 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompletely Unsupervised Phoneme Recognition by Adversarially Learning Mapping Relationships from Audio Embeddings
Apr 01, 2018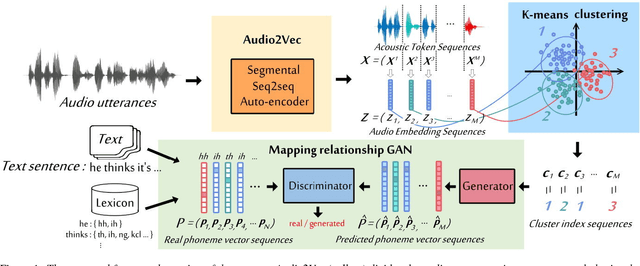

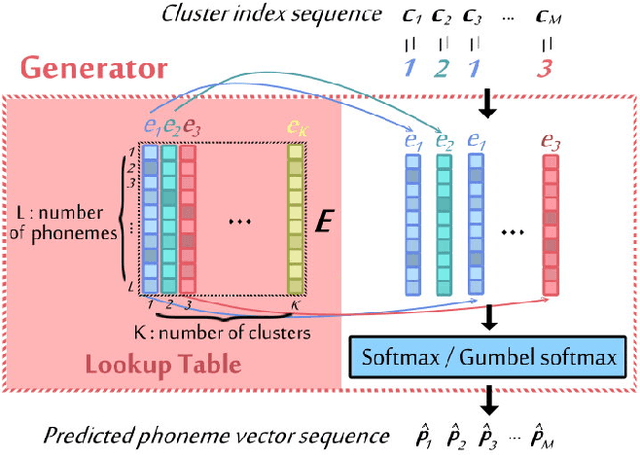
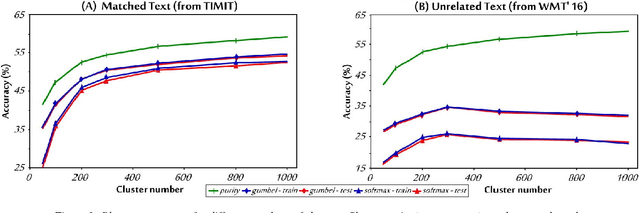
Unsupervised discovery of acoustic tokens from audio corpora without annotation and learning vector representations for these tokens have been widely studied. Although these techniques have been shown successful in some applications such as query-by-example Spoken Term Detection (STD), the lack of mapping relationships between these discovered tokens and real phonemes have limited the down-stream applications. This paper represents probably the first attempt towards the goal of completely unsupervised phoneme recognition, or mapping audio signals to phoneme sequences without phoneme-labeled audio data. The basic idea is to cluster the embedded acoustic tokens and learn the mapping between the cluster sequences and the unknown phoneme sequences with a Generative Adversarial Network (GAN). An unsupervised phoneme recognition accuracy of 36% was achieved in the preliminary experiments.
