 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangled Counterfactual Reasoning for Unbiased Sequential Recommendation
Aug 05, 2023Sequential recommender systems have achieved state-of-the-art recommendation performance by modeling the sequential dynamics of user activities. However, in most recommendation scenarios, the popular items comprise the major part of the previous user actions. Therefore, the learned models are biased towards the popular items irrespective of the user's real interests. In this paper, we propose a structural causal model-based method to address the popularity bias issue for sequential recommendation model learning. For more generalizable modeling, we disentangle the popularity and interest representations at both the item side and user context side. Based on the disentangled representation, we identify a more effective structural causal graph for general recommendation applications. Then, we design delicate sequential models to apply the aforementioned causal graph to the sequential recommendation scenario for unbiased prediction with counterfactual reasoning. Furthermore, we conduct extensive offline experiments and online A/B tests to verify the proposed \textbf{DCR} (Disentangled Counterfactual Reasoning) method's superior overall performance and understand the effectiveness of the various introduced components. Based on our knowledge, this is the first structural causal model specifically designed for the popularity bias correction of sequential recommendation models, which achieves significant performance gains over the existing methods.
Unbiased Pairwise Learning from Implicit Feedback for Recommender Systems without Biased Variance Control
Apr 14, 2023Generally speaking, the model training for recommender systems can be based on two types of data, namely explicit feedback and implicit feedback. Moreover, because of its general availability, we see wide adoption of implicit feedback data, such as click signal. There are mainly two challenges for the application of implicit feedback. First, implicit data just includes positive feedback. Therefore, we are not sure whether the non-interacted items are really negative or positive but not displayed to the corresponding user. Moreover, the relevance of rare items is usually underestimated since much fewer positive feedback of rare items is collected compared with popular ones. To tackle such difficulties, both pointwise and pairwise solutions are proposed before for unbiased relevance learning. As pairwise learning suits well for the ranking tasks, the previously proposed unbiased pairwise learning algorithm already achieves state-of-the-art performance. Nonetheless, the existing unbiased pairwise learning method suffers from high variance. To get satisfactory performance, non-negative estimator is utilized for practical variance control but introduces additional bias. In this work, we propose an unbiased pairwise learning method, named UPL, with much lower variance to learn a truly unbiased recommender model. Extensive offline experiments on real world datasets and online A/B testing demonstrate the superior performance of our proposed method.
* 5 pages
Unbiased Learning to Rank with Biased Continuous Feedback
Mar 08, 2023It is a well-known challenge to learn an unbiased ranker with biased feedback. Unbiased learning-to-rank(LTR) algorithms, which are verified to model the relative relevance accurately based on noisy feedback, are appealing candidates and have already been applied in many applications with single categorical labels, such as user click signals. Nevertheless, the existing unbiased LTR methods cannot properly handle continuous feedback, which are essential for many industrial applications, such as content recommender systems. To provide personalized high-quality recommendation results, recommender systems need model both categorical and continuous biased feedback, such as click and dwell time. Accordingly, we design a novel unbiased LTR algorithm to tackle the challenges, which innovatively models position bias in the pairwise fashion and introduces the pairwise trust bias to separate the position bias, trust bias, and user relevance explicitly and can work for both continuous and categorical feedback. Experiment results on public benchmark datasets and internal live traffic of a large-scale recommender system at Tencent News show superior results for continuous labels and also competitive performance for categorical labels of the proposed method.
* 10 pages. arXiv admin note: substantial text overlap with arXiv:2111.12929
Unbiased Pairwise Learning to Rank in Recommender Systems
Nov 30, 2021
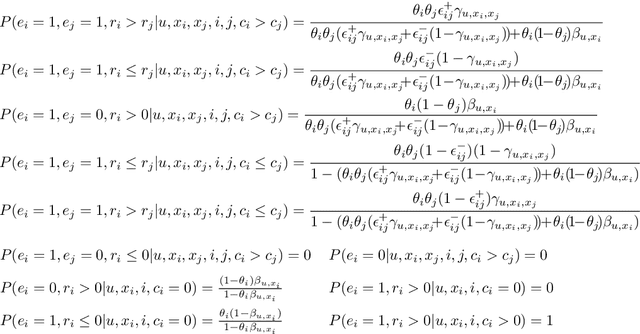

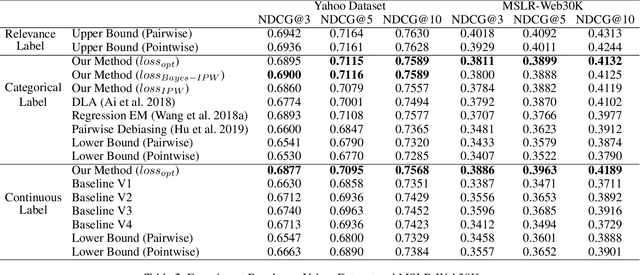
Nowadays, recommender systems already impact almost every facet of peoples lives. To provide personalized high quality recommendation results, conventional systems usually train pointwise rankers to predict the absolute value of objectives and leverage a distinct shallow tower to estimate and alleviate the impact of position bias. However, with such a training paradigm, the optimization target differs a lot from the ranking metrics valuing the relative order of top ranked items rather than the prediction precision of each item. Moreover, as the existing system tends to recommend more relevant items at higher positions, it is difficult for the shallow tower based methods to precisely attribute the user feedback to the impact of position or relevance. Therefore, there exists an exciting opportunity for us to get enhanced performance if we manage to solve the aforementioned issues. Unbiased learning to rank algorithms, which are verified to model the relative relevance accurately based on noisy feedback, are appealing candidates and have already been applied in many applications with single categorical labels, such as user click signals. Nevertheless, the existing unbiased LTR methods cannot properly handle multiple feedback incorporating both categorical and continuous labels. Accordingly, we design a novel unbiased LTR algorithm to tackle the challenges, which innovatively models position bias in the pairwise fashion and introduces the pairwise trust bias to separate the position bias, trust bias, and user relevance explicitly. Experiment results on public benchmark datasets and internal live traffic show the superior results of the proposed method for both categorical and continuous labels.