 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Contrastive Learning for Cross-domain Hyperspectral Image Representation
Feb 08, 2022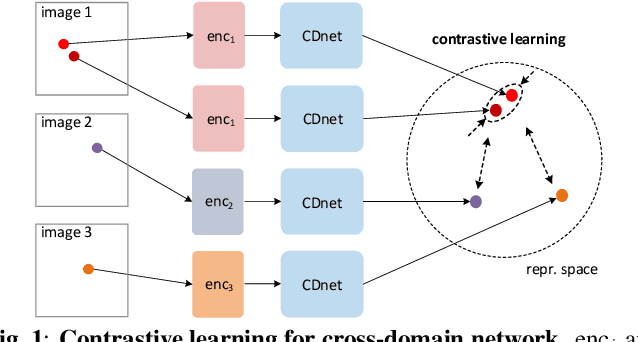
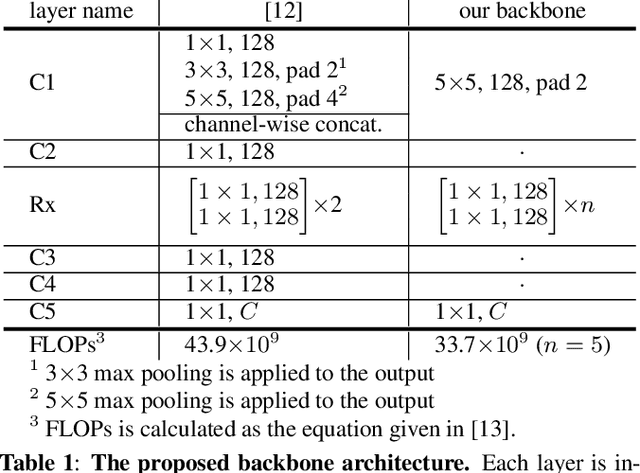
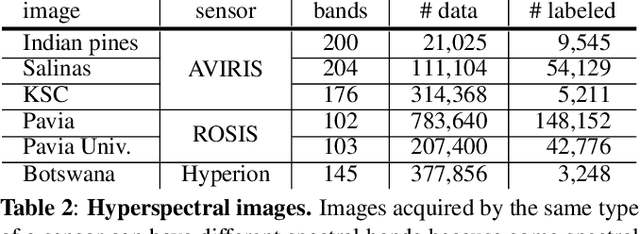
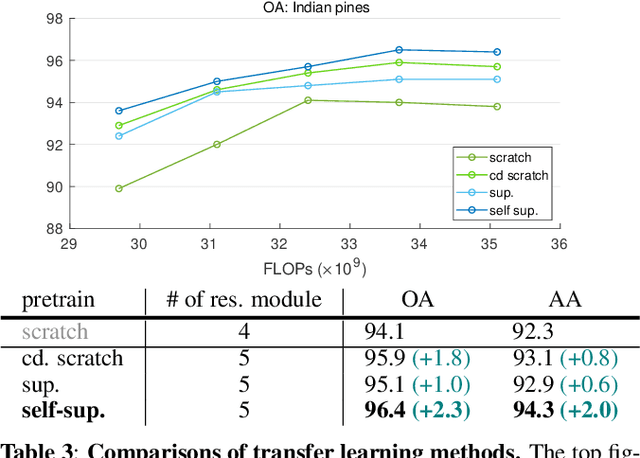
Recently, self-supervised learning has attracted attention due to its remarkable ability to acquire meaningful representations for classification tasks without using semantic labels. This paper introduces a self-supervised learning framework suitable for hyperspectral images that are inherently challenging to annotate. The proposed framework architecture leverages cross-domain CNN, allowing for learning representations from different hyperspectral images with varying spectral characteristics and no pixel-level annotation. In the framework, cross-domain representations are learned via contrastive learning where neighboring spectral vectors in the same image are clustered together in a common representation space encompassing multiple hyperspectral images. In contrast, spectral vectors in different hyperspectral images are separated into distinct clusters in the space. To verify that the learned representation through contrastive learning is effectively transferred into a downstream task, we perform a classification task on hyperspectral images. The experimental results demonstrate the advantage of the proposed self-supervised representation over models trained from scratch or other transfer learning methods.
