 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Ambiguous Dynamic Facial Expression Recognition with Soft Label-based Data Augmentation
Jun 25, 2025



Dynamic facial expression recognition (DFER) is a task that estimates emotions from facial expression video sequences. For practical applications, accurately recognizing ambiguous facial expressions -- frequently encountered in in-the-wild data -- is essential. In this study, we propose MIDAS, a data augmentation method designed to enhance DFER performance for ambiguous facial expression data using soft labels representing probabilities of multiple emotion classes. MIDAS augments training data by convexly combining pairs of video frames and their corresponding emotion class labels. This approach extends mixup to soft-labeled video data, offering a simple yet highly effective method for handling ambiguity in DFER. To evaluate MIDAS, we conducted experiments on both the DFEW dataset and FERV39k-Plus, a newly constructed dataset that assigns soft labels to an existing DFER dataset. The results demonstrate that models trained with MIDAS-augmented data achieve superior performance compared to the state-of-the-art method trained on the original dataset.
Deep Bayesian Active Learning-to-Rank with Relative Annotation for Estimation of Ulcerative Colitis Severity
Sep 10, 2024



Automatic image-based severity estimation is an important task in computer-aided diagnosis. Severity estimation by deep learning requires a large amount of training data to achieve a high performance. In general, severity estimation uses training data annotated with discrete (i.e., quantized) severity labels. Annotating discrete labels is often difficult in images with ambiguous severity, and the annotation cost is high. In contrast, relative annotation, in which the severity between a pair of images is compared, can avoid quantizing severity and thus makes it easier. We can estimate relative disease severity using a learning-to-rank framework with relative annotations, but relative annotation has the problem of the enormous number of pairs that can be annotated. Therefore, the selection of appropriate pairs is essential for relative annotation. In this paper, we propose a deep Bayesian active learning-to-rank that automatically selects appropriate pairs for relative annotation. Our method preferentially annotates unlabeled pairs with high learning efficiency from the model uncertainty of the samples. We prove the theoretical basis for adapting Bayesian neural networks to pairwise learning-to-rank and demonstrate the efficiency of our method through experiments on endoscopic images of ulcerative colitis on both private and public datasets. We also show that our method achieves a high performance under conditions of significant class imbalance because it automatically selects samples from the minority classes.
* 14 pages, 8 figures, accepted in Medical Image Analysis 2024
SpotFormer: Multi-Scale Spatio-Temporal Transformer for Facial Expression Spotting
Jul 30, 2024



Facial expression spotting, identifying periods where facial expressions occur in a video, is a significant yet challenging task in facial expression analysis. The issues of irrelevant facial movements and the challenge of detecting subtle motions in micro-expressions remain unresolved, hindering accurate expression spotting. In this paper, we propose an efficient framework for facial expression spotting. First, we propose a Sliding Window-based Multi-Resolution Optical flow (SW-MRO) feature, which calculates multi-resolution optical flow of the input image sequence within compact sliding windows. The window length is tailored to perceive complete micro-expressions and distinguish between general macro- and micro-expressions. SW-MRO can effectively reveal subtle motions while avoiding severe head movement problems. Second, we propose SpotFormer, a multi-scale spatio-temporal Transformer that simultaneously encodes spatio-temporal relationships of the SW-MRO features for accurate frame-level probability estimation. In SpotFormer, our proposed Facial Local Graph Pooling (FLGP) and convolutional layers are applied for multi-scale spatio-temporal feature extraction. We show the validity of the architecture of SpotFormer by comparing it with several model variants. Third, we introduce supervised contrastive learning into SpotFormer to enhance the discriminability between different types of expressions. Extensive experiments on SAMM-LV and CAS(ME)^2 show that our method outperforms state-of-the-art models, particularly in micro-expression spotting.
CALICO: Confident Active Learning with Integrated Calibration
Jul 02, 2024The growing use of deep learning in safety-critical applications, such as medical imaging, has raised concerns about limited labeled data, where this demand is amplified as model complexity increases, posing hurdles for domain experts to annotate data. In response to this, active learning (AL) is used to efficiently train models with limited annotation costs. In the context of deep neural networks (DNNs), AL often uses confidence or probability outputs as a score for selecting the most informative samples. However, modern DNNs exhibit unreliable confidence outputs, making calibration essential. We propose an AL framework that self-calibrates the confidence used for sample selection during the training process, referred to as Confident Active Learning with Integrated CalibratiOn (CALICO). CALICO incorporates the joint training of a classifier and an energy-based model, instead of the standard softmax-based classifier. This approach allows for simultaneous estimation of the input data distribution and the class probabilities during training, improving calibration without needing an additional labeled dataset. Experimental results showcase improved classification performance compared to a softmax-based classifier with fewer labeled samples. Furthermore, the calibration stability of the model is observed to depend on the prior class distribution of the data.
Pseudo-label Learning with Calibrated Confidence Using an Energy-based Model
Apr 15, 2024



