 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUrbanV2X: A Multisensory Vehicle-Infrastructure Dataset for Cooperative Navigation in Urban Areas
Dec 23, 2025



Due to the limitations of a single autonomous vehicle, Cellular Vehicle-to-Everything (C-V2X) technology opens a new window for achieving fully autonomous driving through sensor information sharing. However, real-world datasets supporting vehicle-infrastructure cooperative navigation in complex urban environments remain rare. To address this gap, we present UrbanV2X, a comprehensive multisensory dataset collected from vehicles and roadside infrastructure in the Hong Kong C-V2X testbed, designed to support research on smart mobility applications in dense urban areas. Our onboard platform provides synchronized data from multiple industrial cameras, LiDARs, 4D radar, ultra-wideband (UWB), IMU, and high-precision GNSS-RTK/INS navigation systems. Meanwhile, our roadside infrastructure provides LiDAR, GNSS, and UWB measurements. The entire vehicle-infrastructure platform is synchronized using the Precision Time Protocol (PTP), with sensor calibration data provided. We also benchmark various navigation algorithms to evaluate the collected cooperative data. The dataset is publicly available at https://polyu-taslab.github.io/UrbanV2X/.
Semantic-Based VPS for Smartphone Localization in Challenging Urban Environments
Nov 21, 2020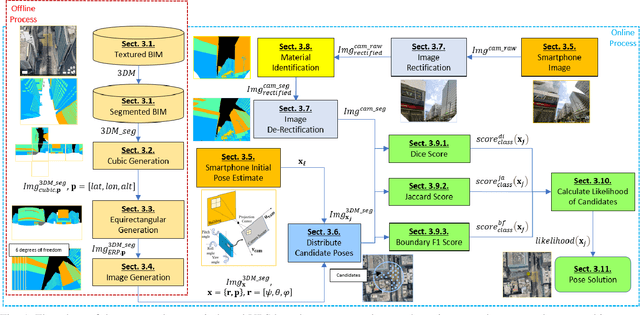
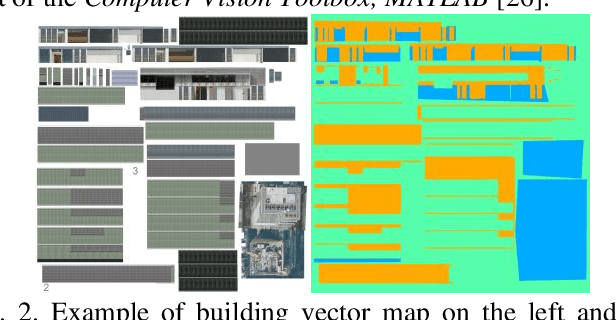
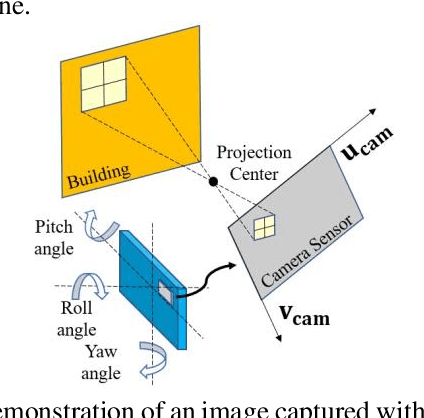

Accurate smartphone-based outdoor localization system in deep urban canyons are increasingly needed for various IoT applications such as augmented reality, intelligent transportation, etc. The recently developed feature-based visual positioning system (VPS) by Google detects edges from smartphone images to match with pre-surveyed edges in their map database. As smart cities develop, the building information modeling (BIM) becomes widely available, which provides an opportunity for a new semantic-based VPS. This article proposes a novel 3D city model and semantic-based VPS for accurate and robust pose estimation in urban canyons where global navigation satellite system (GNSS) tends to fail. In the offline stage, a material segmented city model is used to generate segmented images. In the online stage, an image is taken with a smartphone camera that provides textual information about the surrounding environment. The approach utilizes computer vision algorithms to rectify and hand segment between the different types of material identified in the smartphone image. A semantic-based VPS method is then proposed to match the segmented generated images with the segmented smartphone image. Each generated image holds a pose that contains the latitude, longitude, altitude, yaw, pitch, and roll. The candidate with the maximum likelihood is regarded as the precise pose of the user. The positioning results achieves 2.0m level accuracy in common high rise along street, 5.5m in foliage dense environment and 15.7m in alleyway. A 45% positioning improvement to current state-of-the-art method. The estimation of yaw achieves 2.3{\deg} level accuracy, 8 times the improvement to smartphone IMU.