 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcerning Uncertainty -- A Systematic Survey of Uncertainty-Aware XAI
Mar 27, 2026This paper surveys uncertainty-aware explainable artificial intelligence (UAXAI), examining how uncertainty is incorporated into explanatory pipelines and how such methods are evaluated. Across the literature, three recurring approaches to uncertainty quantification emerge (Bayesian, Monte Carlo, and Conformal methods), alongside distinct strategies for integrating uncertainty into explanations: assessing trustworthiness, constraining models or explanations, and explicitly communicating uncertainty. Evaluation practices remain fragmented and largely model centered, with limited attention to users and inconsistent reporting of reliability properties (e.g., calibration, coverage, explanation stability). Recent work leans towards calibration, distribution free techniques and recognizes explainer variability as a central concern. We argue that progress in UAXAI requires unified evaluation principles that link uncertainty propagation, robustness, and human decision-making, and highlight counterfactual and calibration approaches as promising avenues for aligning interpretability with reliability.
Fast Calibrated Explanations: Efficient and Uncertainty-Aware Explanations for Machine Learning Models
Oct 28, 2024



This paper introduces Fast Calibrated Explanations, a method designed for generating rapid, uncertainty-aware explanations for machine learning models. By incorporating perturbation techniques from ConformaSight - a global explanation framework - into the core elements of Calibrated Explanations (CE), we achieve significant speedups. These core elements include local feature importance with calibrated predictions, both of which retain uncertainty quantification. While the new method sacrifices a small degree of detail, it excels in computational efficiency, making it ideal for high-stakes, real-time applications. Fast Calibrated Explanations are applicable to probabilistic explanations in classification and thresholded regression tasks, where they provide the likelihood of a target being above or below a user-defined threshold. This approach maintains the versatility of CE for both classification and probabilistic regression, making it suitable for a range of predictive tasks where uncertainty quantification is crucial.
Ensured: Explanations for Decreasing the Epistemic Uncertainty in Predictions
Oct 07, 2024This paper addresses a significant gap in explainable AI: the necessity of interpreting epistemic uncertainty in model explanations. Although current methods mainly focus on explaining predictions, with some including uncertainty, they fail to provide guidance on how to reduce the inherent uncertainty in these predictions. To overcome this challenge, we introduce new types of explanations that specifically target epistemic uncertainty. These include ensured explanations, which highlight feature modifications that can reduce uncertainty, and categorisation of uncertain explanations counter-potential, semi-potential, and super-potential which explore alternative scenarios. Our work emphasises that epistemic uncertainty adds a crucial dimension to explanation quality, demanding evaluation based not only on prediction probability but also on uncertainty reduction. We introduce a new metric, ensured ranking, designed to help users identify the most reliable explanations by balancing trade-offs between uncertainty, probability, and competing alternative explanations. Furthermore, we extend the Calibrated Explanations method, incorporating tools that visualise how changes in feature values impact epistemic uncertainty. This enhancement provides deeper insights into model behaviour, promoting increased interpretability and appropriate trust in scenarios involving uncertain predictions.
On the Definition of Appropriate Trust and the Tools that Come with it
Sep 21, 2023Evaluating the efficiency of human-AI interactions is challenging, including subjective and objective quality aspects. With the focus on the human experience of the explanations, evaluations of explanation methods have become mostly subjective, making comparative evaluations almost impossible and highly linked to the individual user. However, it is commonly agreed that one aspect of explanation quality is how effectively the user can detect if the predictions are trustworthy and correct, i.e., if the explanations can increase the user's appropriate trust in the model. This paper starts with the definitions of appropriate trust from the literature. It compares the definitions with model performance evaluation, showing the strong similarities between appropriate trust and model performance evaluation. The paper's main contribution is a novel approach to evaluating appropriate trust by taking advantage of the likenesses between definitions. The paper offers several straightforward evaluation methods for different aspects of user performance, including suggesting a method for measuring uncertainty and appropriate trust in regression.
Calibrated Explanations for Regression
Sep 01, 2023Artificial Intelligence (AI) is often an integral part of modern decision support systems (DSSs). The best-performing predictive models used in AI-based DSSs lack transparency. Explainable Artificial Intelligence (XAI) aims to create AI systems that can explain their rationale to human users. Local explanations in XAI can provide information about the causes of individual predictions in terms of feature importance. However, a critical drawback of existing local explanation methods is their inability to quantify the uncertainty associated with a feature's importance. This paper introduces an extension of a feature importance explanation method, Calibrated Explanations (CE), previously only supporting classification, with support for standard regression and probabilistic regression, i.e., the probability that the target is above an arbitrary threshold. The extension for regression keeps all the benefits of CE, such as calibration of the prediction from the underlying model with confidence intervals, uncertainty quantification of feature importance, and allows both factual and counterfactual explanations. CE for standard regression provides fast, reliable, stable, and robust explanations. CE for probabilistic regression provides an entirely new way of creating probabilistic explanations from any ordinary regression model and with a dynamic selection of thresholds. The performance of CE for probabilistic regression regarding stability and speed is comparable to LIME. The method is model agnostic with easily understood conditional rules. An implementation in Python is freely available on GitHub and for installation using pip making the results in this paper easily replicable.
