 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMava: a research framework for distributed multi-agent reinforcement learning
Jul 03, 2021
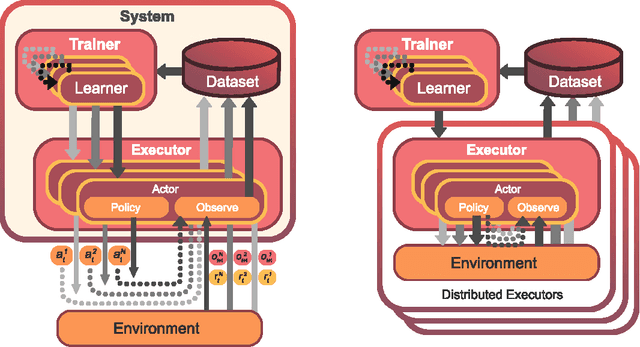
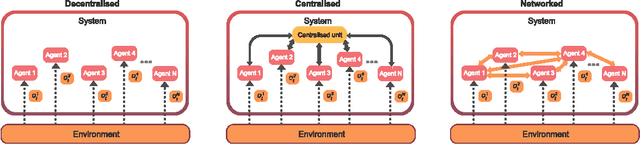

Breakthrough advances in reinforcement learning (RL) research have led to a surge in the development and application of RL. To support the field and its rapid growth, several frameworks have emerged that aim to help the community more easily build effective and scalable agents. However, very few of these frameworks exclusively support multi-agent RL (MARL), an increasingly active field in itself, concerned with decentralised decision-making problems. In this work, we attempt to fill this gap by presenting Mava: a research framework specifically designed for building scalable MARL systems. Mava provides useful components, abstractions, utilities and tools for MARL and allows for simple scaling for multi-process system training and execution, while providing a high level of flexibility and composability. Mava is built on top of DeepMind's Acme \citep{hoffman2020acme}, and therefore integrates with, and greatly benefits from, a wide range of already existing single-agent RL components made available in Acme. Several MARL baseline systems have already been implemented in Mava. These implementations serve as examples showcasing Mava's reusable features, such as interchangeable system architectures, communication and mixing modules. Furthermore, these implementations allow existing MARL algorithms to be easily reproduced and extended. We provide experimental results for these implementations on a wide range of multi-agent environments and highlight the benefits of distributed system training.