Mitigating the Impact of Speech Recognition Errors on Chatbot using Sequence-to-Sequence Model
Dec 02, 2017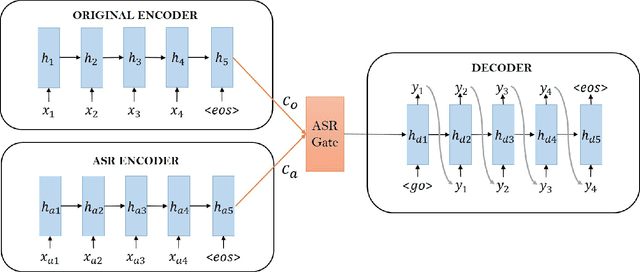

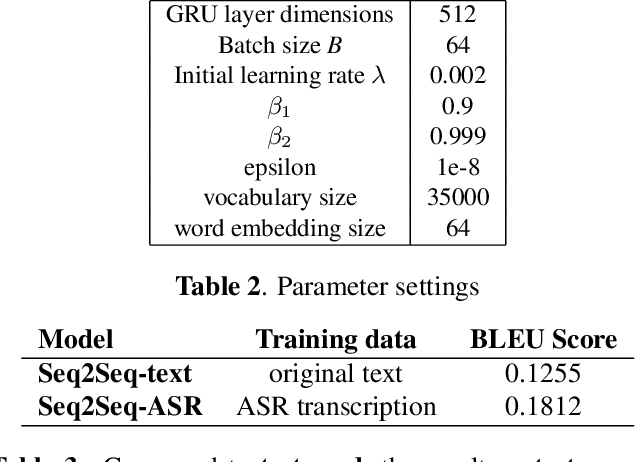
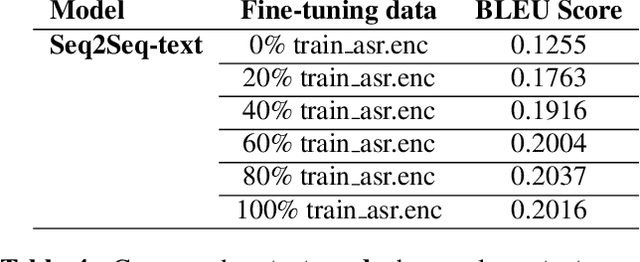
We apply sequence-to-sequence model to mitigate the impact of speech recognition errors on open domain end-to-end dialog generation. We cast the task as a domain adaptation problem where ASR transcriptions and original text are in two different domains. In this paper, our proposed model includes two individual encoders for each domain data and make their hidden states similar to ensure the decoder predict the same dialog text. The method shows that the sequence-to-sequence model can learn the ASR transcriptions and original text pair having the same meaning and eliminate the speech recognition errors. Experimental results on Cornell movie dialog dataset demonstrate that the domain adaption system help the spoken dialog system generate more similar responses with the original text answers.
Order-Preserving Abstractive Summarization for Spoken Content Based on Connectionist Temporal Classification
Nov 16, 2017

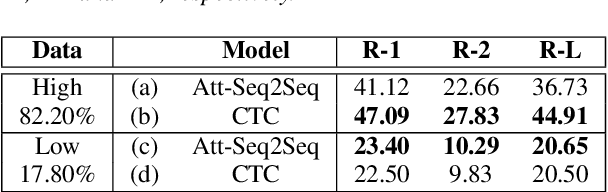
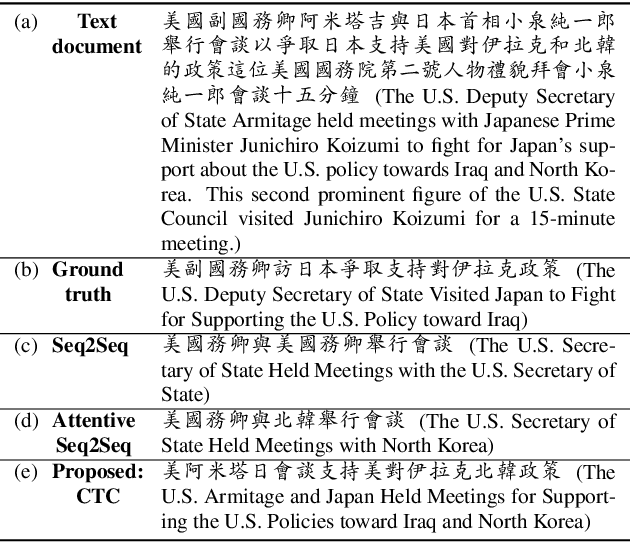
Connectionist temporal classification (CTC) is a powerful approach for sequence-to-sequence learning, and has been popularly used in speech recognition. The central ideas of CTC include adding a label "blank" during training. With this mechanism, CTC eliminates the need of segment alignment, and hence has been applied to various sequence-to-sequence learning problems. In this work, we applied CTC to abstractive summarization for spoken content. The "blank" in this case implies the corresponding input data are less important or noisy; thus it can be ignored. This approach was shown to outperform the existing methods in term of ROUGE scores over Chinese Gigaword and MATBN corpora. This approach also has the nice property that the ordering of words or characters in the input documents can be better preserved in the generated summaries.