Validation of object detection in UAV-based images using synthetic data
Jan 17, 2022Object detection is increasingly used onboard Unmanned Aerial Vehicles (UAV) for various applications; however, the machine learning (ML) models for UAV-based detection are often validated using data curated for tasks unrelated to the UAV application. This is a concern because training neural networks on large-scale benchmarks have shown excellent capability in generic object detection tasks, yet conventional training approaches can lead to large inference errors for UAV-based images. Such errors arise due to differences in imaging conditions between images from UAVs and images in training. To overcome this problem, we characterize boundary conditions of ML models, beyond which the models exhibit rapid degradation in detection accuracy. Our work is focused on understanding the impact of different UAV-based imaging conditions on detection performance by using synthetic data generated using a game engine. Properties of the game engine are exploited to populate the synthetic datasets with realistic and annotated images. Specifically, it enables the fine control of various parameters, such as camera position, view angle, illumination conditions, and object pose. Using the synthetic datasets, we analyze detection accuracy in different imaging conditions as a function of the above parameters. We use three well-known neural network models with different model complexity in our work. In our experiment, we observe and quantify the following: 1) how detection accuracy drops as the camera moves toward the nadir-view region; 2) how detection accuracy varies depending on different object poses, and 3) the degree to which the robustness of the models changes as illumination conditions vary.
SENSE: Semantically Enhanced Node Sequence Embedding
Nov 07, 2019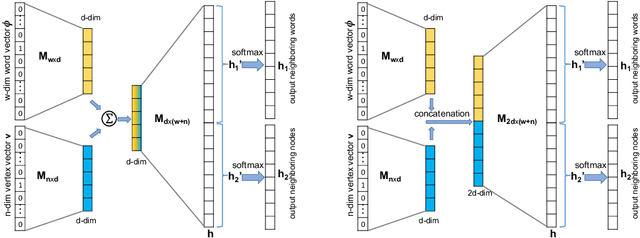
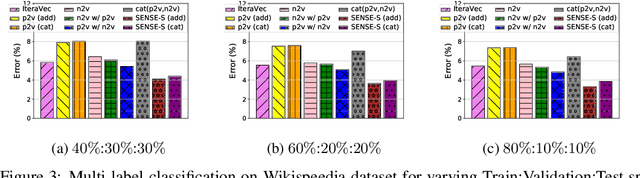
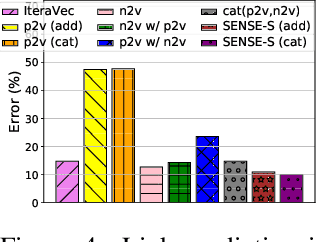
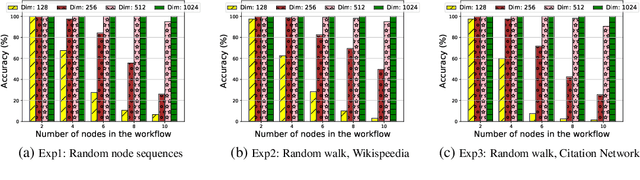
Effectively capturing graph node sequences in the form of vector embeddings is critical to many applications. We achieve this by (i) first learning vector embeddings of single graph nodes and (ii) then composing them to compactly represent node sequences. Specifically, we propose SENSE-S (Semantically Enhanced Node Sequence Embedding - for Single nodes), a skip-gram based novel embedding mechanism, for single graph nodes that co-learns graph structure as well as their textual descriptions. We demonstrate that SENSE-S vectors increase the accuracy of multi-label classification tasks by up to 50% and link-prediction tasks by up to 78% under a variety of scenarios using real datasets. Based on SENSE-S, we next propose generic SENSE to compute composite vectors that represent a sequence of nodes, where preserving the node order is important. We prove that this approach is efficient in embedding node sequences, and our experiments on real data confirm its high accuracy in node order decoding.