A Meta Survey of Quality Evaluation Criteria in Explanation Methods
Mar 25, 2022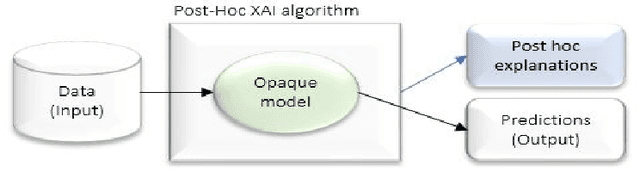
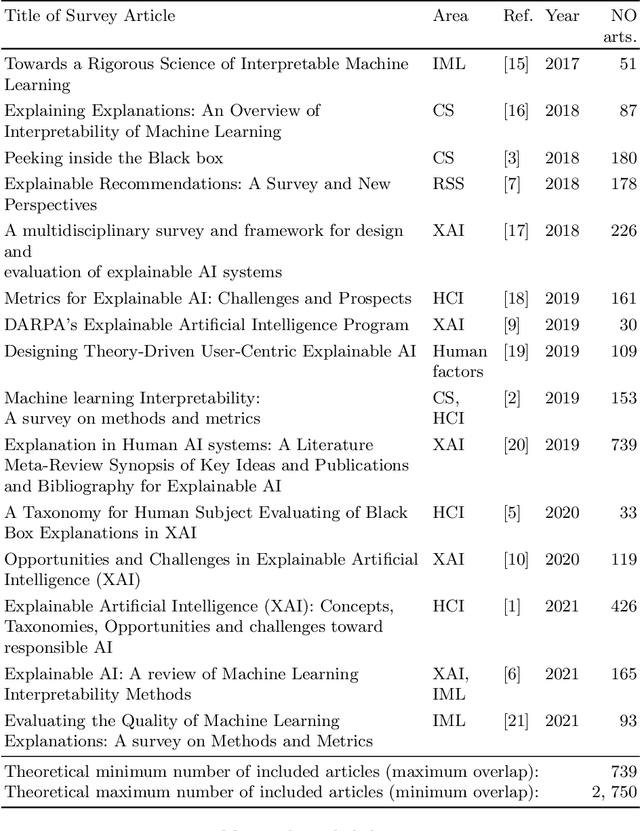
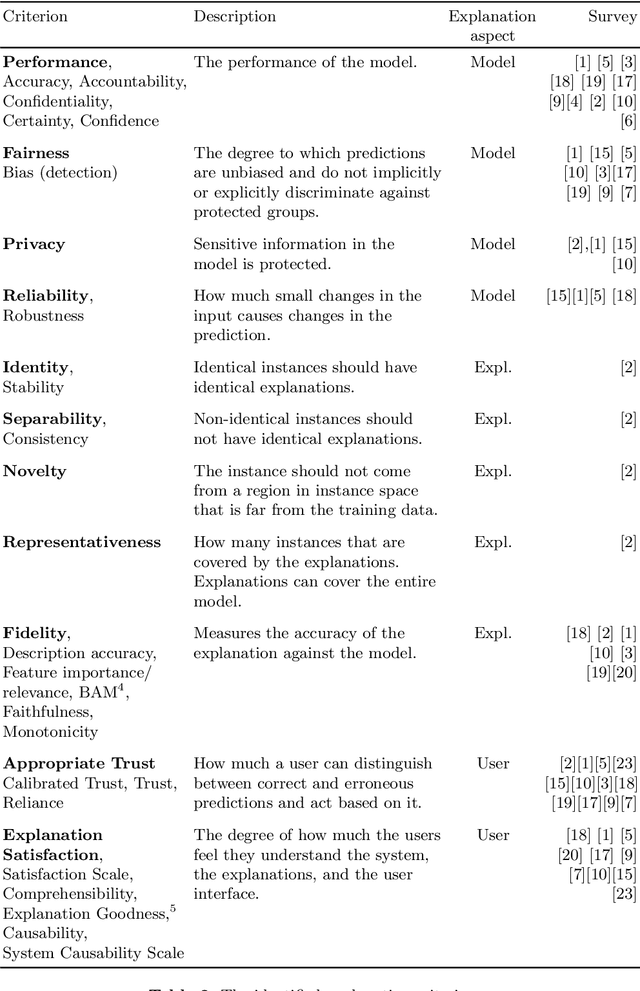
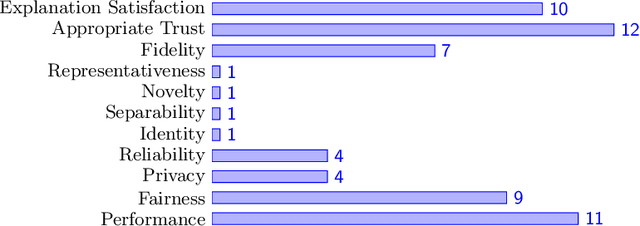
Explanation methods and their evaluation have become a significant issue in explainable artificial intelligence (XAI) due to the recent surge of opaque AI models in decision support systems (DSS). Since the most accurate AI models are opaque with low transparency and comprehensibility, explanations are essential for bias detection and control of uncertainty. There are a plethora of criteria to choose from when evaluating explanation method quality. However, since existing criteria focus on evaluating single explanation methods, it is not obvious how to compare the quality of different methods. This lack of consensus creates a critical shortage of rigour in the field, although little is written about comparative evaluations of explanation methods. In this paper, we have conducted a semi-systematic meta-survey over fifteen literature surveys covering the evaluation of explainability to identify existing criteria usable for comparative evaluations of explanation methods. The main contribution in the paper is the suggestion to use appropriate trust as a criterion to measure the outcome of the subjective evaluation criteria and consequently make comparative evaluations possible. We also present a model of explanation quality aspects. In the model, criteria with similar definitions are grouped and related to three identified aspects of quality; model, explanation, and user. We also notice four commonly accepted criteria (groups) in the literature, covering all aspects of explanation quality: Performance, appropriate trust, explanation satisfaction, and fidelity. We suggest the model be used as a chart for comparative evaluations to create more generalisable research in explanation quality.