 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDBSCAN++: Towards fast and scalable density clustering
Oct 31, 2018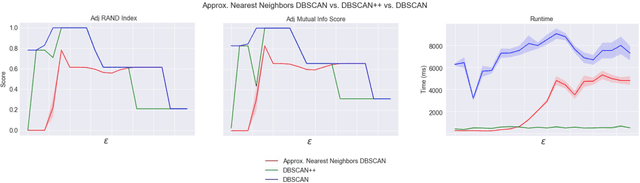
DBSCAN is a classical density-based clustering procedure which has had tremendous practical relevance. However, it implicitly needs to compute the empirical density for each sample point, leading to a quadratic worst-case time complexity, which may be too slow on large datasets. We propose DBSCAN++, a simple modification of DBSCAN which only requires computing the densities for a subset of the points. We show empirically that, compared to traditional DBSCAN, DBSCAN++ can provide not only competitive performance but also added robustness in the bandwidth hyperparameter while taking a fraction of the runtime. We also present statistical consistency guarantees showing the trade-off between computational cost and estimation rates. Surprisingly, up to a certain point, we can enjoy the same estimation rates while lowering computational cost, showing that DBSCAN++ is a sub-quadratic algorithm that attains minimax optimal rates for level-set estimation, a quality that may be of independent interest.
To Trust Or Not To Trust A Classifier
Oct 26, 2018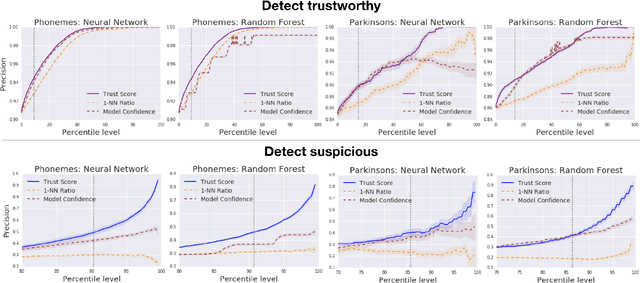
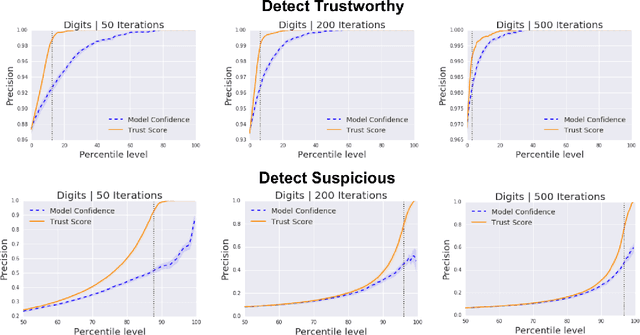
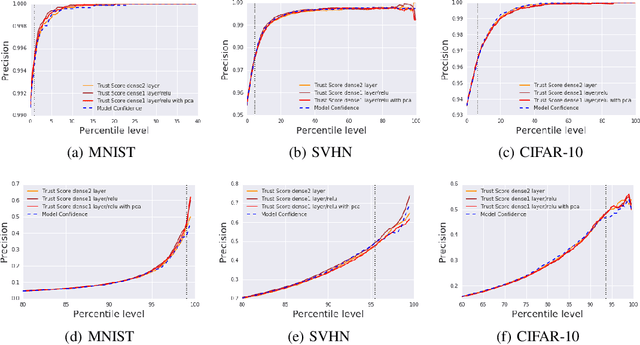
Knowing when a classifier's prediction can be trusted is useful in many applications and critical for safely using AI. While the bulk of the effort in machine learning research has been towards improving classifier performance, understanding when a classifier's predictions should and should not be trusted has received far less attention. The standard approach is to use the classifier's discriminant or confidence score; however, we show there exists an alternative that is more effective in many situations. We propose a new score, called the trust score, which measures the agreement between the classifier and a modified nearest-neighbor classifier on the testing example. We show empirically that high (low) trust scores produce surprisingly high precision at identifying correctly (incorrectly) classified examples, consistently outperforming the classifier's confidence score as well as many other baselines. Further, under some mild distributional assumptions, we show that if the trust score for an example is high (low), the classifier will likely agree (disagree) with the Bayes-optimal classifier. Our guarantees consist of non-asymptotic rates of statistical consistency under various nonparametric settings and build on recent developments in topological data analysis.
