 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePushing the Performance of Synthetic Speech Detection with Kolmogorov-Arnold Networks and Self-Supervised Learning Models
Jun 17, 2025



Recent advancements in speech synthesis technologies have led to increasingly advanced spoofing attacks, posing significant challenges for automatic speaker verification systems. While systems based on self-supervised learning (SSL) models, particularly the XLSR-Conformer model, have demonstrated remarkable performance in synthetic speech detection, there remains room for architectural improvements. In this paper, we propose a novel approach that replaces the traditional Multi-Layer Perceptron in the XLSR-Conformer model with a Kolmogorov-Arnold Network (KAN), a novel architecture based on the Kolmogorov-Arnold representation theorem. Our results on ASVspoof2021 demonstrate that integrating KAN into the SSL-based models can improve the performance by 60.55% relatively on LA and DF sets, further achieving 0.70% EER on the 21LA set. These findings suggest that incorporating KAN into SSL-based models is a promising direction for advances in synthetic speech detection.
Continuous Learning of Transformer-based Audio Deepfake Detection
Sep 09, 2024



This paper proposes a novel framework for audio deepfake detection with two main objectives: i) attaining the highest possible accuracy on available fake data, and ii) effectively performing continuous learning on new fake data in a few-shot learning manner. Specifically, we conduct a large audio deepfake collection using various deep audio generation methods. The data is further enhanced with additional augmentation methods to increase variations amidst compressions, far-field recordings, noise, and other distortions. We then adopt the Audio Spectrogram Transformer for the audio deepfake detection model. Accordingly, the proposed method achieves promising performance on various benchmark datasets. Furthermore, we present a continuous learning plugin module to update the trained model most effectively with the fewest possible labeled data points of the new fake type. The proposed method outperforms the conventional direct fine-tuning approach with much fewer labeled data points.
I4U Submission to NIST SRE 2018: Leveraging from a Decade of Shared Experiences
Apr 16, 2019
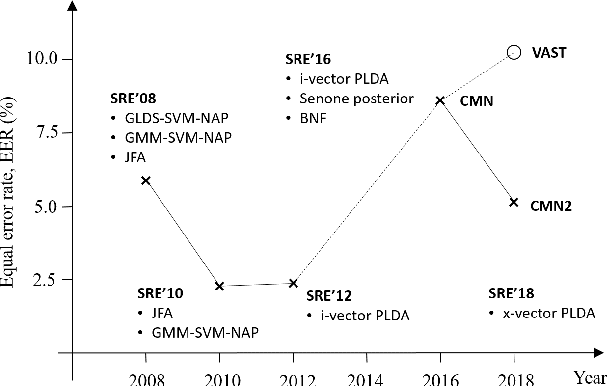
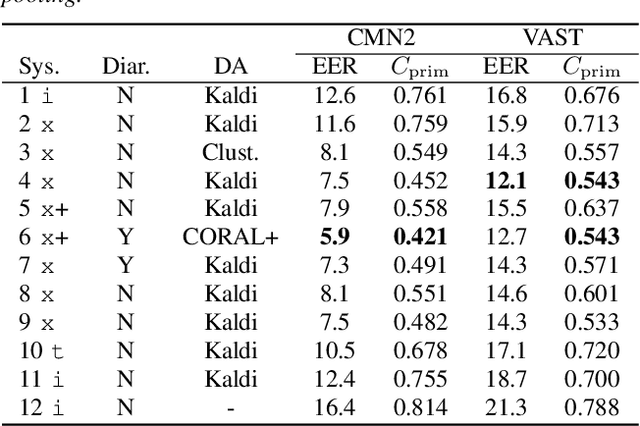
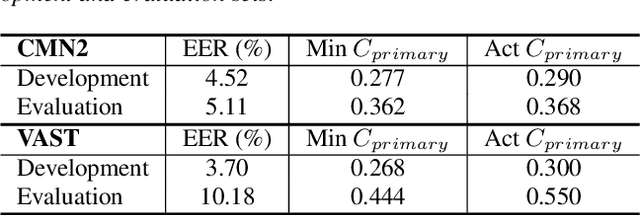
The I4U consortium was established to facilitate a joint entry to NIST speaker recognition evaluations (SRE). The latest edition of such joint submission was in SRE 2018, in which the I4U submission was among the best-performing systems. SRE'18 also marks the 10-year anniversary of I4U consortium into NIST SRE series of evaluation. The primary objective of the current paper is to summarize the results and lessons learned based on the twelve sub-systems and their fusion submitted to SRE'18. It is also our intention to present a shared view on the advancements, progresses, and major paradigm shifts that we have witnessed as an SRE participant in the past decade from SRE'08 to SRE'18. In this regard, we have seen, among others, a paradigm shift from supervector representation to deep speaker embedding, and a switch of research challenge from channel compensation to domain adaptation.