 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKeyword localisation in untranscribed speech using visually grounded speech models
Feb 02, 2022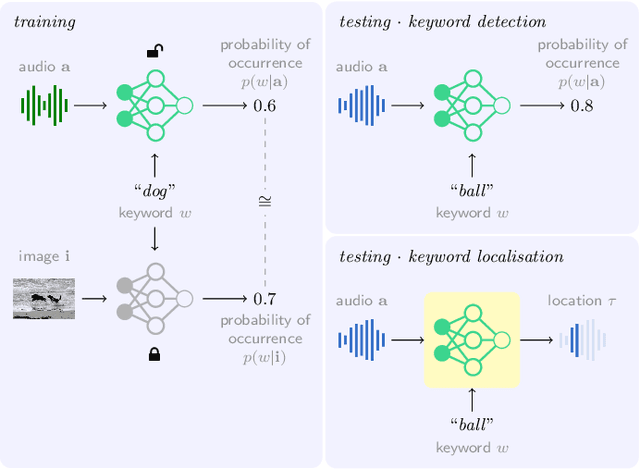
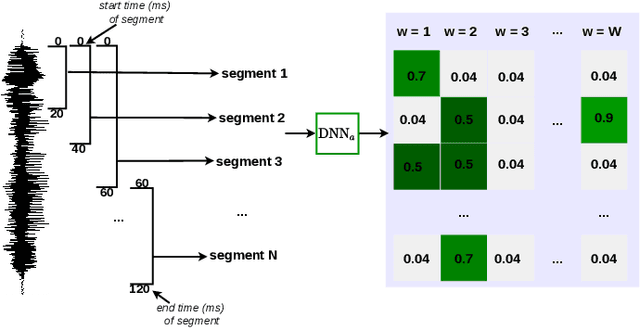
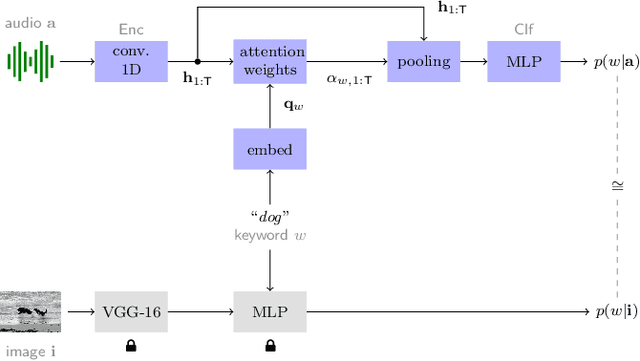
Keyword localisation is the task of finding where in a speech utterance a given query keyword occurs. We investigate to what extent keyword localisation is possible using a visually grounded speech (VGS) model. VGS models are trained on unlabelled images paired with spoken captions. These models are therefore self-supervised -- trained without any explicit textual label or location information. To obtain training targets, we first tag training images with soft text labels using a pretrained visual classifier with a fixed vocabulary. This enables a VGS model to predict the presence of a written keyword in an utterance, but not its location. We consider four ways to equip VGS models with localisations capabilities. Two of these -- a saliency approach and input masking -- can be applied to an arbitrary prediction model after training, while the other two -- attention and a score aggregation approach -- are incorporated directly into the structure of the model. Masked-based localisation gives some of the best reported localisation scores from a VGS model, with an accuracy of 57% when the system knows that a keyword occurs in an utterance and need to predict its location. In a setting where localisation is performed after detection, an $F_1$ of 25% is achieved, and in a setting where a keyword spotting ranking pass is first performed, we get a localisation P@10 of 32%. While these scores are modest compared to the idealised setting with unordered bag-of-word-supervision (from transcriptions), these models do not receive any textual or location supervision. Further analyses show that these models are limited by the first detection or ranking pass. Moreover, individual keyword localisation performance is correlated with the tagging performance from the visual classifier. We also show qualitatively how and where semantic mistakes occur, e.g. that the model locates surfer when queried with ocean.