Personalized word representations Carrying Personalized Semantics Learned from Social Network Posts
Oct 29, 2017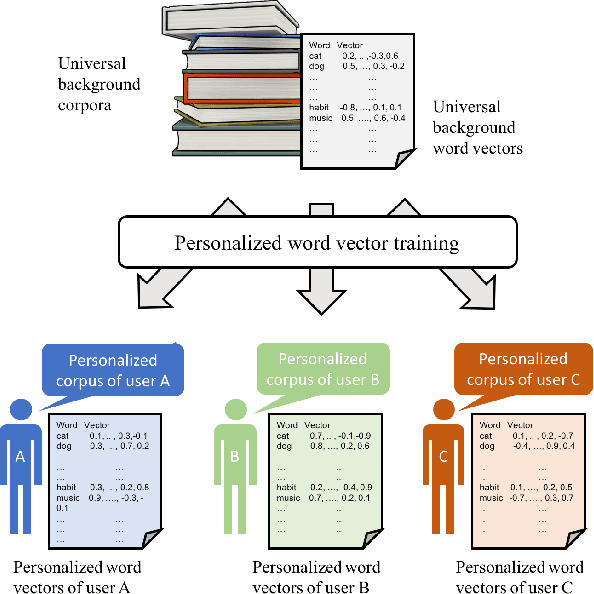
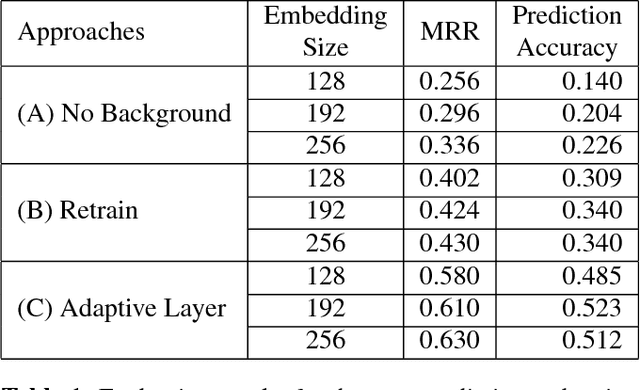
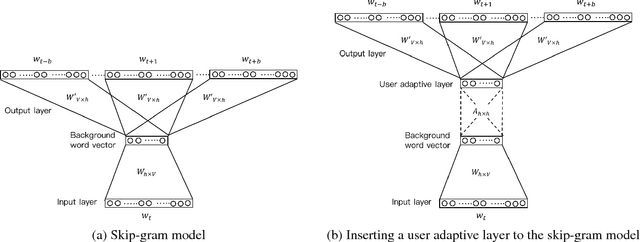
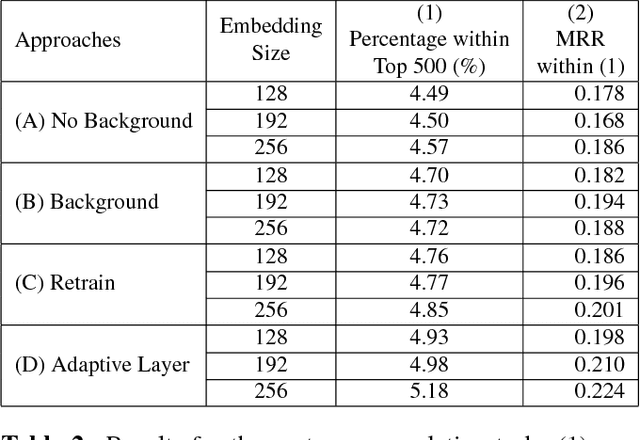
Distributed word representations have been shown to be very useful in various natural language processing (NLP) application tasks. These word vectors learned from huge corpora very often carry both semantic and syntactic information of words. However, it is well known that each individual user has his own language patterns because of different factors such as interested topics, friend groups, social activities, wording habits, etc., which may imply some kind of personalized semantics. With such personalized semantics, the same word may imply slightly differently for different users. For example, the word "Cappuccino" may imply "Leisure", "Joy", "Excellent" for a user enjoying coffee, by only a kind of drink for someone else. Such personalized semantics of course cannot be carried by the standard universal word vectors trained with huge corpora produced by many people. In this paper, we propose a framework to train different personalized word vectors for different users based on the very successful continuous skip-gram model using the social network data posted by many individual users. In this framework, universal background word vectors are first learned from the background corpora, and then adapted by the personalized corpus for each individual user to learn the personalized word vectors. We use two application tasks to evaluate the quality of the personalized word vectors obtained in this way, the user prediction task and the sentence completion task. These personalized word vectors were shown to carry some personalized semantics and offer improved performance on these two evaluation tasks.