Delving into Robust Object Detection from Unmanned Aerial Vehicles: A Deep Nuisance Disentanglement Approach
Aug 11, 2019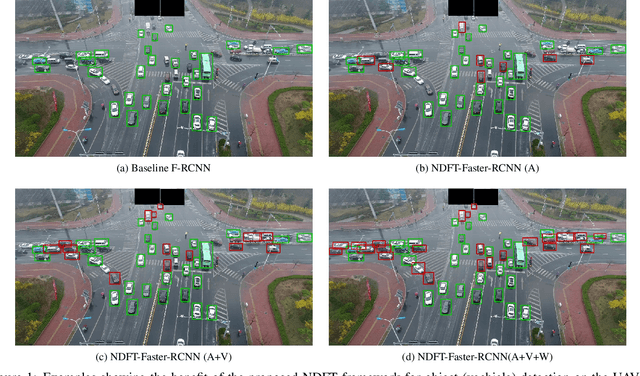
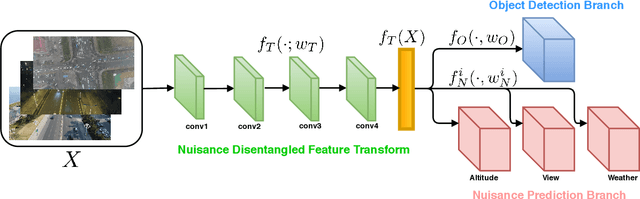


Object detection from images captured by Unmanned Aerial Vehicles (UAVs) is becoming increasingly useful. Despite the great success of the generic object detection methods trained on ground-to-ground images, a huge performance drop is observed when they are directly applied to images captured by UAVs. The unsatisfactory performance is owing to many UAV-specific nuisances, such as varying flying altitudes, adverse weather conditions, dynamically changing viewing angles, etc. Those nuisances constitute a large number of fine-grained domains, across which the detection model has to stay robust. Fortunately, UAVs will record meta-data that depict those varying attributes, which are either freely available along with the UAV images, or can be easily obtained. We propose to utilize those free meta-data in conjunction with associated UAV images to learn domain-robust features via an adversarial training framework dubbed Nuisance Disentangled Feature Transform (NDFT), for the specific challenging problem of object detection in UAV images, achieving a substantial gain in robustness to those nuisances. We demonstrate the effectiveness of our proposed algorithm, by showing state-of-the-art performance (single model) on two existing UAV-based object detection benchmarks. The code is available at https://github.com/TAMU-VITA/UAV-NDFT.
Semantics to Space(S2S): Embedding semantics into spatial space for zero-shot verb-object query inferencing
Jun 13, 2019
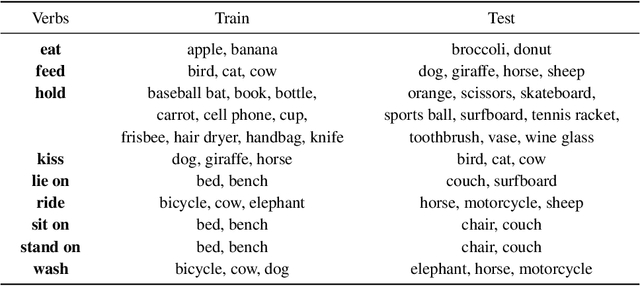
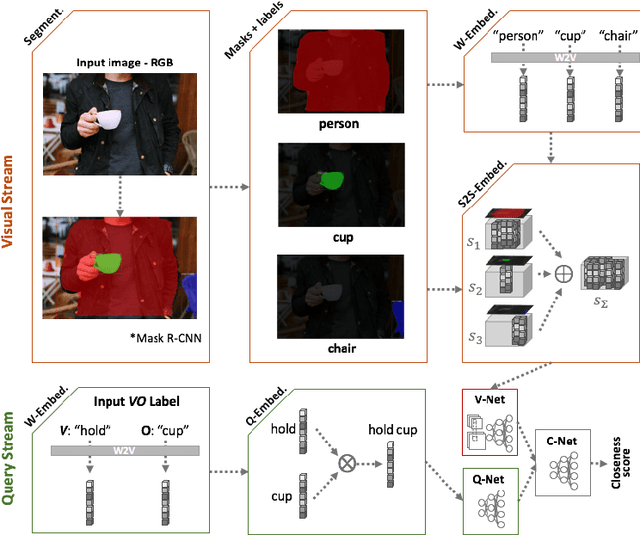

We present a novel deep zero-shot learning (ZSL) model for inferencing human-object-interaction with verb-object (VO) query. While the previous ZSL approaches only use the semantic/textual information to be fed into the query stream, we seek to incorporate and embed the semantics into the visual representation stream as well. Our approach is powered by Semantics-to-Space (S2S) architecture where semantics derived from the residing objects are embedded into a spatial space. This architecture allows the co-capturing of the semantic attributes of the human and the objects along with their location/size/silhouette information. As this is the first attempt to address the zero-shot human-object-interaction inferencing with VO query, we have constructed a new dataset, Verb-Transferability 60 (VT60). VT60 provides 60 different VO pairs with overlapping verbs tailored for testing ZSL approaches with VO query. Experimental evaluations show that our approach not only outperforms the state-of-the-art, but also shows the capability of consistently improving performance regardless of which ZSL baseline architecture is used.