Towards Learning to Speak and Hear Through Multi-Agent Communication over a Continuous Acoustic Channel
Nov 04, 2021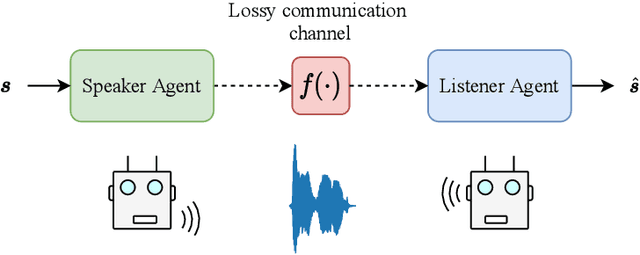

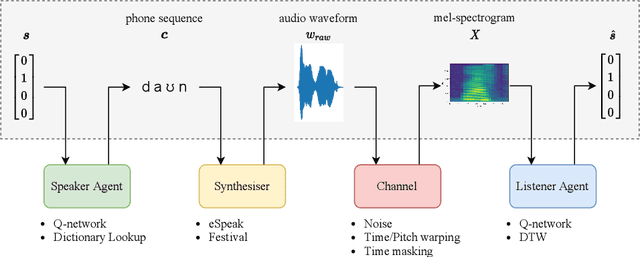
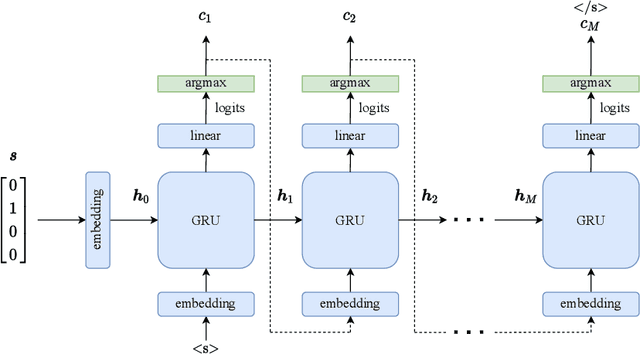
While multi-agent reinforcement learning has been used as an effective means to study emergent communication between agents, existing work has focused almost exclusively on communication with discrete symbols. Human communication often takes place (and emerged) over a continuous acoustic channel; human infants acquire language in large part through continuous signalling with their caregivers. We therefore ask: Are we able to observe emergent language between agents with a continuous communication channel trained through reinforcement learning? And if so, what is the impact of channel characteristics on the emerging language? We propose an environment and training methodology to serve as a means to carry out an initial exploration of these questions. We use a simple messaging environment where a "speaker" agent needs to convey a concept to a "listener". The Speaker is equipped with a vocoder that maps symbols to a continuous waveform, this is passed over a lossy continuous channel, and the Listener needs to map the continuous signal to the concept. Using deep Q-learning, we show that basic compositionality emerges in the learned language representations. We find that noise is essential in the communication channel when conveying unseen concept combinations. And we show that we can ground the emergent communication by introducing a caregiver predisposed to "hearing" or "speaking" English. Finally, we describe how our platform serves as a starting point for future work that uses a combination of deep reinforcement learning and multi-agent systems to study our questions of continuous signalling in language learning and emergence.
