 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOVID-Net CXR-S: Deep Convolutional Neural Network for Severity Assessment of COVID-19 Cases from Chest X-ray Images
May 01, 2021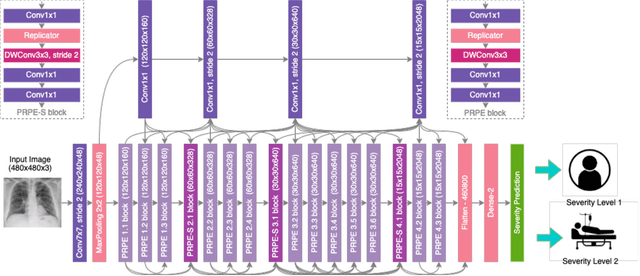
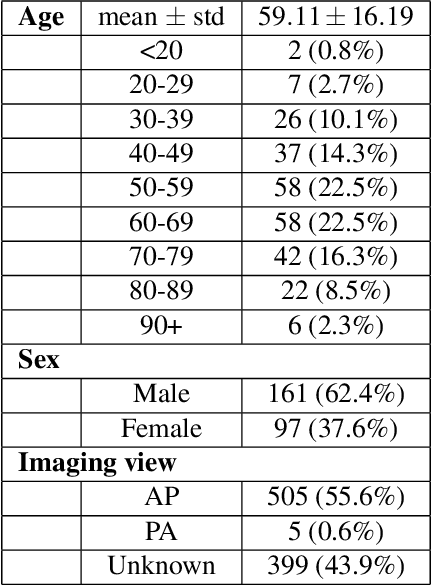
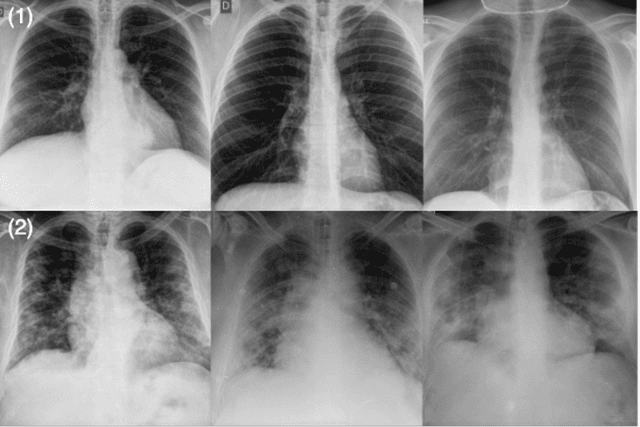
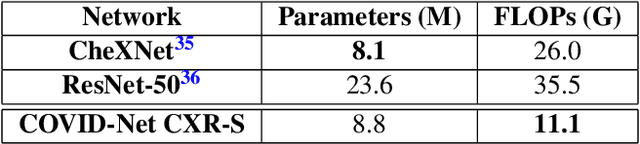
The world is still struggling in controlling and containing the spread of the COVID-19 pandemic caused by the SARS-CoV-2 virus. The medical conditions associated with SARS-CoV-2 infections have resulted in a surge in the number of patients at clinics and hospitals, leading to a significantly increased strain on healthcare resources. As such, an important part of managing and handling patients with SARS-CoV-2 infections within the clinical workflow is severity assessment, which is often conducted with the use of chest x-ray (CXR) images. In this work, we introduce COVID-Net CXR-S, a convolutional neural network for predicting the airspace severity of a SARS-CoV-2 positive patient based on a CXR image of the patient's chest. More specifically, we leveraged transfer learning to transfer representational knowledge gained from over 16,000 CXR images from a multinational cohort of over 15,000 patient cases into a custom network architecture for severity assessment. Experimental results with a multi-national patient cohort curated by the Radiological Society of North America (RSNA) RICORD initiative showed that the proposed COVID-Net CXR-S has potential to be a powerful tool for computer-aided severity assessment of CXR images of COVID-19 positive patients. Furthermore, radiologist validation on select cases by two board-certified radiologists with over 10 and 19 years of experience, respectively, showed consistency between radiologist interpretation and critical factors leveraged by COVID-Net CXR-S for severity assessment. While not a production-ready solution, the ultimate goal for the open source release of COVID-Net CXR-S is to act as a catalyst for clinical scientists, machine learning researchers, as well as citizen scientists to develop innovative new clinical decision support solutions for helping clinicians around the world manage the continuing pandemic.
