 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-Learning with Adaptive Hyperparameters
Oct 31, 2020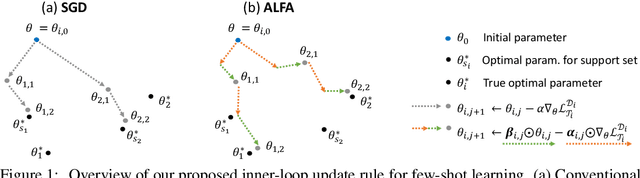
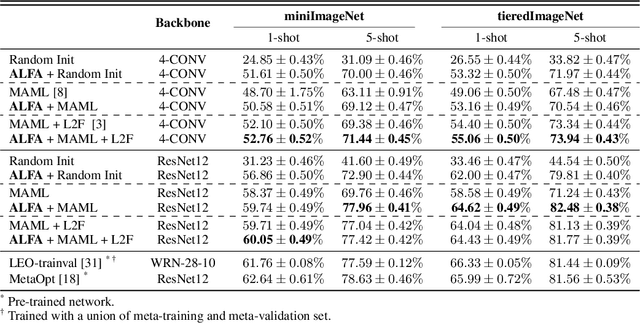
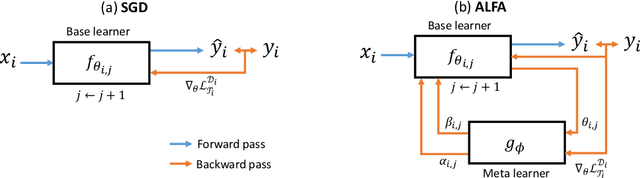
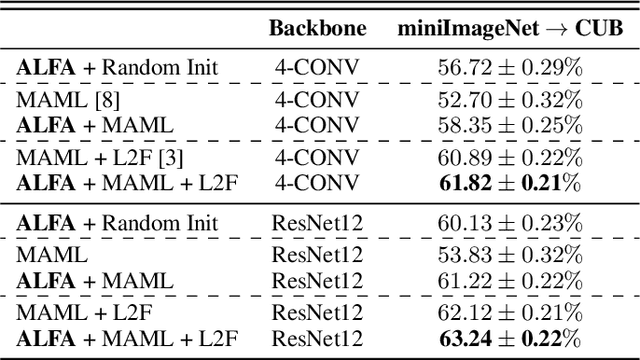
Despite its popularity, several recent works question the effectiveness of MAML when test tasks are different from training tasks, thus suggesting various task-conditioned methodology to improve the initialization. Instead of searching for better task-aware initialization, we focus on a complementary factor in MAML framework, inner-loop optimization (or fast adaptation). Consequently, we propose a new weight update rule that greatly enhances the fast adaptation process. Specifically, we introduce a small meta-network that can adaptively generate per-step hyperparameters: learning rate and weight decay coefficients. The experimental results validate that the Adaptive Learning of hyperparameters for Fast Adaptation (ALFA) is the equally important ingredient that was often neglected in the recent few-shot learning approaches. Surprisingly, fast adaptation from random initialization with ALFA can already outperform MAML.
Fine-Grained Neural Architecture Search
Nov 18, 2019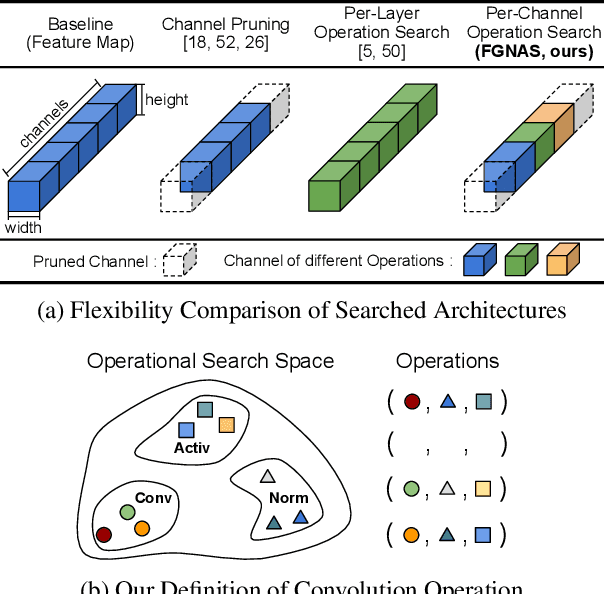

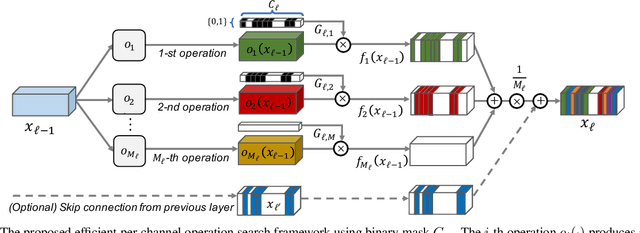

We present an elegant framework of fine-grained neural architecture search (FGNAS), which allows to employ multiple heterogeneous operations within a single layer and can even generate compositional feature maps using several different base operations. FGNAS runs efficiently in spite of significantly large search space compared to other methods because it trains networks end-to-end by a stochastic gradient descent method. Moreover, the proposed framework allows to optimize the network under predefined resource constraints in terms of number of parameters, FLOPs and latency. FGNAS has been applied to two crucial applications in resource demanding computer vision tasks---large-scale image classification and image super-resolution---and demonstrates the state-of-the-art performance through flexible operation search and channel pruning.
Enhanced Deep Residual Networks for Single Image Super-Resolution
Jul 10, 2017

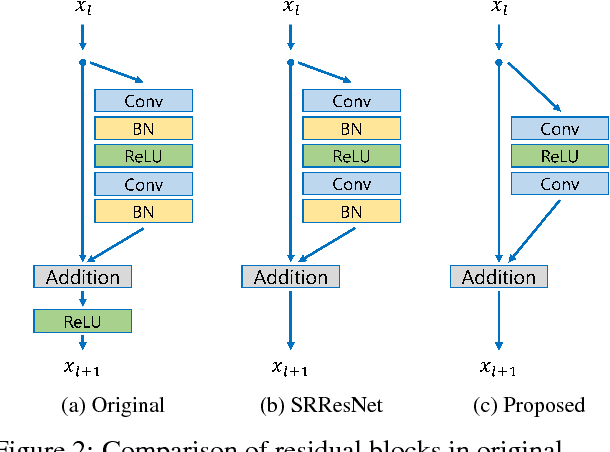

Recent research on super-resolution has progressed with the development of deep convolutional neural networks (DCNN). In particular, residual learning techniques exhibit improved performance. In this paper, we develop an enhanced deep super-resolution network (EDSR) with performance exceeding those of current state-of-the-art SR methods. The significant performance improvement of our model is due to optimization by removing unnecessary modules in conventional residual networks. The performance is further improved by expanding the model size while we stabilize the training procedure. We also propose a new multi-scale deep super-resolution system (MDSR) and training method, which can reconstruct high-resolution images of different upscaling factors in a single model. The proposed methods show superior performance over the state-of-the-art methods on benchmark datasets and prove its excellence by winning the NTIRE2017 Super-Resolution Challenge.