Training Well-Generalizing Classifiers for Fairness Metrics and Other Data-Dependent Constraints
Sep 28, 2018

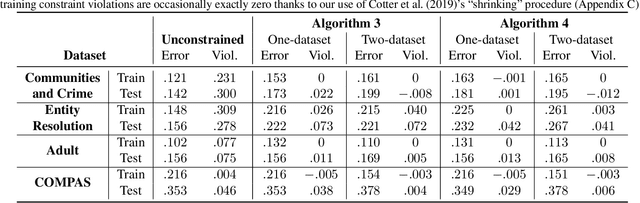
Classifiers can be trained with data-dependent constraints to satisfy fairness goals, reduce churn, achieve a targeted false positive rate, or other policy goals. We study the generalization performance for such constrained optimization problems, in terms of how well the constraints are satisfied at evaluation time, given that they are satisfied at training time. To improve generalization performance, we frame the problem as a two-player game where one player optimizes the model parameters on a training dataset, and the other player enforces the constraints on an independent validation dataset. We build on recent work in two-player constrained optimization to show that if one uses this two-dataset approach, then constraint generalization can be significantly improved. As we illustrate experimentally, this approach works not only in theory, but also in practice.
Two-Player Games for Efficient Non-Convex Constrained Optimization
Sep 28, 2018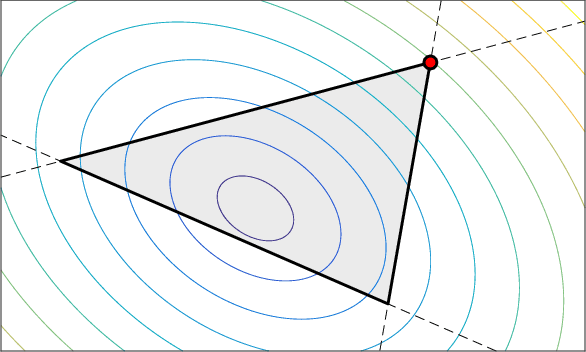

In recent years, constrained optimization has become increasingly relevant to the machine learning community, with applications including Neyman-Pearson classification, robust optimization, and fair machine learning. A natural approach to constrained optimization is to optimize the Lagrangian, but this is not guaranteed to work in the non-convex setting, and, if using a first-order method, cannot cope with non-differentiable constraints (e.g. constraints on rates or proportions). The Lagrangian can be interpreted as a two-player game played between a player who seeks to optimize over the model parameters, and a player who wishes to maximize over the Lagrange multipliers. We propose a non-zero-sum variant of the Lagrangian formulation that can cope with non-differentiable--even discontinuous--constraints, which we call the "proxy-Lagrangian". The first player minimizes external regret in terms of easy-to-optimize "proxy constraints", while the second player enforces the original constraints by minimizing swap regret. For this new formulation, as for the Lagrangian in the non-convex setting, the result is a stochastic classifier. For both the proxy-Lagrangian and Lagrangian formulations, however, we prove that this classifier, instead of having unbounded size, can be taken to be a distribution over no more than m+1 models (where m is the number of constraints). This is a significant improvement in practical terms.