Locally Persistent Exploration in Continuous Control Tasks with Sparse Rewards
Dec 26, 2020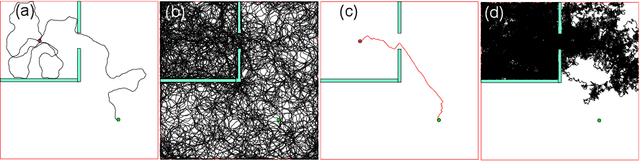
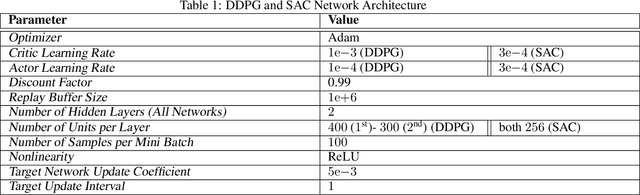
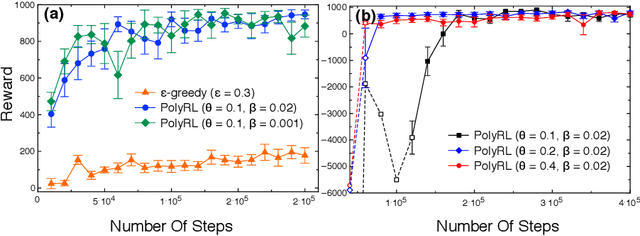
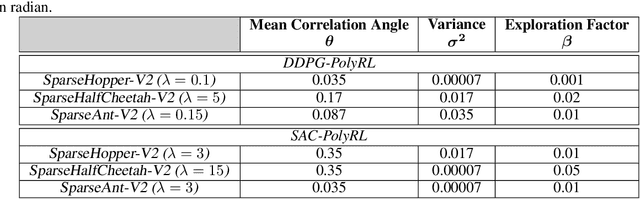
A major challenge in reinforcement learning is the design of exploration strategies, especially for environments with sparse reward structures and continuous state and action spaces. Intuitively, if the reinforcement signal is very scarce, the agent should rely on some form of short-term memory in order to cover its environment efficiently. We propose a new exploration method, based on two intuitions: (1) the choice of the next exploratory action should depend not only on the (Markovian) state of the environment, but also on the agent's trajectory so far, and (2) the agent should utilize a measure of spread in the state space to avoid getting stuck in a small region. Our method leverages concepts often used in statistical physics to provide explanations for the behavior of simplified (polymer) chains, in order to generate persistent (locally self-avoiding) trajectories in state space. We discuss the theoretical properties of locally self-avoiding walks, and their ability to provide a kind of short-term memory, through a decaying temporal correlation within the trajectory. We provide empirical evaluations of our approach in a simulated 2D navigation task, as well as higher-dimensional MuJoCo continuous control locomotion tasks with sparse rewards.
Self-Gradient Networks
Nov 19, 2020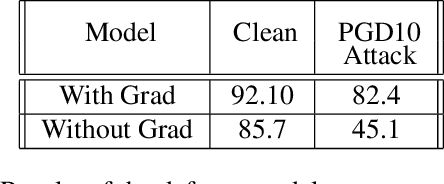
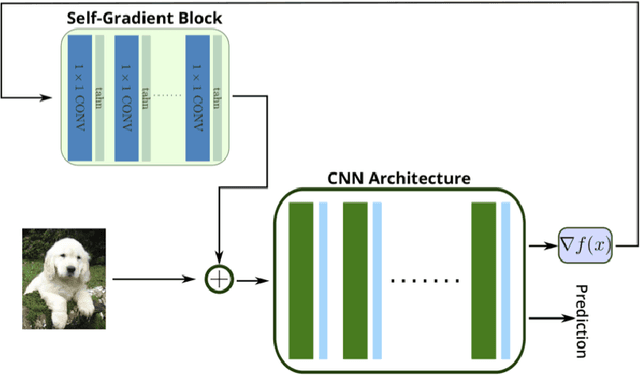
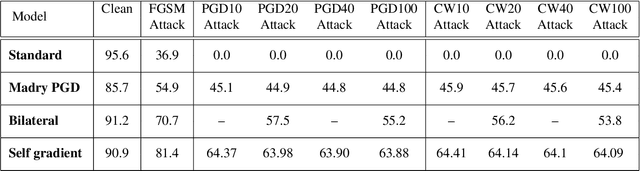
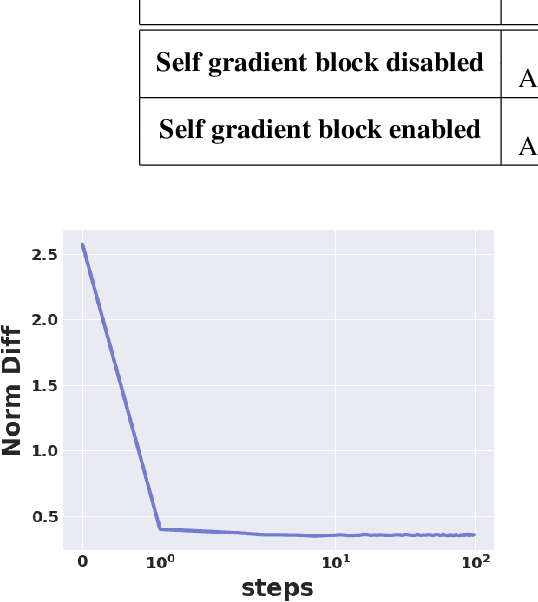
The incredible effectiveness of adversarial attacks on fooling deep neural networks poses a tremendous hurdle in the widespread adoption of deep learning in safety and security-critical domains. While adversarial defense mechanisms have been proposed since the discovery of the adversarial vulnerability issue of deep neural networks, there is a long path to fully understand and address this issue. In this study, we hypothesize that part of the reason for the incredible effectiveness of adversarial attacks is their ability to implicitly tap into and exploit the gradient flow of a deep neural network. This innate ability to exploit gradient flow makes