 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHetero-SplitEE: Split Learning of Neural Networks with Early Exits for Heterogeneous IoT Devices
Dec 10, 2025The continuous scaling of deep neural networks has fundamentally transformed machine learning, with larger models demonstrating improved performance across diverse tasks. This growth in model size has dramatically increased the computational resources required for the training process. Consequently, distributed approaches, such as Federated Learning and Split Learning, have become essential paradigms for scalable deployment. However, existing Split Learning approaches assume client homogeneity and uniform split points across all participants. This critically limits their applicability to real-world IoT systems where devices exhibit heterogeneity in computational resources. To address this limitation, this paper proposes Hetero-SplitEE, a novel method that enables heterogeneous IoT devices to train a shared deep neural network in parallel collaboratively. By integrating heterogeneous early exits into hierarchical training, our approach allows each client to select distinct split points (cut layers) tailored to its computational capacity. In addition, we propose two cooperative training strategies, the Sequential strategy and the Averaging strategy, to facilitate this collaboration among clients with different split points. The Sequential strategy trains clients sequentially with a shared server model to reduce computational overhead. The Averaging strategy enables parallel client training with periodic cross-layer aggregation. Extensive experiments on CIFAR-10, CIFAR-100, and STL-10 datasets using ResNet-18 demonstrate that our method maintains competitive accuracy while efficiently supporting diverse computational constraints, enabling practical deployment of collaborative deep learning in heterogeneous IoT ecosystems.
Exploring the Possibility of TypiClust for Low-Budget Federated Active Learning
May 26, 2025



Federated Active Learning (FAL) seeks to reduce the burden of annotation under the realistic constraints of federated learning by leveraging Active Learning (AL). As FAL settings make it more expensive to obtain ground truth labels, FAL strategies that work well in low-budget regimes, where the amount of annotation is very limited, are needed. In this work, we investigate the effectiveness of TypiClust, a successful low-budget AL strategy, in low-budget FAL settings. Our empirical results show that TypiClust works well even in low-budget FAL settings contrasted with relatively low performances of other methods, although these settings present additional challenges, such as data heterogeneity, compared to AL. In addition, we show that FAL settings cause distribution shifts in terms of typicality, but TypiClust is not very vulnerable to the shifts. We also analyze the sensitivity of TypiClust to feature extraction methods, and it suggests a way to perform FAL even in limited data situations.
mdx: A Cloud Platform for Supporting Data Science and Cross-Disciplinary Research Collaborations
Mar 27, 2022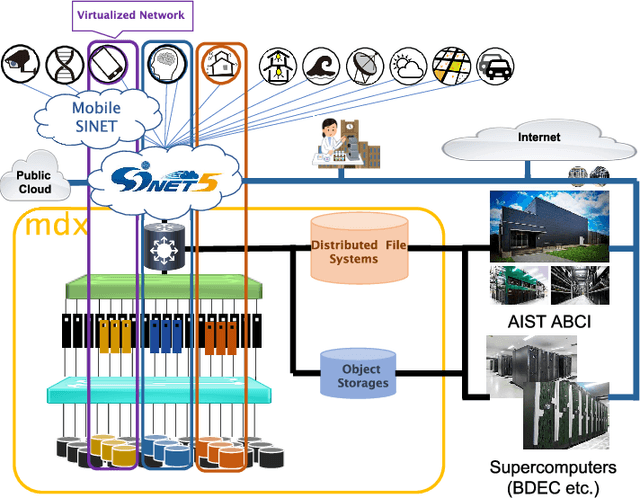
The growing amount of data and advances in data science have created a need for a new kind of cloud platform that provides users with flexibility, strong security, and the ability to couple with supercomputers and edge devices through high-performance networks. We have built such a nation-wide cloud platform, called "mdx" to meet this need. The mdx platform's virtualization service, jointly operated by 9 national universities and 2 national research institutes in Japan, launched in 2021, and more features are in development. Currently mdx is used by researchers in a wide variety of domains, including materials informatics, geo-spatial information science, life science, astronomical science, economics, social science, and computer science. This paper provides an the overview of the mdx platform, details the motivation for its development, reports its current status, and outlines its future plans.