 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain2Vec: Vectorizing Datasets to Find the Optimal Data Mixture without Training
Jun 12, 2025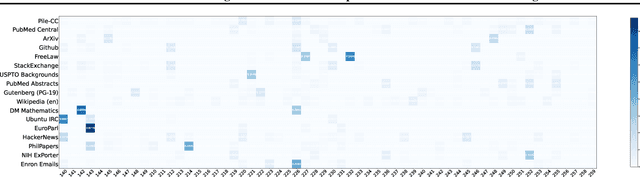
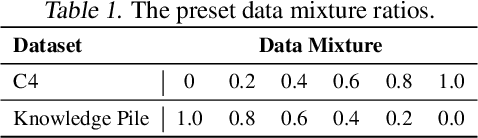

We introduce~\textsc{Domain2Vec}, a novel approach that decomposes any dataset into a linear combination of several \emph{meta-domains}, a new concept designed to capture the key underlying features of datasets. \textsc{Domain2Vec} maintains a vocabulary of meta-domains and uses a classifier to decompose any given dataset into a domain vector that corresponds to a distribution over this vocabulary. These domain vectors enable the identification of the optimal data mixture for language model (LM) pretraining in a training-free manner under the \emph{\textbf{D}istribution \textbf{A}lignment \textbf{A}ssumption} (DA$^{2}$), which suggests that when the data distributions of the training set and the validation set are better aligned, a lower validation loss is achieved. Moreover, \textsc{Domain2vec} can be seamlessly integrated into previous works to model the relationship between domain vectors and LM performance, greatly enhancing the efficiency and scalability of previous methods. Extensive experiments demonstrate that \textsc{Domain2Vec} helps find the data mixture that enhances downstream task performance with minimal computational overhead. Specifically, \textsc{Domain2Vec} achieves the same validation loss on Pile-CC using only $51.5\%$ of the computation required when training on the original mixture of The Pile dataset. Under equivalent compute budget, \textsc{Domain2Vec} improves downstream performance by an average of $2.83\%$.
Learning Dynamics in Continual Pre-Training for Large Language Models
May 12, 2025Continual Pre-Training (CPT) has become a popular and effective method to apply strong foundation models to specific downstream tasks. In this work, we explore the learning dynamics throughout the CPT process for large language models. We specifically focus on how general and downstream domain performance evolves at each training step, with domain performance measured via validation losses. We have observed that the CPT loss curve fundamentally characterizes the transition from one curve to another hidden curve, and could be described by decoupling the effects of distribution shift and learning rate annealing. We derive a CPT scaling law that combines the two factors, enabling the prediction of loss at any (continual) training steps and across learning rate schedules (LRS) in CPT. Our formulation presents a comprehensive understanding of several critical factors in CPT, including loss potential, peak learning rate, training steps, replay ratio, etc. Moreover, our approach can be adapted to customize training hyper-parameters to different CPT goals such as balancing general and domain-specific performance. Extensive experiments demonstrate that our scaling law holds across various CPT datasets and training hyper-parameters.
Scaling Law with Learning Rate Annealing
Aug 20, 2024



We find that the cross-entropy loss curves of neural language models empirically adhere to a scaling law with learning rate (LR) annealing over training steps ($s$): $$L(s) = L_0 + A\cdot S_1^{-\alpha} - C\cdot S_2$$ Where $S_1$ is forward area and $S_2$ is learning rate annealing area. This formulation takes into account two factors: (1) The forward scaling defined as typical scaling law, and (2) the additional loss drop brought by LR annealing. Therefore, this formulation can describe the full loss curve at each step, rather than the single loss point at the end of training. Applying the scaling law with LR annealing and fitting only one or two training curves, we can accurately predict the loss of language model training at any given step and across any learning rate scheduler (LRS). Furthermore, this equation accurately describes the dynamics during training process, and provides a theoretical verification and explanation for numerous experimental findings of previous studies, particularly those focusing on LR schedule and LR annealing. The resulting insights, also serve as a guide for researchers to select critical LRS in advance by prediction using our equation. Most significantly, since all the points in a full training curve follow the equation, we can achieve accurate loss prediction at any given step across any learning rate scheduler, while expending less than 1\% of the computational cost required by the chinchilla scaling law to fit language modeling loss. This approach extremely democratizes scaling law fitting and predicting in developing large language models.