 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBusiness World Model
Jun 08, 2026Businesses are increasingly adopting AI-enabled tools to improve productivity, reduce costs, and enhance products and services. However, the transformative potential of AI extends beyond automating predefined tasks: it lies in enabling intelligent systems to plan, optimize, and execute business initiatives from high-level strategic objectives. This paper introduces the concept and architecture of a business world model (BWM), a world model specialized for business and organizational environments. Inspired by world models in artificial intelligence, cognitive science, and control theory, a BWM encodes business states, dynamics, constraints, objectives, and feasible action space to support autonomous decision-making. We propose a business-semantics-centric formulation in which business states, dynamics and actions are linked to key business entities. Within this framework, agents can simulate alternative action sequences, estimate their effects on future business outcomes, and evaluate trade-offs under uncertainty. The proposed architecture integrates semantic data representations, probabilistic machine learning models, deterministic business rules, and explicit action space into a coherent structure for planning and counterfactual reasoning. Although its individual components are not new, the contribution of BWM lies in organizing them as an executable internal simulator for business initiatives. This work establishes a conceptual foundation for autonomous business systems capable of moving from instruction-based execution toward goal-driven planning and execution.
Autonomous Business System via Neuro-symbolic AI
Jan 22, 2026Current business environments require organizations to continuously reconfigure cross-functional processes, yet enterprise systems are still organized around siloed departments, rigid workflows, and hard-coded automation. Meanwhile large language models (LLMs) excel at interpreting natural language and unstructured data but lack deterministic, verifiable execution of complex business logic. To address this gap, here we introduce AUTOBUS, an Autonomous Business System that integrates LLM-based AI agents, predicate-logic programming, and business-semantics-centric enterprise data into a coherent neuro-symbolic AI architecture for orchestrating end-to-end business initiatives. AUTOBUS models an initiative as a network of tasks with explicit pre/post conditions, required data, evaluation rules, and API-level actions. Enterprise data is organized as a knowledge graph whose entities, relationships, and constraints are translated into logic facts and foundational rules, providing the semantic grounding for task reasoning. Core AI agents synthesize task instructions, enterprise semantics, and available tools into task-specific logic programs, which are executed by a logic engine that enforces constraints, coordinates auxiliary tools, and orchestrate execution of actions and outcomes. Humans define and maintain the semantics, policies and task instructions, curate tools, and supervise high-impact or ambiguous decisions, ensuring accountability and adaptability. We detail the AUTOBUS architecture, the anatomy of the AI agent generated logic programs, and the role of humans and auxiliary tools in the lifecycle of a business initiative.
Structural Cellular Hash Chemistry
Dec 17, 2024Hash Chemistry, a minimalistic artificial chemistry model of open-ended evolution, has recently been extended to non-spatial and cellular versions. The non-spatial version successfully demonstrated continuous adaptation and unbounded growth of complexity of self-replicating entities, but it did not simulate multiscale ecological interactions among the entities. On the contrary, the cellular version explicitly represented multiscale spatial ecological interactions among evolving patterns, yet it failed to show meaningful adaptive evolution or complexity growth. It remains an open question whether it is possible to create a similar minimalistic evolutionary system that can exhibit all of those desired properties at once within a computationally efficient framework. Here we propose an improved version called Structural Cellular Hash Chemistry (SCHC). In SCHC, individual identities of evolving patterns are explicitly represented and processed as the connected components of the nearest neighbor graph of active cells. The neighborhood connections are established by connecting active cells with other active cells in their Moore neighborhoods in a 2D cellular grid. Evolutionary dynamics in SCHC are simulated via pairwise competitions of two randomly selected patterns, following the approach used in the non-spatial Hash Chemistry. SCHC's computational cost was significantly less than the original and non-spatial versions. Numerical simulations showed that these model modifications achieved spontaneous movement, self-replication and unbounded growth of complexity of spatial evolving patterns, which were clearly visible in space in a highly intuitive manner. Detailed analysis of simulation results showed that there were spatial ecological interactions among self-replicating patterns and their diversity was also substantially promoted in SCHC, neither of which was present in the non-spatial version.
Matrix-weighted networks for modeling multidimensional dynamics
Oct 07, 2024



