 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifiable Deep Latent Variable Models for MNAR Data
Mar 27, 2026Missing data is a ubiquitous challenge in data analysis, often leading to biased and inaccurate results. Traditional imputation methods usually assume that the missingness mechanism is missing-at-random (MAR), where the missingness is independent of the missing values themselves. This assumption is frequently violated in real-world scenarios, prompted by recent advances in imputation methods using deep learning to address this challenge. However, these methods neglect the crucial issue of nonparametric identifiability in missing-not-at-random (MNAR) data, which can lead to biased and unreliable results. This paper seeks to bridge this gap by proposing a novel framework based on deep latent variable models for MNAR data. Building on the assumption of conditional no self-censoring given latent variables, we establish the identifiability of the data distribution. This crucial theoretical result guarantees the feasibility of our approach. To effectively estimate unknown parameters, we develop an efficient algorithm utilizing importance-weighted autoencoders. We demonstrate, both theoretically and empirically, that our estimation process accurately recovers the ground-truth joint distribution under specific regularity conditions. Extensive simulation studies and real-world data experiments showcase the advantages of our proposed method compared to various classical and state-of-the-art approaches to missing data imputation.
Meta Learning for High-dimensional Ising Model Selection Using $\ell_1$-regularized Logistic Regression
Aug 19, 2022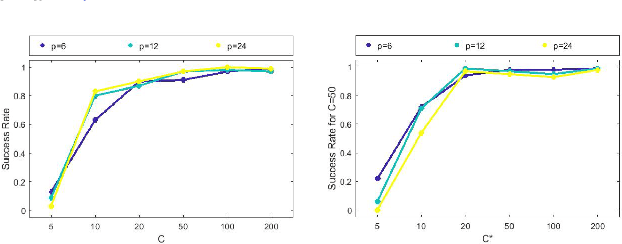



In this paper, we consider the meta learning problem for estimating the graphs associated with high-dimensional Ising models, using the method of $\ell_1$-regularized logistic regression for neighborhood selection of each node. Our goal is to use the information learned from the auxiliary tasks in the learning of the novel task to reduce its sufficient sample complexity. To this end, we propose a novel generative model as well as an improper estimation method. In our setting, all the tasks are \emph{similar} in their \emph{random} model parameters and supports. By pooling all the samples from the auxiliary tasks to \emph{improperly} estimate a single parameter vector, we can recover the true support union, assumed small in size, with a high probability with a sufficient sample complexity of $\Omega(1) $ per task, for $K = \Omega(d^3 \log p ) $ tasks of Ising models with $p$ nodes and a maximum neighborhood size $d$. Then, with the support for the novel task restricted to the estimated support union, we prove that consistent neighborhood selection for the novel task can be obtained with a reduced sufficient sample complexity of $\Omega(d^3 \log d)$.