Voice Conversion Can Improve ASR in Very Low-Resource Settings
Nov 04, 2021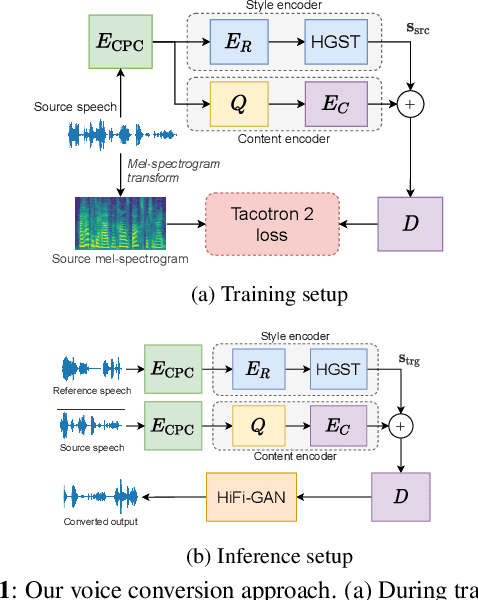
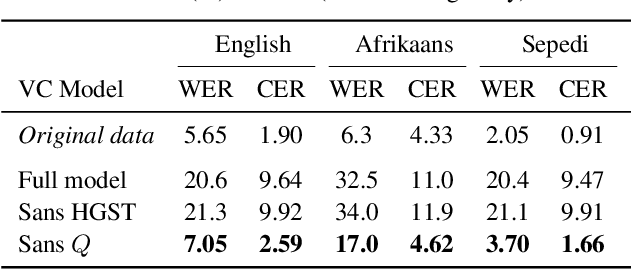
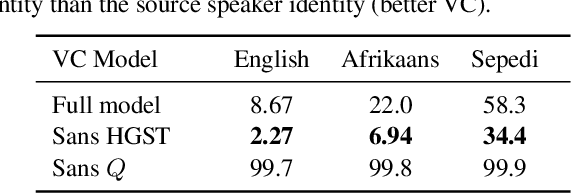

Voice conversion (VC) has been proposed to improve speech recognition systems in low-resource languages by using it to augment limited training data. But until recently, practical issues such as compute speed have limited the use of VC for this purpose. Moreover, it is still unclear whether a VC model trained on one well-resourced language can be applied to speech from another low-resource language for the purpose of data augmentation. In this work we assess whether a VC system can be used cross-lingually to improve low-resource speech recognition. Concretely, we combine several recent techniques to design and train a practical VC system in English, and then use this system to augment data for training a speech recognition model in several low-resource languages. We find that when using a sensible amount of augmented data, speech recognition performance is improved in all four low-resource languages considered.
A Comparison of Discrete and Soft Speech Units for Improved Voice Conversion
Nov 03, 2021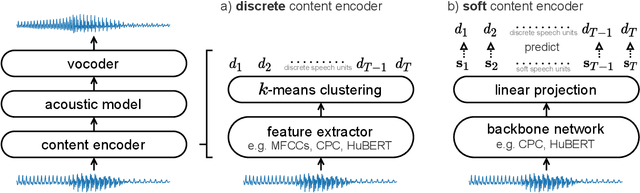
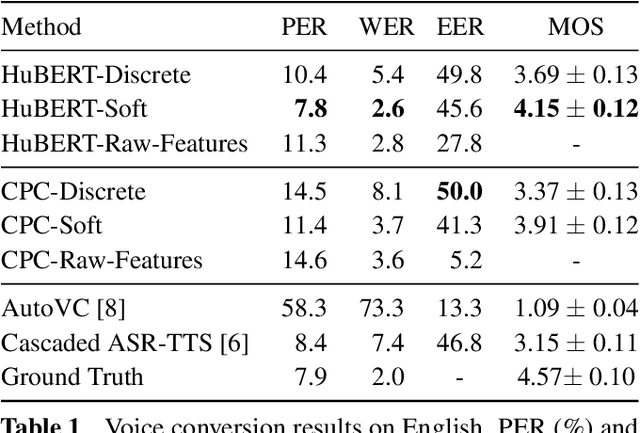

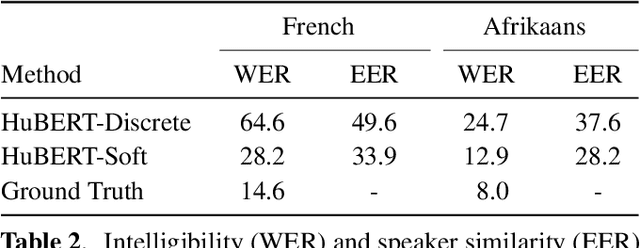
The goal of voice conversion is to transform source speech into a target voice, keeping the content unchanged. In this paper, we focus on self-supervised representation learning for voice conversion. Specifically, we compare discrete and soft speech units as input features. We find that discrete representations effectively remove speaker information but discard some linguistic content - leading to mispronunciations. As a solution, we propose soft speech units. To learn soft units, we predict a distribution over discrete speech units. By modeling uncertainty, soft units capture more content information, improving the intelligibility and naturalness of converted speech. Samples available at https://ubisoft-laforge.github.io/speech/soft-vc/