defending against such attacks quite challenging. Motivated by this hypothesis we argue that if a deep neural network architecture can explicitly tap into its own gradient flow during the training, it can boost its defense capability significantly. Inspired by this fact, we introduce the concept of self-gradient networks, a novel deep neural network architecture designed to be more robust against adversarial perturbations. Gradient flow information is leveraged within self-gradient networks to achieve greater perturbation stability beyond what can be achieved in the standard training process. We conduct a theoretical analysis to gain better insights into the behaviour of the proposed self-gradient networks to illustrate the efficacy of leverage this additional gradient flow information. The proposed self-gradient network architecture enables much more efficient and effective adversarial training, leading to faster convergence towards an adversarially robust solution by at least 10X. Experimental results demonstrate the effectiveness of self-gradient networks when compared with state-of-the-art adversarial learning strategies, with 10% improvement on the CIFAR10 dataset under PGD and CW adversarial perturbations.
Vulnerability Under Adversarial Machine Learning: Bias or Variance?
Aug 01, 2020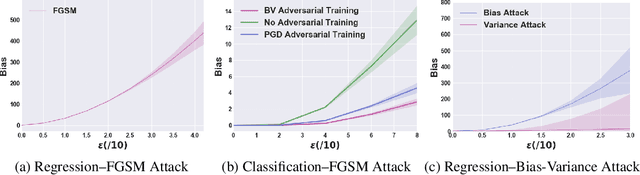
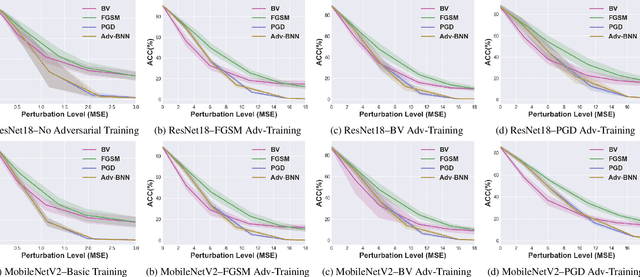
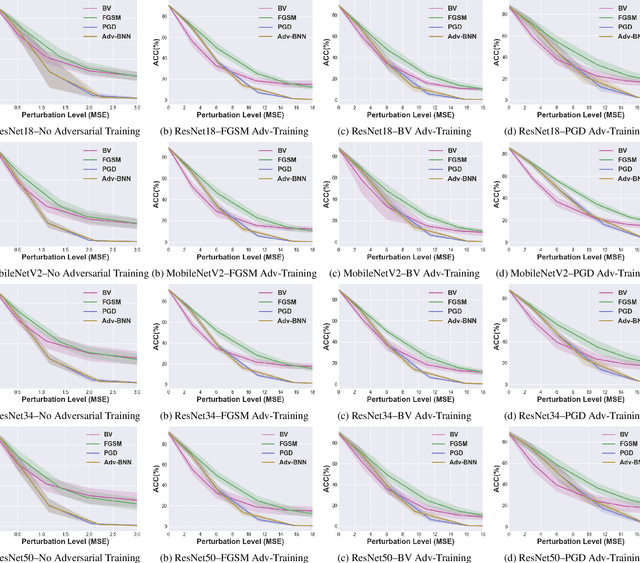
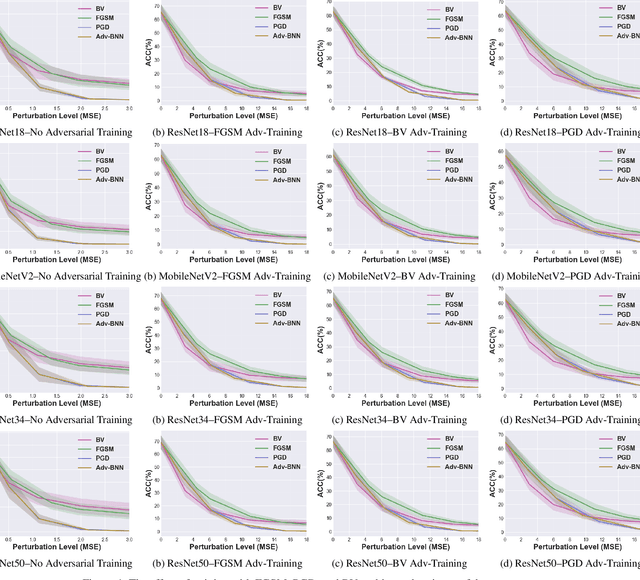
Prior studies have unveiled the vulnerability of the deep neural networks in the context of adversarial machine learning, leading to great recent attention into this area. One interesting question that has yet to be fully explored is the bias-variance relationship of adversarial machine learning, which can potentially provide deeper insights into this behaviour. The notion of bias and variance is one of the main approaches to analyze and evaluate the generalization and reliability of a machine learning model. Although it has been extensively used in other machine learning models, it is not well explored in the field of deep learning and it is even less explored in the area of adversarial machine learning. In this study, we investigate the effect of adversarial machine learning on the bias and variance of a trained deep neural network and analyze how adversarial perturbations can affect