Query-based Attention CNN for Text Similarity Map
Oct 18, 2017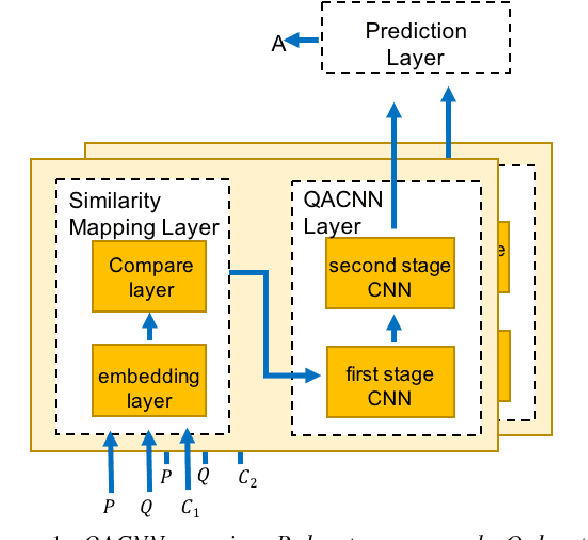
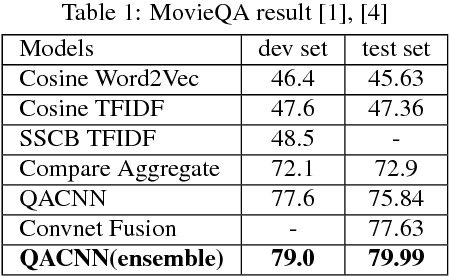
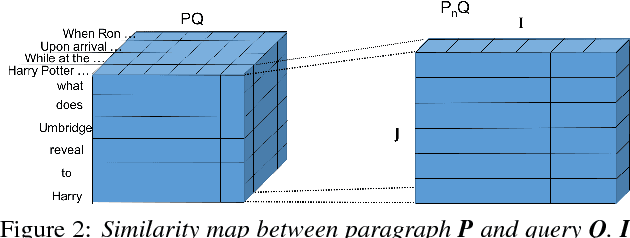
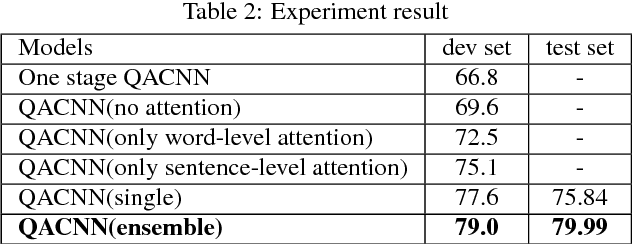
In this paper, we introduce Query-based Attention CNN(QACNN) for Text Similarity Map, an end-to-end neural network for question answering. This network is composed of compare mechanism, two-staged CNN architecture with attention mechanism, and a prediction layer. First, the compare mechanism compares between the given passage, query, and multiple answer choices to build similarity maps. Then, the two-staged CNN architecture extracts features through word-level and sentence-level. At the same time, attention mechanism helps CNN focus more on the important part of the passage based on the query information. Finally, the prediction layer find out the most possible answer choice. We conduct this model on the MovieQA dataset using Plot Synopses only, and achieve 79.99% accuracy which is the state of the art on the dataset.