Feature learning for efficient ASR-free keyword spotting in low-resource languages
Aug 13, 2021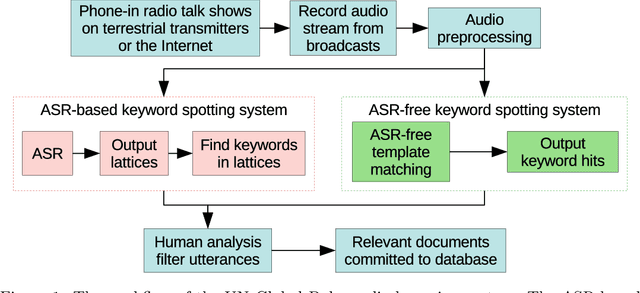
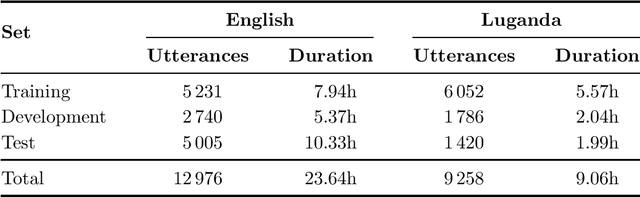

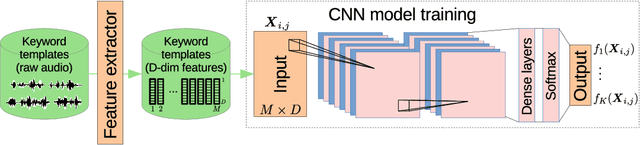
We consider feature learning for efficient keyword spotting that can be applied in severely under-resourced settings. The objective is to support humanitarian relief programmes by the United Nations in parts of Africa in which almost no language resources are available. For rapid development in such languages, we rely on a small, easily-compiled set of isolated keywords. These keyword templates are applied to a large corpus of in-domain but untranscribed speech using dynamic time warping (DTW). The resulting DTW alignment scores are used to train a convolutional neural network (CNN) which is orders of magnitude more computationally efficient and suitable for real-time application. We optimise this neural network keyword spotter by identifying robust acoustic features in this almost zero-resource setting. First, we incorporate information from well-resourced but unrelated languages using a multilingual bottleneck feature (BNF) extractor. Next, we consider features extracted from an autoencoder (AE) trained on in-domain but untranscribed data. Finally, we consider correspondence autoencoder (CAE) features which are fine-tuned on the small set of in-domain labelled data. Experiments in South African English and Luganda, a low-resource language, show that BNF and CAE features achieve a 5% relative performance improvement over baseline MFCCs. However, using BNFs as input to the CAE results in a more than 27% relative improvement over MFCCs in ROC area-under-the-curve (AUC) and more than twice as many top-10 retrievals. We show that, using these features, the CNN-DTW keyword spotter performs almost as well as the DTW keyword spotter while outperforming a baseline CNN trained only on the keyword templates. The CNN-DTW keyword spotter using BNF-derived CAE features represents an efficient approach with competitive performance suited to rapid deployment in a severely under-resourced scenario.