Networks are powerful tools for modeling interactions in complex systems. While traditional networks use scalar edge weights, many real-world systems involve multidimensional interactions. For example, in social networks, individuals often have multiple interconnected opinions that can affect different opinions of other individuals, which can be better characterized by matrices. We propose a novel, general framework for modeling such multidimensional interacting dynamics: matrix-weighted networks (MWNs). We present the mathematical foundations of MWNs and examine consensus dynamics and random walks within this context. Our results reveal that the coherence of MWNs gives rise to non-trivial steady states that generalize the notions of communities and structural balance in traditional networks.
Swarm Systems as a Platform for Open-Ended Evolutionary Dynamics
Sep 02, 2024



Artificial swarm systems have been extensively studied and used in computer science, robotics, engineering and other technological fields, primarily as a platform for implementing robust distributed systems to achieve pre-defined objectives. However, such swarm systems, especially heterogeneous ones, can also be utilized as an ideal platform for creating *open-ended evolutionary dynamics* that do not converge toward pre-defined goals but keep exploring diverse possibilities and generating novel outputs indefinitely. In this article, we review Swarm Chemistry and its variants as concrete sample cases to illustrate beneficial characteristics of heterogeneous swarm systems, including the cardinality leap of design spaces, multiscale structures/behaviors and their diversity, and robust self-organization, self-repair and ecological interactions of emergent patterns, all of which serve as the driving forces for open-ended evolutionary processes. Applications to science, engineering, and art/entertainment as well as the directions of further research are also discussed.
Non-Spatial Hash Chemistry as a Minimalistic Open-Ended Evolutionary System
Apr 27, 2024



There is an increasing level of interest in open-endedness in the recent literature of Artificial Life and Artificial Intelligence. We previously proposed the cardinality leap of possibility spaces as a promising mechanism to facilitate open-endedness in artificial evolutionary systems, and demonstrated its effectiveness using Hash Chemistry, an artificial chemistry model that used a hash function as a universal fitness evaluator. However, the spatial nature of Hash Chemistry came with extensive computational costs involved in its simulation, and the particle density limit imposed to prevent explosion of computational costs prevented unbounded growth in complexity of higher-order entities. To address these limitations, here we propose a simpler non-spatial variant of Hash Chemistry in which spatial proximity of particles are represented explicitly in the form of multisets. This model modification achieved a significant reduction of computational costs in simulating the model. Results of numerical simulations showed much more significant unbounded growth in both maximal and average sizes of replicating higher-order entities than the original model, demonstrating the effectiveness of this non-spatial model as a minimalistic example of open-ended evolutionary systems.
The Origin of Information Handling
Apr 05, 2024



A major challenge when describing the origin of life is to explain how instructional information control systems emerge naturally and spontaneously from mere molecular dynamics. So far, no one has clarified how information control emerged ab initio and how primitive control mechanisms in life might have evolved, becoming increasingly refined. Based on recent experimental results showing that chemical computation does not require the presence of life-related chemistry, we elucidate the origin and early evolution of information handling by chemical automata, from information processing (computation) to information storage (memory) and information transmission (communication). In contrast to other theories that assume the existence of initial complex structures, our narrative starts from trivial self-replicators whose interaction leads to the arising of more powerful molecular machines. By describing precisely the primordial transitions in chemistry-based computation, our metaphor is capable of explaining the above-mentioned gaps and can be translated to other models of computation, which allow us to explore biological phenomena at multiple spatial and temporal scales. At the end of our manuscript, we propose some ways to extend our ideas, including experimental validation of our theory (both in vitro and in silico).
Self-Reproduction and Evolution in Cellular Automata: 25 Years after Evoloops
Feb 06, 2024

The year of 2024 marks the 25th anniversary of the publication of evoloops, an evolutionary variant of Chris Langton's self-reproducing loops which proved that Darwinian evolution of self-reproducing organisms by variation and natural selection is possible within deterministic cellular automata. Over the last few decades, this line of Artificial Life research has since undergone several important developments. Although it experienced a relative dormancy of activities for a while, the recent rise of interest in open-ended evolution and the success of continuous cellular automata models have brought researchers' attention back to how to make spatio-temporal patterns self-reproduce and evolve within spatially distributed computational media. This article provides a review of the relevant literature on this topic over the past 25 years and highlights the major accomplishments made so far, the challenges being faced, and promising future research directions.
Extracting Network Structures from Corporate Organization Charts Using Heuristic Image Processing
Nov 04, 2023