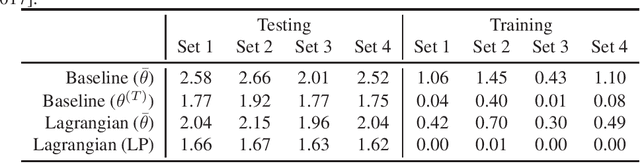
Optimization with Non-Differentiable Constraints with Applications to Fairness, Recall, Churn, and Other Goals
Sep 11, 2018
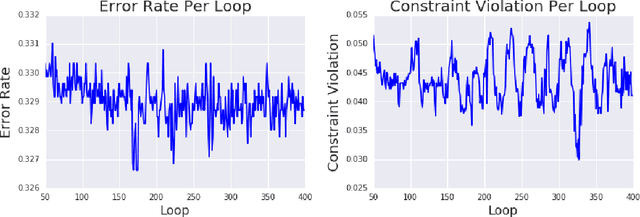
We show that many machine learning goals, such as improved fairness metrics, can be expressed as constraints on the model's predictions, which we call rate constraints. We study the problem of training non-convex models subject to these rate constraints (or any non-convex and non-differentiable constraints). In the non-convex setting, the standard approach of Lagrange multipliers may fail. Furthermore, if the constraints are non-differentiable, then one cannot optimize the Lagrangian with gradient-based methods. To solve these issues, we introduce the proxy-Lagrangian formulation. This new formulation leads to an algorithm that produces a stochastic classifier by playing a two-player non-zero-sum game solving for what we call a semi-coarse correlated equilibrium, which in turn corresponds to an approximately optimal and feasible solution to the constrained optimization problem. We then give a procedure which shrinks the randomized solution down to one that is a mixture of at most $m+1$ deterministic solutions, given $m$ constraints. This culminates in algorithms that can solve non-convex constrained optimization problems with possibly non-differentiable and non-convex constraints with theoretical guarantees. We provide extensive experimental results enforcing a wide range of policy goals including different fairness metrics, and other goals on accuracy, coverage, recall, and churn.
Interpretable Set Functions
May 31, 2018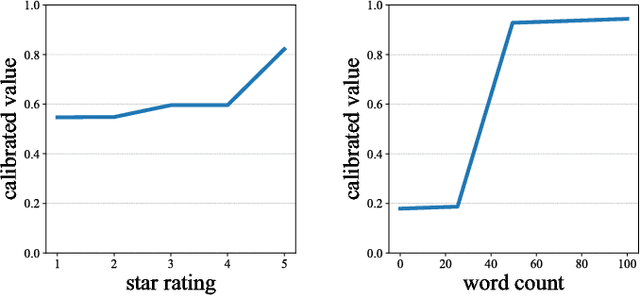

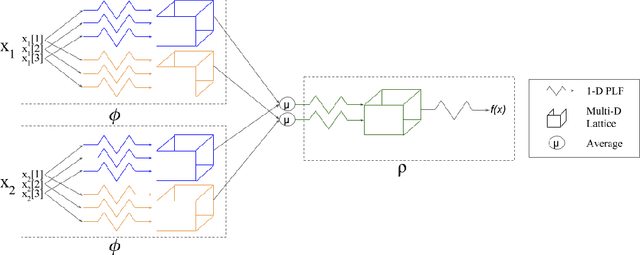
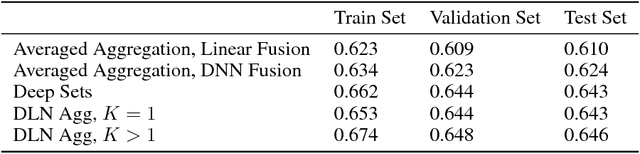
We propose learning flexible but interpretable functions that aggregate a variable-length set of permutation-invariant feature vectors to predict a label. We use a deep lattice network model so we can architect the model structure to enhance interpretability, and add monotonicity constraints between inputs-and-outputs. We then use the proposed set function to automate the engineering of dense, interpretable features from sparse categorical features, which we call semantic feature engine. Experiments on real-world data show the achieved accuracy is similar to deep sets or deep neural networks, and is easier to debug and understand.