In pseudo-labeling (PL), which is a type of semi-supervised learning, pseudo-labels are assigned based on the confidence scores provided by the classifier; therefore, accurate confidence is important for successful PL. In this study, we propose a PL algorithm based on an energy-based model (EBM), which is referred to as the energy-based PL (EBPL). In EBPL, a neural network-based classifier and an EBM are jointly trained by sharing their feature extraction parts. This approach enables the model to learn both the class decision boundary and input data distribution, enhancing confidence calibration during network training. The experimental results demonstrate that EBPL outperforms the existing PL method in semi-supervised image classification tasks, with superior confidence calibration error and recognition accuracy.
Multi-Scale Spatio-Temporal Graph Convolutional Network for Facial Expression Spotting
Mar 24, 2024



Facial expression spotting is a significant but challenging task in facial expression analysis. The accuracy of expression spotting is affected not only by irrelevant facial movements but also by the difficulty of perceiving subtle motions in micro-expressions. In this paper, we propose a Multi-Scale Spatio-Temporal Graph Convolutional Network (SpoT-GCN) for facial expression spotting. To extract more robust motion features, we track both short- and long-term motion of facial muscles in compact sliding windows whose window length adapts to the temporal receptive field of the network. This strategy, termed the receptive field adaptive sliding window strategy, effectively magnifies the motion features while alleviating the problem of severe head movement. The subtle motion features are then converted to a facial graph representation, whose spatio-temporal graph patterns are learned by a graph convolutional network. This network learns both local and global features from multiple scales of facial graph structures using our proposed facial local graph pooling (FLGP). Furthermore, we introduce supervised contrastive learning to enhance the discriminative capability of our model for difficult-to-classify frames. The experimental results on the SAMM-LV and CAS(ME)^2 datasets demonstrate that our method achieves state-of-the-art performance, particularly in micro-expression spotting. Ablation studies further verify the effectiveness of our proposed modules.
Analyzing Font Style Usage and Contextual Factors in Real Images
Jun 21, 2023