Learning Chinese Word Representations From Glyphs Of Characters
Aug 16, 2017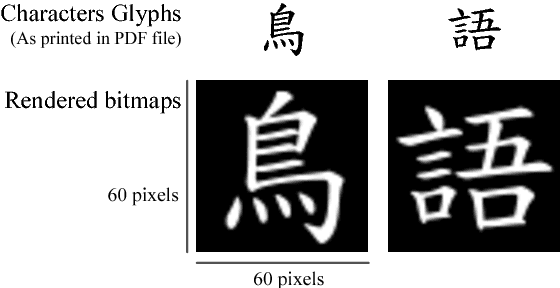
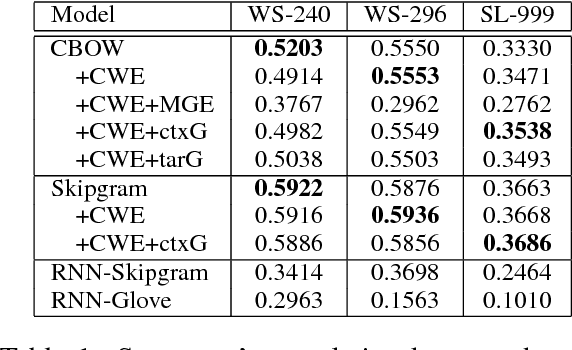
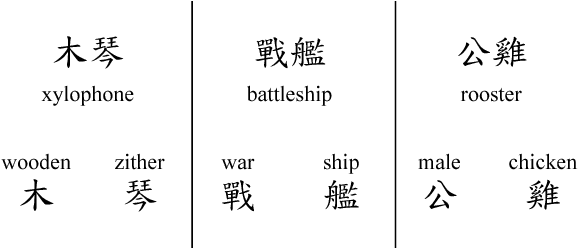
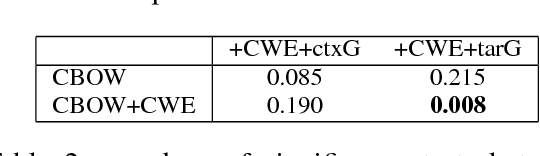
In this paper, we propose new methods to learn Chinese word representations. Chinese characters are composed of graphical components, which carry rich semantics. It is common for a Chinese learner to comprehend the meaning of a word from these graphical components. As a result, we propose models that enhance word representations by character glyphs. The character glyph features are directly learned from the bitmaps of characters by convolutional auto-encoder(convAE), and the glyph features improve Chinese word representations which are already enhanced by character embeddings. Another contribution in this paper is that we created several evaluation datasets in traditional Chinese and made them public.
Language Transfer of Audio Word2Vec: Learning Audio Segment Representations without Target Language Data
Jul 19, 2017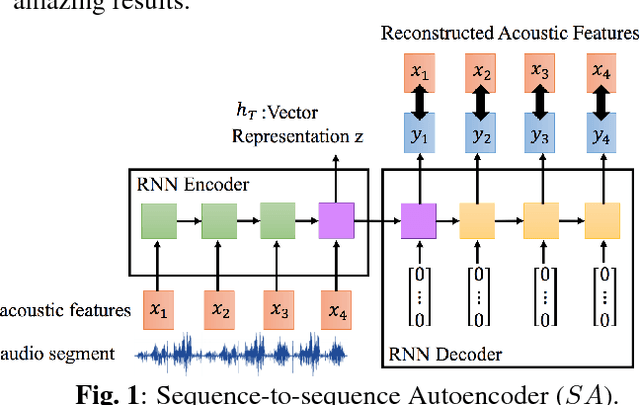
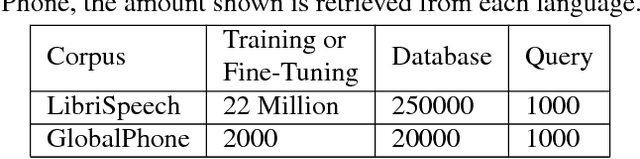
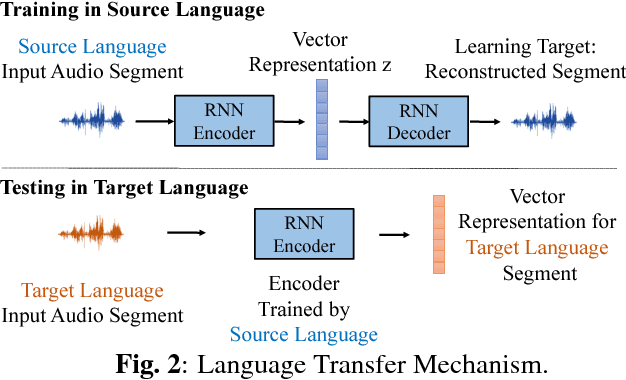
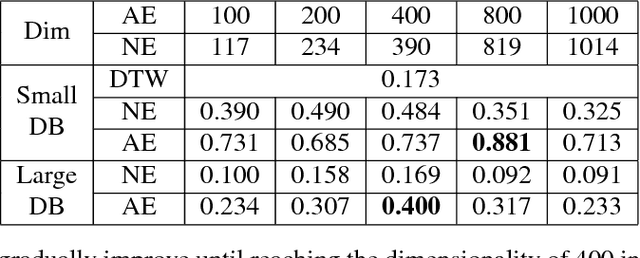
Audio Word2Vec offers vector representations of fixed dimensionality for variable-length audio segments using Sequence-to-sequence Autoencoder (SA). These vector representations are shown to describe the sequential phonetic structures of the audio segments to a good degree, with real world applications such as query-by-example Spoken Term Detection (STD). This paper examines the capability of language transfer of Audio Word2Vec. We train SA from one language (source language) and use it to extract the vector representation of the audio segments of another language (target language). We found that SA can still catch phonetic structure from the audio segments of the target language if the source and target languages are similar. In query-by-example STD, we obtain the vector representations from the SA