 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDEER: A Comprehensive and Reliable Benchmark for Deep-Research Expert Reports
Dec 19, 2025As large language models (LLMs) advance, deep research systems can generate expert-level reports via multi-step reasoning and evidence-based synthesis, but evaluating such reports remains challenging. Existing benchmarks often lack systematic criteria for expert reporting, evaluations that rely heavily on LLM judges can fail to capture issues that require expert judgment, and source verification typically covers only a limited subset of explicitly cited statements rather than report-wide factual reliability. We introduce DEER, a benchmark for evaluating expert-level deep research reports. DEER comprises 50 report-writing tasks spanning 13 domains and an expert-grounded evaluation taxonomy (7 dimensions, 25 sub-dimension) operationalized into 130 fine-grained rubric items. DEER further provides task-specific expert guidance to help LLM judges assess expert-level report quality more consistently. Complementing rubric-based assessment, we propose a document-level fact-checking architecture that extracts and verifies all claims across the entire report, including both cited and uncited ones, and quantifies external-evidence quality. DEER correlates closely with human expert judgments and yields interpretable diagnostics of system strengths and weaknesses.
KL Penalty Control via Perturbation for Direct Preference Optimization
Feb 18, 2025



Direct Preference Optimization (DPO) demonstrates the advantage of aligning a large language model with human preference using only an offline dataset. However, DPO has the limitation that the KL penalty, which prevents excessive deviation from the reference model, is static throughout the training process. Several methods try to turn this static KL penalty into a dynamic one, but no approach can adaptively assign different KL penalties for each preference pair. In this paper, we propose $\varepsilon$-Direct Preference Optimization ($\varepsilon$-DPO), which allows adaptive control of the KL penalty strength $\beta$ for each preference pair. Specifically, $\varepsilon$-DPO adaptively controls $\beta$ for each preference pair based on the monotonicity of logits as a preference model under the perturbation of $\beta$ during training by simply reusing the logit of the current policy and the reference policy. Experimental results show that $\varepsilon$-DPO outperforms existing direct alignment algorithms and KL penalty relaxation methods on general chatbot benchmarks, highlighting the significance of adaptive KL penalty relaxation at the instance-level in DPO.
External Knowledge Selection with Weighted Negative Sampling in Knowledge-grounded Task-oriented Dialogue Systems
Sep 06, 2022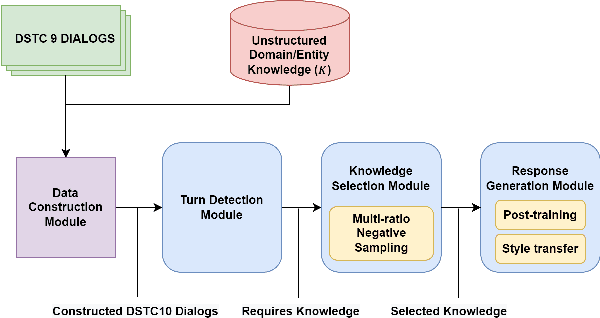


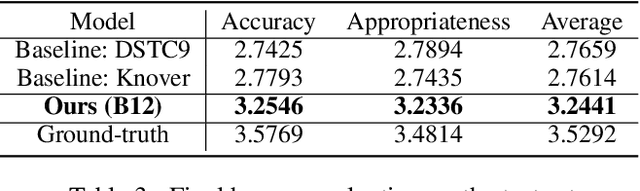
Constructing a robust dialogue system on spoken conversations bring more challenge than written conversation. In this respect, DSTC10-Track2-Task2 is proposed, which aims to build a task-oriented dialogue (TOD) system incorporating unstructured external knowledge on a spoken conversation, extending DSTC9-Track1. This paper introduces our system containing four advanced methods: data construction, weighted negative sampling, post-training, and style transfer. We first automatically construct a large training data because DSTC10-Track2 does not release the official training set. For the knowledge selection task, we propose weighted negative sampling to train the model more fine-grained manner. We also employ post-training and style transfer for the response generation task to generate an appropriate response with a similar style to the target response. In the experiment, we investigate the effect of weighted negative sampling, post-training, and style transfer. Our model ranked 7 out of 16 teams in the objective evaluation and 6 in human evaluation.