Quickshift++: Provably Good Initializations for Sample-Based Mean Shift
May 21, 2018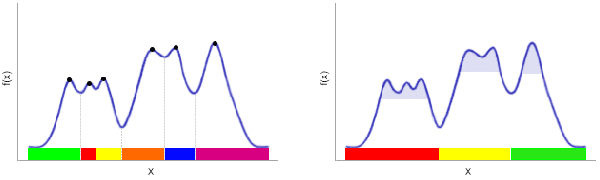
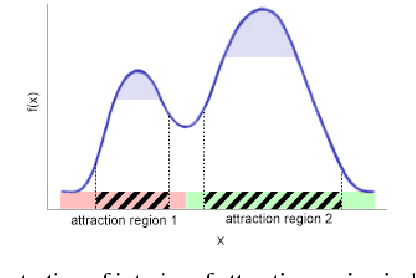
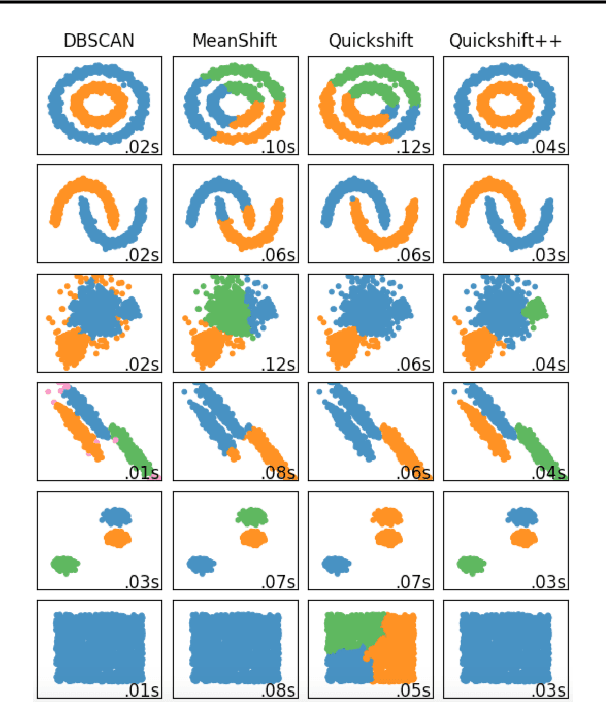
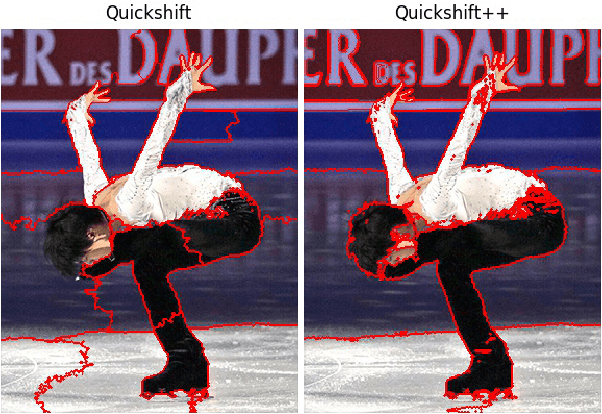
We provide initial seedings to the Quick Shift clustering algorithm, which approximate the locally high-density regions of the data. Such seedings act as more stable and expressive cluster-cores than the singleton modes found by Quick Shift. We establish statistical consistency guarantees for this modification. We then show strong clustering performance on real datasets as well as promising applications to image segmentation.
