 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMobile-friendly Image de-noising: Hardware Conscious Optimization for Edge Application
Jan 16, 2026Image enhancement is a critical task in computer vision and photography that is often entangled with noise. This renders the traditional Image Signal Processing (ISP) ineffective compared to the advances in deep learning. However, the success of such methods is increasingly associated with the ease of their deployment on edge devices, such as smartphones. This work presents a novel mobile-friendly network for image de-noising obtained with Entropy-Regularized differentiable Neural Architecture Search (NAS) on a hardware-aware search space for a U-Net architecture, which is first-of-its-kind. The designed model has 12% less parameters, with ~2-fold improvement in ondevice latency and 1.5-fold improvement in the memory footprint for a 0.7% drop in PSNR, when deployed and profiled on Samsung Galaxy S24 Ultra. Compared to the SOTA Swin-Transformer for Image Restoration, the proposed network had competitive accuracy with ~18-fold reduction in GMACs. Further, the network was tested successfully for Gaussian de-noising with 3 intensities on 4 benchmarks and real-world de-noising on 1 benchmark demonstrating its generalization ability.
Robotic Grasp Manipulation Using Evolutionary Computing and Deep Reinforcement Learning
Jan 15, 2020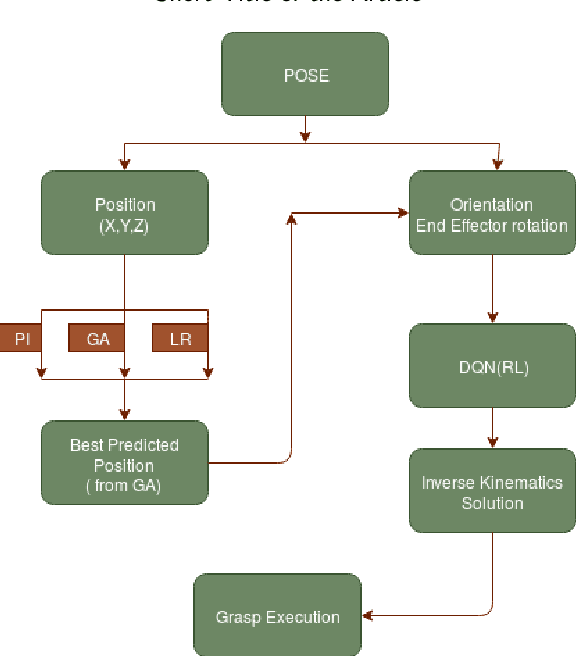
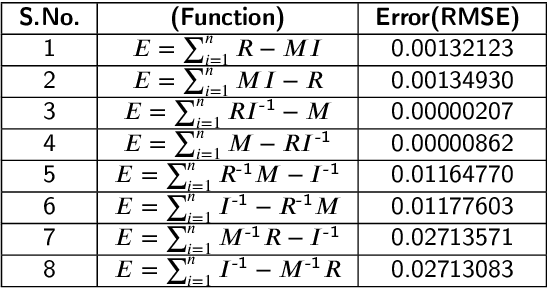
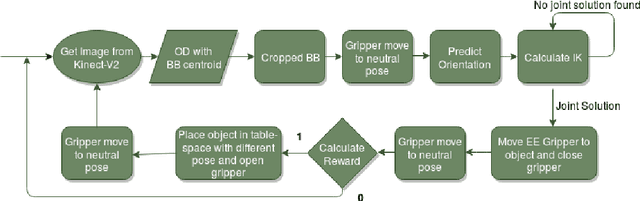

Intelligent Object manipulation for grasping is a challenging problem for robots. Unlike robots, humans almost immediately know how to manipulate objects for grasping due to learning over the years. A grown woman can grasp objects more skilfully than a child because of learning skills developed over years, the absence of which in the present day robotic grasping compels it to perform well below the human object grasping benchmarks. In this paper we have taken up the challenge of developing learning based pose estimation by decomposing the problem into both position and orientation learning. More specifically, for grasp position estimation, we explore three different methods - a Genetic Algorithm (GA) based optimization method to minimize error between calculated image points and predicted end-effector (EE) position, a regression based method (RM) where collected data points of robot EE and image points have been regressed with a linear model, a PseudoInverse (PI) model which has been formulated in the form of a mapping matrix with robot EE position and image points for several observations. Further for grasp orientation learning, we develop a deep reinforcement learning (DRL) model which we name as Grasp Deep Q-Network (GDQN) and benchmarked our results with Modified VGG16 (MVGG16). Rigorous experimentations show that due to inherent capability of producing very high-quality solutions for optimization problems and search problems, GA based predictor performs much better than the other two models for position estimation. For orientation learning results indicate that off policy learning through GDQN outperforms MVGG16, since GDQN architecture is specially made suitable for the reinforcement learning. Based on our proposed architectures and algorithms, the robot is capable of grasping all rigid body objects having regular shapes.