learned from a large amount of source language data, and found them surpass the representations from naive encoder and SA directly learned from a small amount of target language data. The result shows that it is possible to learn Audio Word2Vec model from high-resource languages and use it on low-resource languages. This further expands the usability of Audio Word2Vec.
Personalizing Universal Recurrent Neural Network Language Model with User Characteristic Features by Social Network Crowdsouring
Nov 22, 2016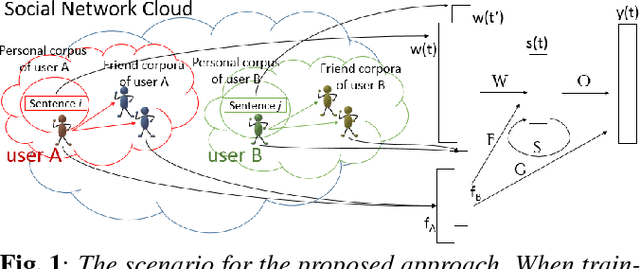

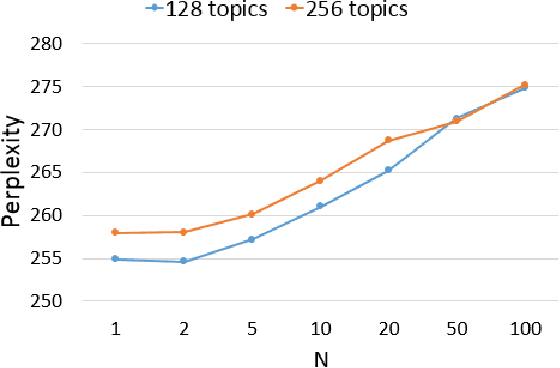
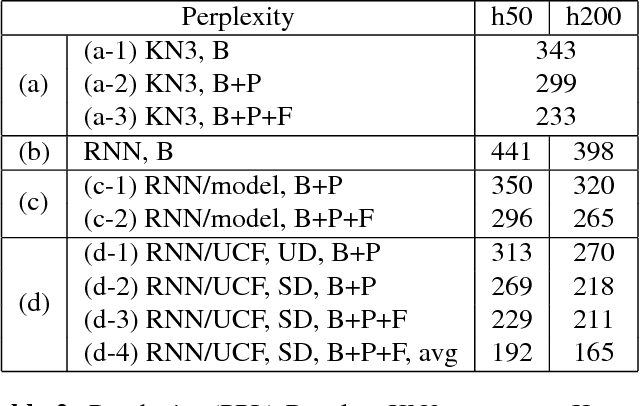
With the popularity of mobile devices, personalized speech recognizer becomes more realizable today and highly attractive. Each mobile device is primarily used by a single user, so it's possible to have a personalized recognizer well matching to the characteristics of individual user. Although acoustic model personalization has been investigated for decades, much less work have been reported on personalizing language model, probably because of the difficulties in collecting enough personalized corpora. Previous work used the corpora collected from social networks to solve the problem, but constructing a personalized model for each user is troublesome. In this paper, we propose a universal recurrent neural network language model with user characteristic features, so all users share the same model, except each with different user characteristic features. These user characteristic features can be obtained by crowdsouring over social networks, which include huge quantity of texts posted by users with known friend relationships, who may share some subject topics and wording patterns. The preliminary experiments on Facebook corpus showed that this proposed approach not only drastically reduced the model perplexity, but offered very good improvement in recognition accuracy in n-best rescoring tests. This approach also mitigated the data sparseness problem for personalized language models.