the generalization of a network. We derive the bias-variance trade-off for both classification and regression applications based on two main loss functions: (i) mean squared error (MSE), and (ii) cross-entropy. Furthermore, we perform quantitative analysis with both simulated and real data to empirically evaluate consistency with the derived bias-variance tradeoffs. Our analysis sheds light on why the deep neural networks have poor performance under adversarial perturbation from a bias-variance point of view and how this type of perturbation would change the performance of a network. Moreover, given these new theoretical findings, we introduce a new adversarial machine learning algorithm with lower computational complexity than well-known adversarial machine learning strategies (e.g., PGD) while providing a high success rate in fooling deep neural networks in lower perturbation magnitudes.
Learning Modular Safe Policies in the Bandit Setting with Application to Adaptive Clinical Trials
Mar 24, 2019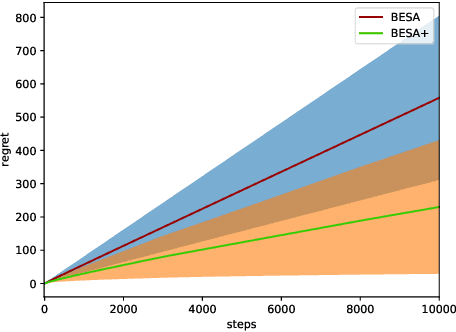
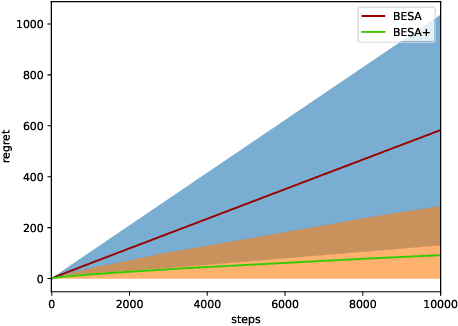
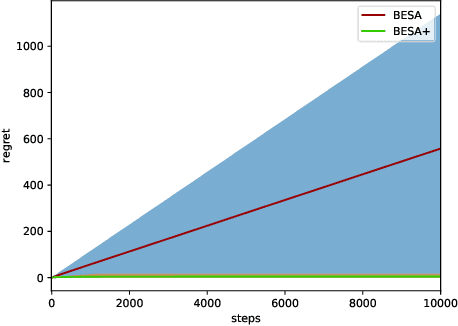
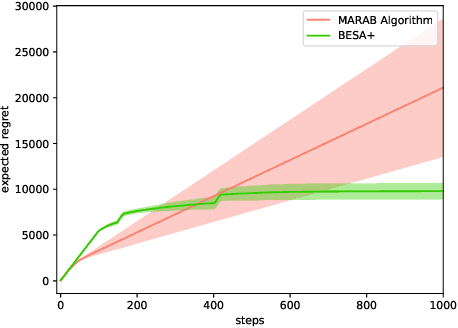
The stochastic multi-armed bandit problem is a well-known model for studying the exploration-exploitation trade-off. It has significant possible applications in adaptive clinical trials, which allow for dynamic changes in the treatment allocation probabilities of patients. However, most bandit learning algorithms are designed with the goal of minimizing the expected regret. While this approach is useful in many areas, in clinical trials, it can be sensitive to outlier data, especially when the sample size is small. In this paper, we define and study a new robustness criterion for bandit problems. Specifically, we consider optimizing a function of the distribution of returns as a regret measure. This provides practitioners more flexibility to define an appropriate regret measure. The learning algorithm we propose to solve this type of problem is a modification of the BESA algorithm [Baransi et al., 2014], which considers a more general version of regret. We present a regret bound for our approach and evaluate it empirically both on synthetic problems as well as on a dataset from the clinical trial literature. Our approach compares favorably to a suite of standard bandit algorithms.