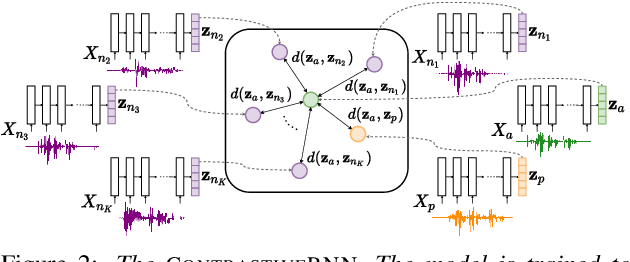
Analyzing Speaker Information in Self-Supervised Models to Improve Zero-Resource Speech Processing
Aug 02, 2021
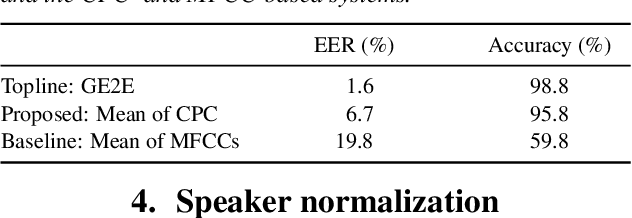
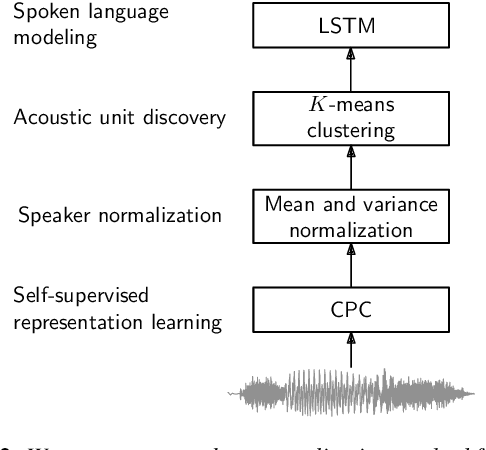
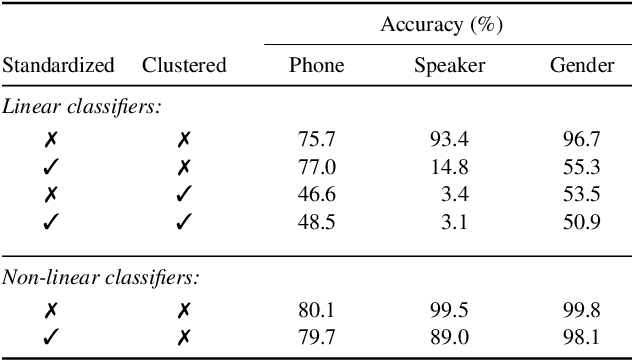
Contrastive predictive coding (CPC) aims to learn representations of speech by distinguishing future observations from a set of negative examples. Previous work has shown that linear classifiers trained on CPC features can accurately predict speaker and phone labels. However, it is unclear how the features actually capture speaker and phonetic information, and whether it is possible to normalize out the irrelevant details (depending on the downstream task). In this paper, we first show that the per-utterance mean of CPC features captures speaker information to a large extent. Concretely, we find that comparing means performs well on a speaker verification task. Next, probing experiments show that standardizing the features effectively removes speaker information. Based on this observation, we propose a speaker normalization step to improve acoustic unit discovery using K-means clustering of CPC features. Finally, we show that a language model trained on the resulting units achieves some of the best results in the ZeroSpeech2021~Challenge.
Mava: a research framework for distributed multi-agent reinforcement learning
Jul 03, 2021
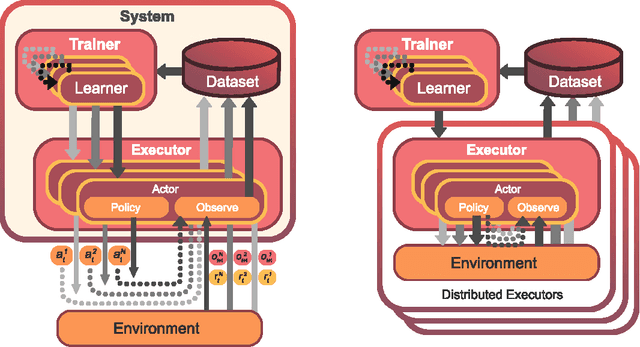
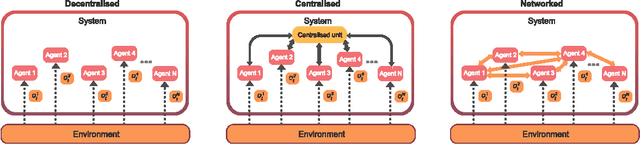

Breakthrough advances in reinforcement learning (RL) research have led to a surge in the development and application of RL. To support the field and its rapid growth, several frameworks have emerged that aim to help the community more easily build effective and scalable agents. However, very few of these frameworks exclusively support multi-agent RL (MARL), an increasingly active field in itself, concerned with decentralised decision-making problems. In this work, we attempt to fill this gap by presenting Mava: a research framework specifically designed for building scalable MARL systems. Mava provides useful components, abstractions, utilities and tools for MARL and allows for simple scaling for multi-process system training and execution, while providing a high level of flexibility and composability. Mava is built on top of DeepMind's Acme \citep{hoffman2020acme}, and therefore integrates with, and greatly benefits from, a wide range of already existing single-agent RL components made available in Acme. Several MARL baseline systems have already been implemented in Mava. These implementations serve as examples showcasing Mava's reusable features, such as interchangeable system architectures, communication and mixing modules. Furthermore, these implementations allow existing MARL algorithms to be easily reproduced and extended. We provide experimental results for these implementations on a wide range of multi-agent environments and highlight the benefits of distributed system training.