Interactive Spoken Content Retrieval by Deep Reinforcement Learning
Sep 16, 2016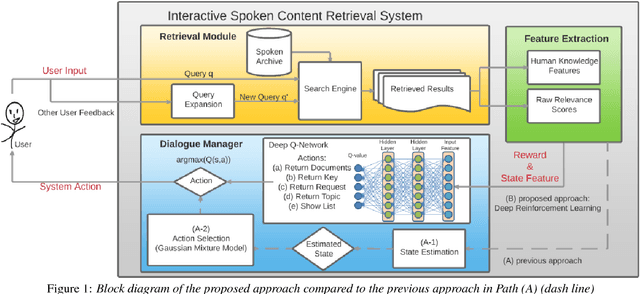
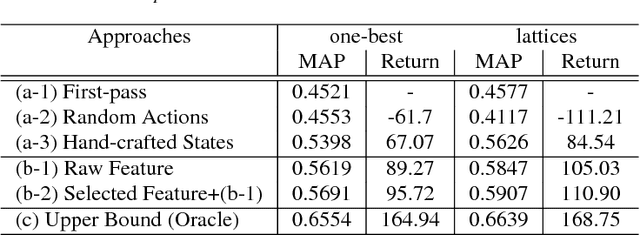
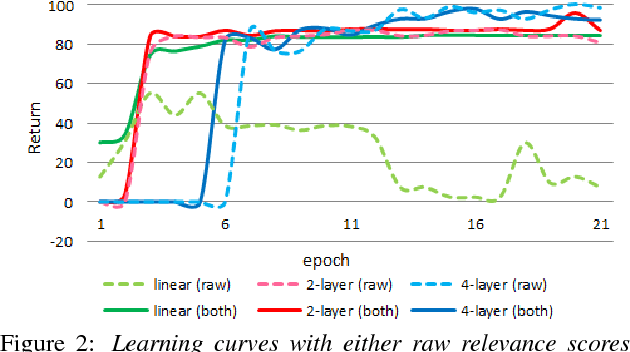
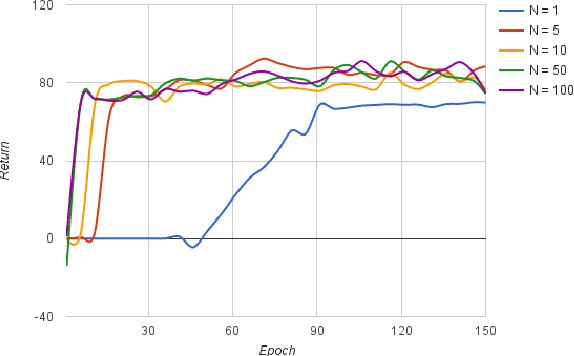
User-machine interaction is important for spoken content retrieval. For text content retrieval, the user can easily scan through and select on a list of retrieved item. This is impossible for spoken content retrieval, because the retrieved items are difficult to show on screen. Besides, due to the high degree of uncertainty for speech recognition, the retrieval results can be very noisy. One way to counter such difficulties is through user-machine interaction. The machine can take different actions to interact with the user to obtain better retrieval results before showing to the user. The suitable actions depend on the retrieval status, for example requesting for extra information from the user, returning a list of topics for user to select, etc. In our previous work, some hand-crafted states estimated from the present retrieval results are used to determine the proper actions. In this paper, we propose to use Deep-Q-Learning techniques instead to determine the machine actions for interactive spoken content retrieval. Deep-Q-Learning bypasses the need for estimation of the hand-crafted states, and directly determine the best action base on the present retrieval status even without any human knowledge. It is shown to achieve significantly better performance compared with the previous hand-crafted states.
