 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiftAvatar: Kinematic-Space Completion for Expression-Controlled 3D Gaussian Avatar Animation
Mar 02, 2026We present LiftAvatar, a new paradigm that completes sparse monocular observations in kinematic space (e.g., facial expressions and head pose) and uses the completed signals to drive high-fidelity avatar animation. LiftAvatar is a fine-grained, expression-controllable large-scale video diffusion Transformer that synthesizes high-quality, temporally coherent expression sequences conditioned on single or multiple reference images. The key idea is to lift incomplete input data into a richer kinematic representation, thereby strengthening both reconstruction and animation in downstream 3D avatar pipelines. To this end, we introduce (i) a multi-granularity expression control scheme that combines shading maps with expression coefficients for precise and stable driving, and (ii) a multi-reference conditioning mechanism that aggregates complementary cues from multiple frames, enabling strong 3D consistency and controllability. As a plug-and-play enhancer, LiftAvatar directly addresses the limited expressiveness and reconstruction artifacts of 3D Gaussian Splatting-based avatars caused by sparse kinematic cues in everyday monocular videos. By expanding incomplete observations into diverse pose-expression variations, LiftAvatar also enables effective prior distillation from large-scale video generative models into 3D pipelines, leading to substantial gains. Extensive experiments show that LiftAvatar consistently boosts animation quality and quantitative metrics of state-of-the-art 3D avatar methods, especially under extreme, unseen expressions.
PRG: Prompt-Based Distillation Without Annotation via Proxy Relational Graph
Aug 22, 2024



In this paper, we propose a new distillation method for extracting knowledge from Large Foundation Models (LFM) into lightweight models, introducing a novel supervision mode that does not require manually annotated data. While LFMs exhibit exceptional zero-shot classification abilities across datasets, relying solely on LFM-generated embeddings for distillation poses two main challenges: LFM's task-irrelevant knowledge and the high density of features. The transfer of task-irrelevant knowledge could compromise the student model's discriminative capabilities, and the high density of features within target domains obstructs the extraction of discriminative knowledge essential for the task. To address this issue, we introduce the Proxy Relational Graph (PRG) method. We initially extract task-relevant knowledge from LFMs by calculating a weighted average of logits obtained through text prompt embeddings. Then we construct sample-class proxy graphs for LFM and student models, respectively, to model the correlation between samples and class proxies. Then, we achieve the distillation of selective knowledge by aligning the relational graphs produced by both the LFM and the student model. Specifically, the distillation from LFM to the student model is achieved through two types of alignment: 1) aligning the sample nodes produced by the student model with those produced by the LFM, and 2) aligning the edge relationships in the student model's graph with those in the LFM's graph. Our experimental results validate the effectiveness of PRG, demonstrating its ability to leverage the extensive knowledge base of LFMs while skillfully circumventing their inherent limitations in focused learning scenarios. Notably, in our annotation-free framework, PRG achieves an accuracy of 76.23\% (T: 77.9\%) on CIFAR-100 and 72.44\% (T: 75.3\%) on the ImageNet-1K.
SimpleTrack: Rethinking and Improving the JDE Approach for Multi-Object Tracking
Mar 08, 2022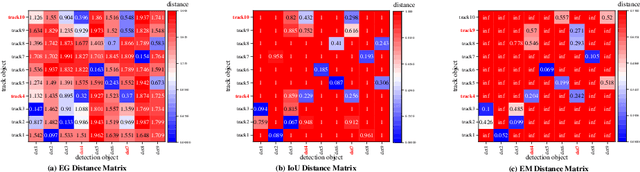



Joint detection and embedding (JDE) based methods usually estimate bounding boxes and embedding features of objects with a single network in Multi-Object Tracking (MOT). In the tracking stage, JDE-based methods fuse the target motion information and appearance information by applying the same rule, which could fail when the target is briefly lost or blocked. To overcome this problem, we propose a new association matrix, the Embedding and Giou matrix, which combines embedding cosine distance and Giou distance of objects. To further improve the performance of data association, we develop a simple, effective tracker named SimpleTrack, which designs a bottom-up fusion method for Re-identity and proposes a new tracking strategy based on our EG matrix. The experimental results indicate that SimpleTrack has powerful data association capability, e.g., 61.6 HOTA and 76.3 IDF1 on MOT17. In addition, we apply the EG matrix to 5 different state-of-the-art JDE-based methods and achieve significant improvements in IDF1, HOTA and IDsw metrics, and increase the tracking speed of these methods by about 20%.