Multilingual transfer of acoustic word embeddings improves when training on languages related to the target zero-resource language
Jun 24, 2021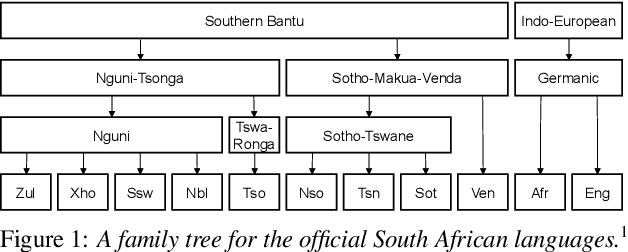
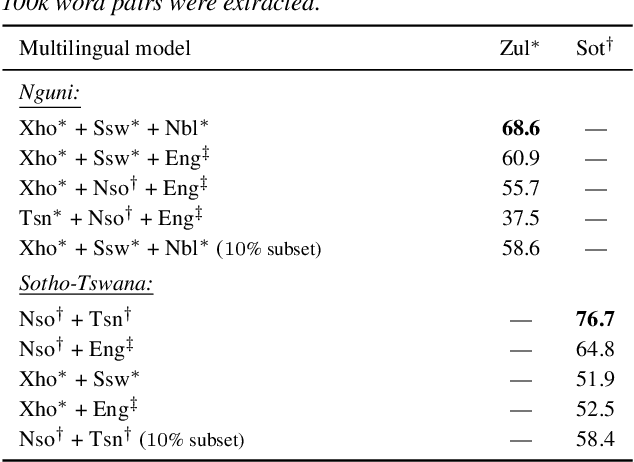
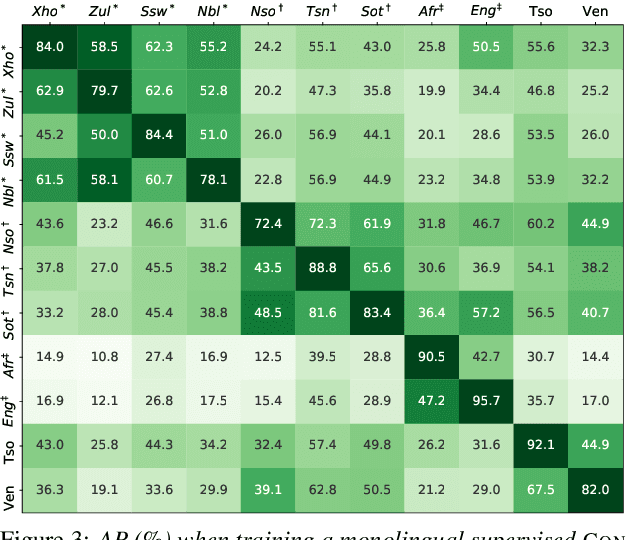
Acoustic word embedding models map variable duration speech segments to fixed dimensional vectors, enabling efficient speech search and discovery. Previous work explored how embeddings can be obtained in zero-resource settings where no labelled data is available in the target language. The current best approach uses transfer learning: a single supervised multilingual model is trained using labelled data from multiple well-resourced languages and then applied to a target zero-resource language (without fine-tuning). However, it is still unclear how the specific choice of training languages affect downstream performance. Concretely, here we ask whether it is beneficial to use training languages related to the target. Using data from eleven languages spoken in Southern Africa, we experiment with adding data from different language families while controlling for the amount of data per language. In word discrimination and query-by-example search evaluations, we show that training on languages from the same family gives large improvements. Through finer-grained analysis, we show that training on even just a single related language gives the largest gain. We also find that adding data from unrelated languages generally doesn't hurt performance.