Towards Machine Comprehension of Spoken Content: Initial TOEFL Listening Comprehension Test by Machine
Aug 23, 2016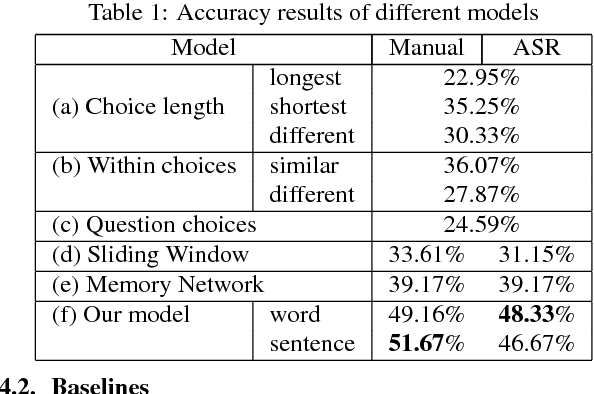
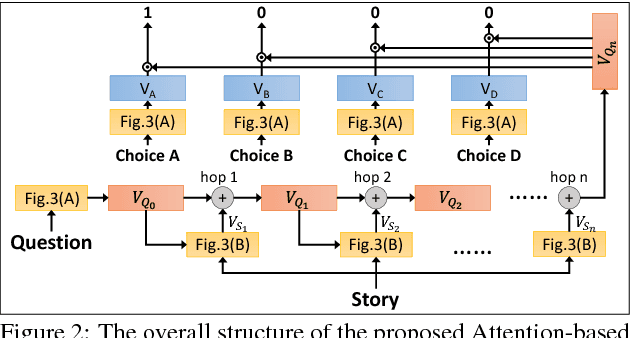
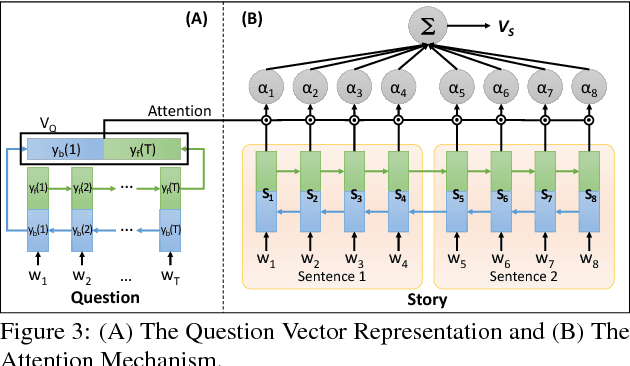

Multimedia or spoken content presents more attractive information than plain text content, but it's more difficult to display on a screen and be selected by a user. As a result, accessing large collections of the former is much more difficult and time-consuming than the latter for humans. It's highly attractive to develop a machine which can automatically understand spoken content and summarize the key information for humans to browse over. In this endeavor, we propose a new task of machine comprehension of spoken content. We define the initial goal as the listening comprehension test of TOEFL, a challenging academic English examination for English learners whose native language is not English. We further propose an Attention-based Multi-hop Recurrent Neural Network (AMRNN) architecture for this task, achieving encouraging results in the initial tests. Initial results also have shown that word-level attention is probably more robust than sentence-level attention for this task with ASR errors.