real dataset, which was originally transcribed with errors and strictly corrected manually afterwards.
Stream attention-based multi-array end-to-end speech recognition
Nov 12, 2018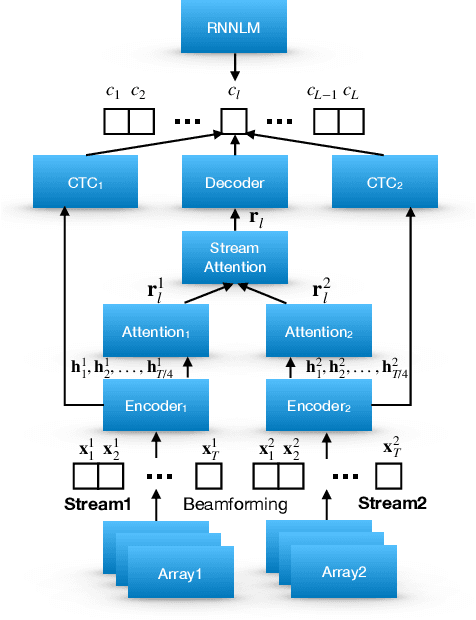
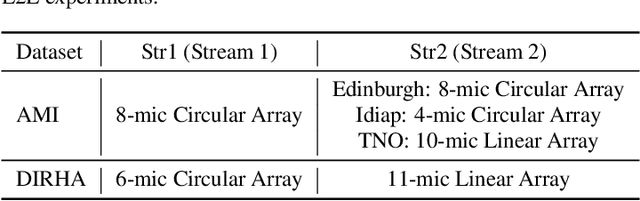
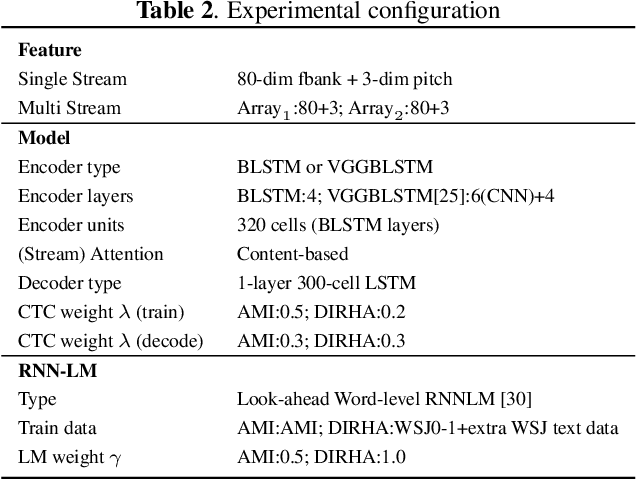
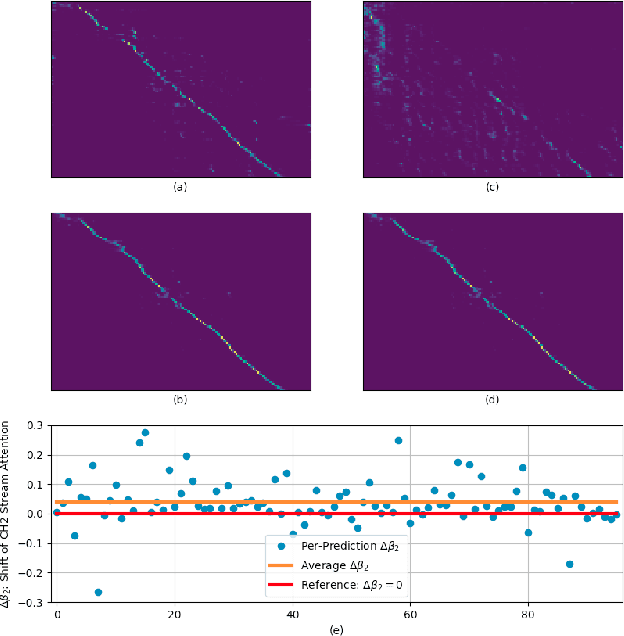
Automatic Speech Recognition (ASR) using multiple microphone arrays has achieved great success in the far-field robustness. Taking advantage of all the information that each array shares and contributes is crucial in this task. Motivated by the advances of joint Connectionist Temporal Classification (CTC)/attention mechanism in the End-to-End (E2E) ASR, a stream attention-based multi-array framework is proposed in this work. Microphone arrays, acting as information streams, are activated by separate encoders and decoded under the instruction of both CTC and attention networks. In terms of attention, a hierarchical structure is adopted. On top of the regular attention networks, stream attention is introduced to steer the decoder toward the most informative encoders. Experiments have been conducted on AMI and DIRHA multi-array corpora using the encoder-decoder architecture. Compared with the best single-array results, the proposed framework has achieved relative Word Error Rates (WERs) reduction of 3.7% and 9.7% in the two datasets, respectively, which is better than conventional strategies as well.