Attention-Based Keyword Localisation in Speech using Visual Grounding
Jun 23, 2021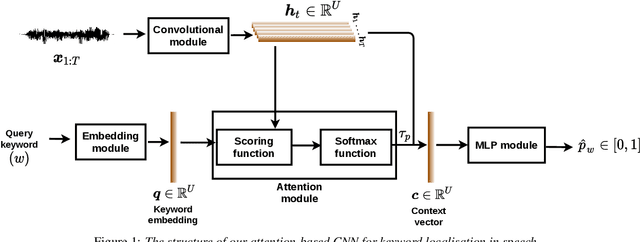
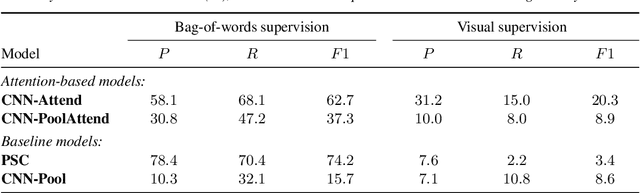
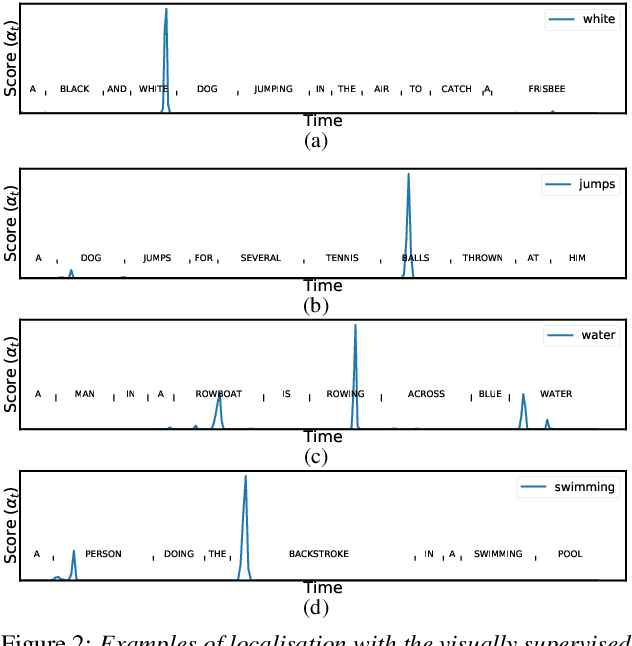
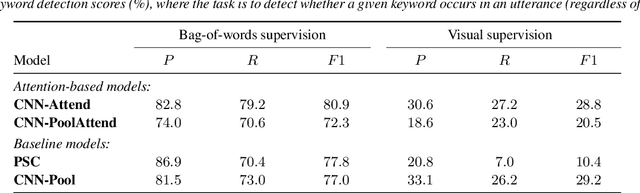
Visually grounded speech models learn from images paired with spoken captions. By tagging images with soft text labels using a trained visual classifier with a fixed vocabulary, previous work has shown that it is possible to train a model that can detect whether a particular text keyword occurs in speech utterances or not. Here we investigate whether visually grounded speech models can also do keyword localisation: predicting where, within an utterance, a given textual keyword occurs without any explicit text-based or alignment supervision. We specifically consider whether incorporating attention into a convolutional model is beneficial for localisation. Although absolute localisation performance with visually supervised models is still modest (compared to using unordered bag-of-word text labels for supervision), we show that attention provides a large gain in performance over previous visually grounded models. As in many other speech-image studies, we find that many of the incorrect localisations are due to semantic confusions, e.g. locating the word 'backstroke' for the query keyword 'swimming'.