Nonparametric Stochastic Contextual Bandits
Jan 05, 2018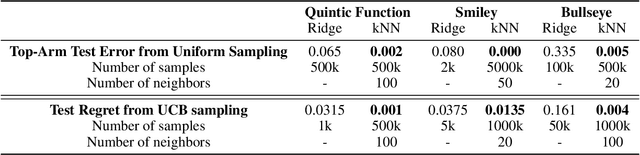

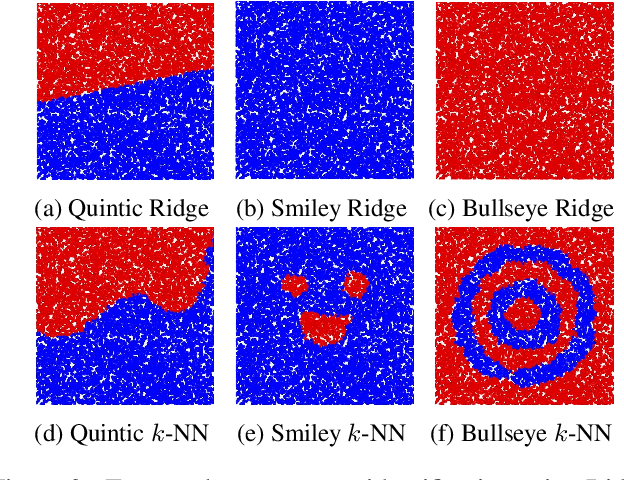
We analyze the $K$-armed bandit problem where the reward for each arm is a noisy realization based on an observed context under mild nonparametric assumptions. We attain tight results for top-arm identification and a sublinear regret of $\widetilde{O}\Big(T^{\frac{1+D}{2+D}}\Big)$, where $D$ is the context dimension, for a modified UCB algorithm that is simple to implement ($k$NN-UCB). We then give global intrinsic dimension dependent and ambient dimension independent regret bounds. We also discuss recovering topological structures within the context space based on expected bandit performance and provide an extension to infinite-armed contextual bandits. Finally, we experimentally show the improvement of our algorithm over existing multi-armed bandit approaches for both simulated tasks and MNIST image classification.
On the Consistency of Quick Shift
Dec 23, 2017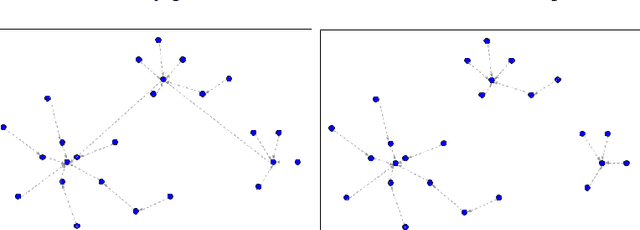
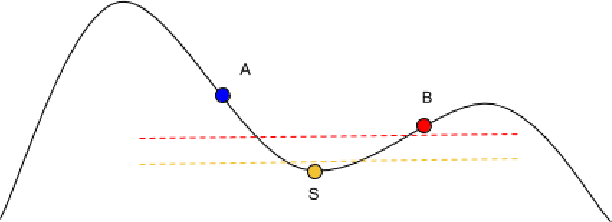
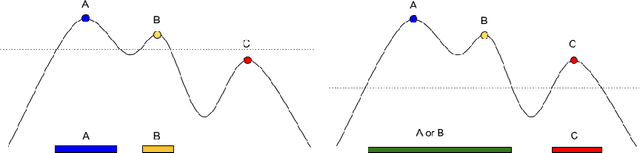

Quick Shift is a popular mode-seeking and clustering algorithm. We present finite sample statistical consistency guarantees for Quick Shift on mode and cluster recovery under mild distributional assumptions. We then apply our results to construct a consistent modal regression algorithm.
Density Level Set Estimation on Manifolds with DBSCAN
Jul 12, 2017We show that DBSCAN can estimate the connected components of the $\lambda$-density level set $\{ x : f(x) \ge \lambda\}$ given $n$ i.i.d. samples from an unknown density $f$. We characterize the regularity of the level set boundaries using parameter $\beta > 0$ and analyze the estimation error under the Hausdorff metric. When the data lies in $\mathbb{R}^D$ we obtain a rate of $\widetilde{O}(n^{-1/(2\beta + D)})$, which matches known lower bounds up to logarithmic factors. When the data lies on an embedded unknown $d$-dimensional manifold in $\mathbb{R}^D$, then we obtain a rate of $\widetilde{O}(n^{-1/(2\beta + d\cdot \max\{1, \beta \})})$. Finally, we provide adaptive parameter tuning in order to attain these rates with no a priori knowledge of the intrinsic dimension, density, or $\beta$.