Organizational structure of corporations has potential to provide implications for dynamics and performance of corporate operations. However, this subject has remained unexplored because of the lack of readily available organization network datasets. To overcome the this gap, we developed a new heuristic image-processing method to extract and reconstruct organization network data from published organization charts. Our method analyzes a PDF file of a corporate organization chart and detects text labels, boxes, connecting lines, and other objects through multiple steps of heuristically implemented image processing. The detected components are reorganized together into a Python's NetworkX Graph object for visualization, validation and further network analysis. We applied the developed method to the organization charts of all the listed firms in Japan shown in the ``Organization Chart/System Diagram Handbook'' published by Diamond, Inc., from 2008 to 2011. Out of the 10,008 organization chart PDF files, our method was able to reconstruct 4,606 organization networks (data acquisition success rate: 46%). For each reconstructed organization network, we measured several network diagnostics, which will be used for further statistical analysis to investigate their potential correlations with corporate behavior and performance.
Speaker Diarization Using Stereo Audio Channels: Preliminary Study on Utterance Clustering
Sep 10, 2020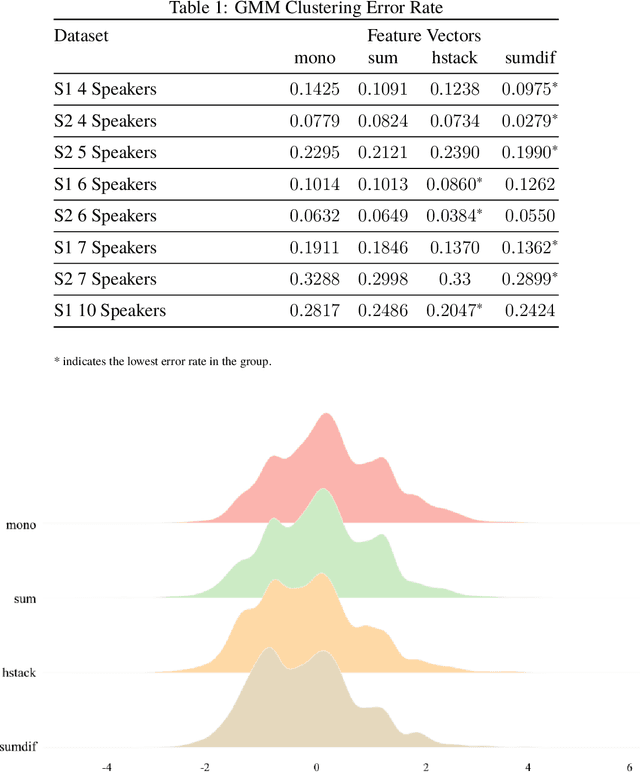
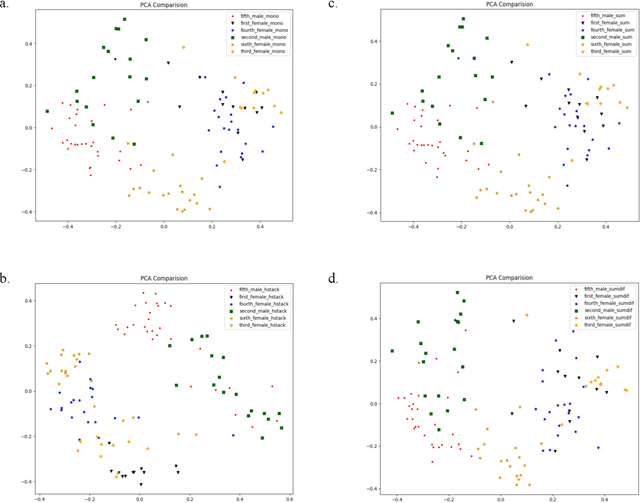
Speaker diarization is one of the actively researched topics in audio signal processing and machine learning. Utterance clustering is a critical part of a speaker diarization task. In this study, we aim to improve the performance of utterance clustering by processing multichannel (stereo) audio signals. We generated processed audio signals by combining left- and right-channel audio signals in a few different ways and then extracted embedded features (also called d-vectors) from those processed audio signals. We applied the Gaussian mixture model (GMM) for supervised utterance clustering. In the training phase, we used a parameter sharing GMM to train the model for each speaker. In the testing phase, we selected the speaker with the maximum likelihood as the detected speaker. Results of experiments with real audio recordings of multi-person discussion sessions showed that our proposed method that used multichannel audio signals achieved significantly better performance than a conventional method with mono audio signals.