StarGAN-ZSVC: Towards Zero-Shot Voice Conversion in Low-Resource Contexts
May 31, 2021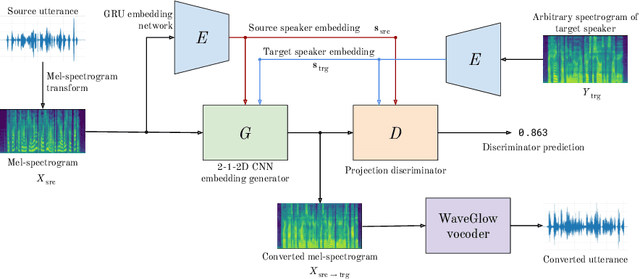
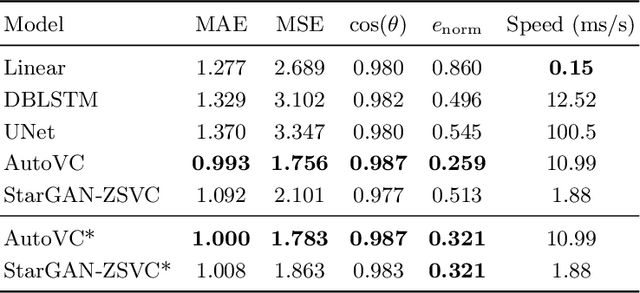
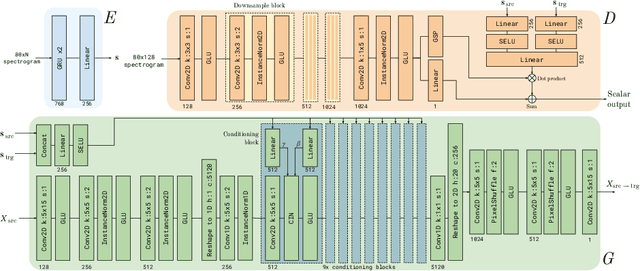
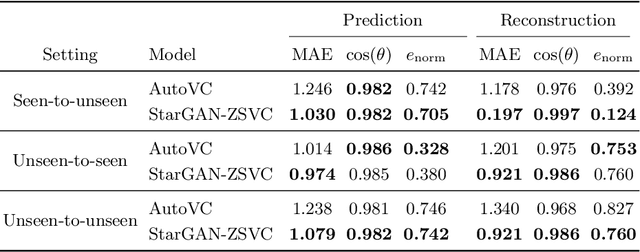
Voice conversion is the task of converting a spoken utterance from a source speaker so that it appears to be said by a different target speaker while retaining the linguistic content of the utterance. Recent advances have led to major improvements in the quality of voice conversion systems. However, to be useful in a wider range of contexts, voice conversion systems would need to be (i) trainable without access to parallel data, (ii) work in a zero-shot setting where both the source and target speakers are unseen during training, and (iii) run in real time or faster. Recent techniques fulfil one or two of these requirements, but not all three. This paper extends recent voice conversion models based on generative adversarial networks (GANs), to satisfy all three of these conditions. We specifically extend the recent StarGAN-VC model by conditioning it on a speaker embedding (from a potentially unseen speaker). This allows the model to be used in a zero-shot setting, and we therefore call it StarGAN-ZSVC. We compare StarGAN-ZSVC against other voice conversion techniques in a low-resource setting using a small 9-minute training set. Compared to AutoVC -- another recent neural zero-shot approach -- we observe that StarGAN-ZSVC gives small improvements in the zero-shot setting, showing that real-time zero-shot voice conversion is possible even for a model trained on very little data. Further work is required to see whether scaling up StarGAN-ZSVC will also improve zero-shot voice conversion quality in high-resource contexts.
* 16 pages, 3 figures. Published in Springer Communications in Computer and Information Science, Artificial Intelligence Research (SACAIR 2021), vol. 1342, pp. 69-84, 2020