There are various font styles in the world. Different styles give different impressions and readability. This paper analyzes the relationship between font styles and contextual factors that might affect font style selection with large-scale datasets. For example, we will analyze the relationship between font style and its surrounding object (such as ``bus'') by using about 800,000 words in the Open Images dataset. We also use a book cover dataset to analyze the relationship between font styles with book genres. Moreover, the meaning of the word is assumed as another contextual factor. For these numeric analyses, we utilize our own font-style feature extraction model and word2vec. As a result of co-occurrence-based relationship analysis, we found several instances of specific font styles being used for specific contextual factors.
A Hybrid of Generative and Discriminative Models Based on the Gaussian-coupled Softmax Layer
May 10, 2023Generative models have advantageous characteristics for classification tasks such as the availability of unsupervised data and calibrated confidence, whereas discriminative models have advantages in terms of the simplicity of their model structures and learning algorithms and their ability to outperform their generative counterparts. In this paper, we propose a method to train a hybrid of discriminative and generative models in a single neural network (NN), which exhibits the characteristics of both models. The key idea is the Gaussian-coupled softmax layer, which is a fully connected layer with a softmax activation function coupled with Gaussian distributions. This layer can be embedded into an NN-based classifier and allows the classifier to estimate both the class posterior distribution and the class-conditional data distribution. We demonstrate that the proposed hybrid model can be applied to semi-supervised learning and confidence calibration.
Deep Bayesian Active-Learning-to-Rank for Endoscopic Image Data
Aug 05, 2022Automatic image-based disease severity estimation generally uses discrete (i.e., quantized) severity labels. Annotating discrete labels is often difficult due to the images with ambiguous severity. An easier alternative is to use relative annotation, which compares the severity level between image pairs. By using a learning-to-rank framework with relative annotation, we can train a neural network that estimates rank scores that are relative to severity levels. However, the relative annotation for all possible pairs is prohibitive, and therefore, appropriate sample pair selection is mandatory. This paper proposes a deep Bayesian active-learning-to-rank, which trains a Bayesian convolutional neural network while automatically selecting appropriate pairs for relative annotation. We confirmed the efficiency of the proposed method through experiments on endoscopic images of ulcerative colitis. In addition, we confirmed that our method is useful even with the severe class imbalance because of its ability to select samples from minor classes automatically.
Order-Guided Disentangled Representation Learning for Ulcerative Colitis Classification with Limited Labels
Nov 06, 2021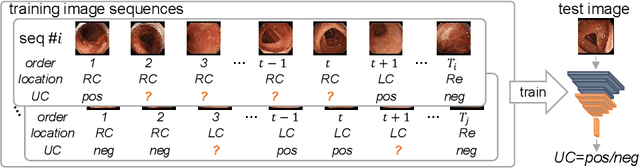
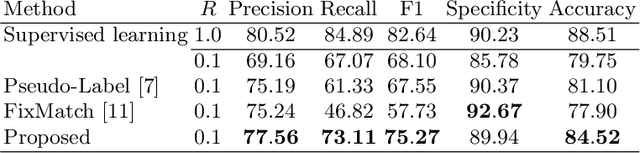
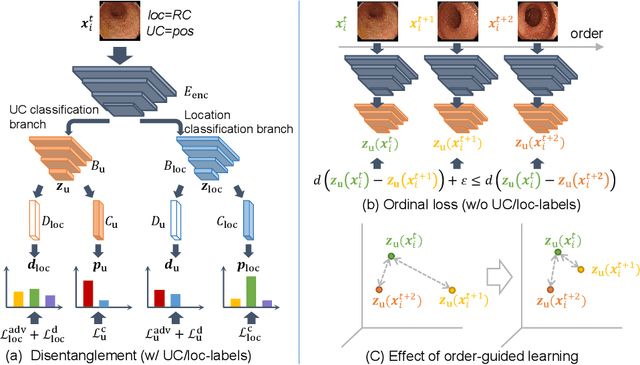

Ulcerative colitis (UC) classification, which is an important task for endoscopic diagnosis, involves two main difficulties. First, endoscopic images with the annotation about UC (positive or negative) are usually limited. Second, they show a large variability in their appearance due to the location in the colon. Especially, the second difficulty prevents us from using existing semi-supervised learning techniques, which are the common remedy for the first difficulty. In this paper, we propose a practical semi-supervised learning method for UC classification by newly exploiting two additional features, the location in a colon (e.g., left colon) and image capturing order, both of which are often attached to individual images in endoscopic image sequences. The proposed method can extract the essential information of UC classification efficiently by a disentanglement process with those features. Experimental results demonstrate that the proposed method outperforms several existing semi-supervised learning methods in the classification task, even with a small number of annotated images.