Multi-encoder multi-resolution framework for end-to-end speech recognition
Nov 12, 2018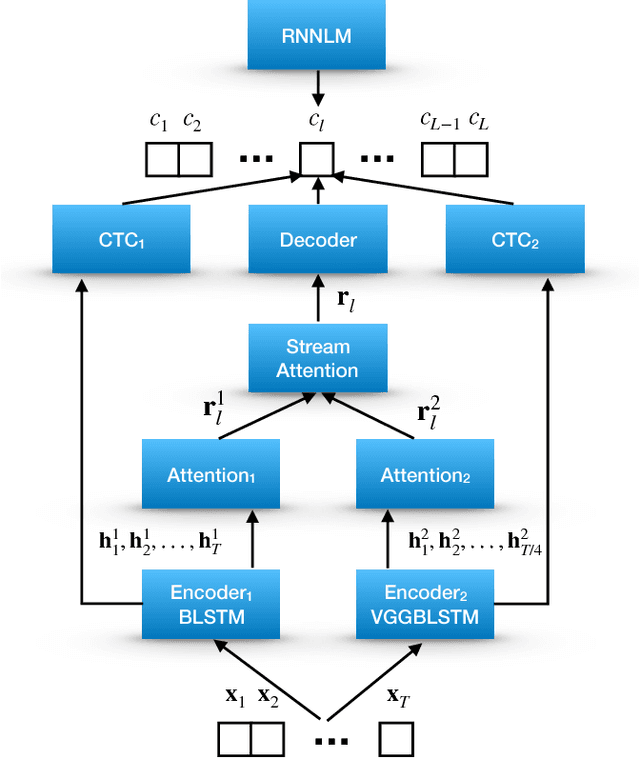
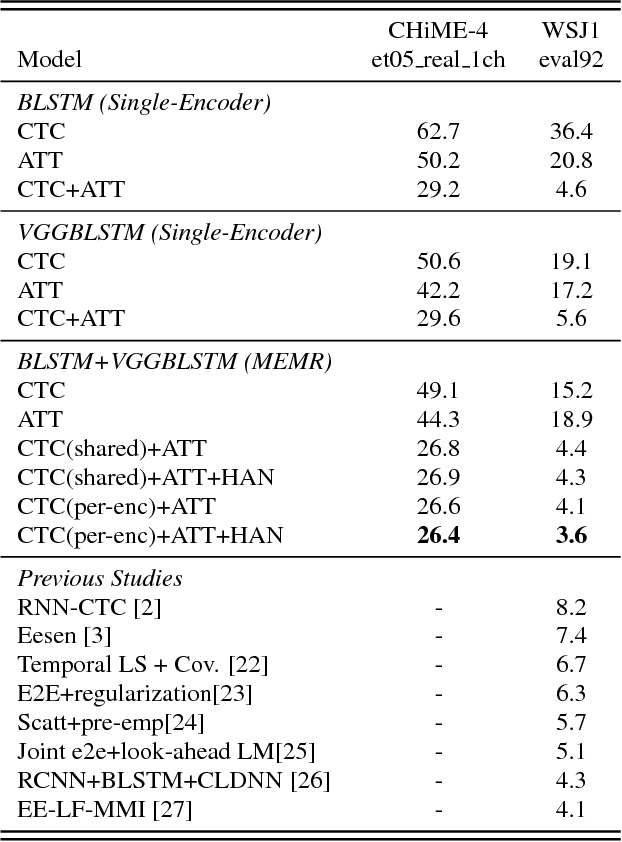
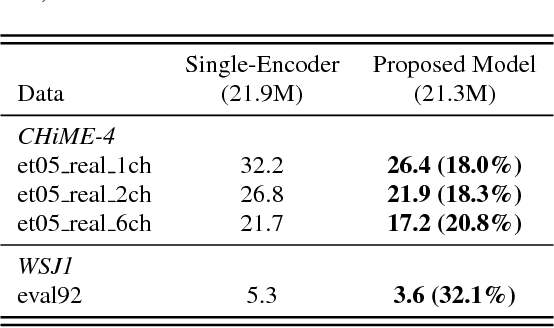

Attention-based methods and Connectionist Temporal Classification (CTC) network have been promising research directions for end-to-end Automatic Speech Recognition (ASR). The joint CTC/Attention model has achieved great success by utilizing both architectures during multi-task training and joint decoding. In this work, we present a novel Multi-Encoder Multi-Resolution (MEMR) framework based on the joint CTC/Attention model. Two heterogeneous encoders with different architectures, temporal resolutions and separate CTC networks work in parallel to extract complimentary acoustic information. A hierarchical attention mechanism is then used to combine the encoder-level information. To demonstrate the effectiveness of the proposed model, experiments are conducted on Wall Street Journal (WSJ) and CHiME-4, resulting in relative Word Error Rate (WER) reduction of 18.0-32.1%. Moreover, the proposed MEMR model achieves 3.6% WER in the WSJ eval92 test set, which is the best WER reported for an end-to-end system on this benchmark.