Integrating Propositional and Relational Label Side Information for Hierarchical Zero-Shot Image Classification
Feb 14, 2019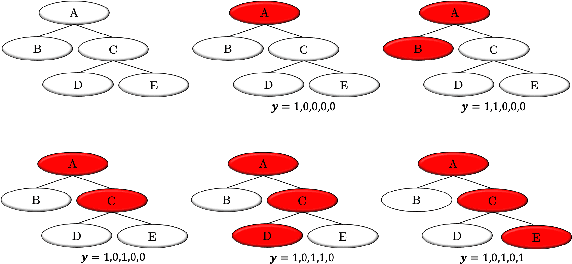
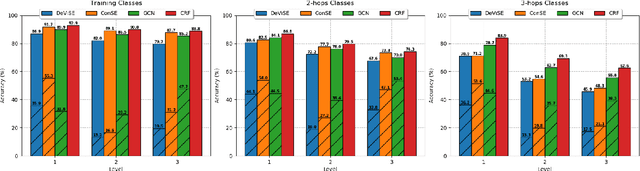

Zero-shot learning (ZSL) is one of the most extreme forms of learning from scarce labeled data. It enables predicting that images belong to classes for which no labeled training instances are available. In this paper, we present a new ZSL framework that leverages both label attribute side information and a semantic label hierarchy. We present two methods, lifted zero-shot prediction and a custom conditional random field (CRF) model, that integrate both forms of side information. We propose benchmark tasks for this framework that focus on making predictions across a range of semantic levels. We show that lifted zero-shot prediction can dramatically outperform baseline methods when making predictions within specified semantic levels, and that the probability distribution provided by the CRF model can be leveraged to yield further performance improvements when making unconstrained predictions over the hierarchy.
S-DOD-CNN: Doubly Injecting Spatially-Preserved Object Information for Event Recognition
Feb 11, 2019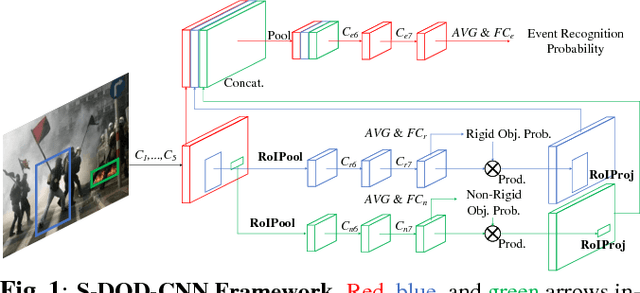
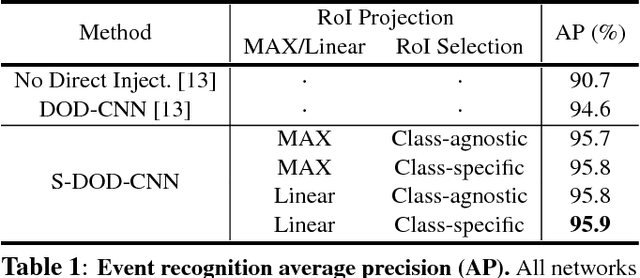
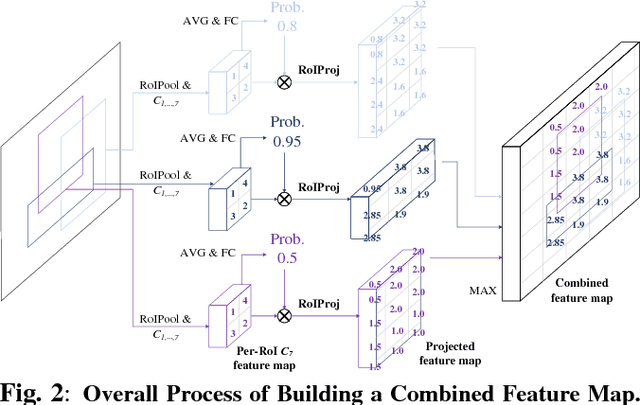

We present a novel event recognition approach called Spatially-preserved Doubly-injected Object Detection CNN (S-DOD-CNN), which incorporates the spatially preserved object detection information in both a direct and an indirect way. Indirect injection is carried out by simply sharing the weights between the object detection modules and the event recognition module. Meanwhile, our novelty lies in the fact that we have preserved the spatial information for the direct injection. Once multiple regions-of-intereset (RoIs) are acquired, their feature maps are computed and then projected onto a spatially-preserving combined feature map using one of the four RoI Projection approaches we present. In our architecture, combined feature maps are generated for object detection which are directly injected to the event recognition module. Our method provides the state-of-the-art accuracy for malicious event recognition.
Is Pretraining Necessary for Hyperspectral Image Classification?
Jan 24, 2019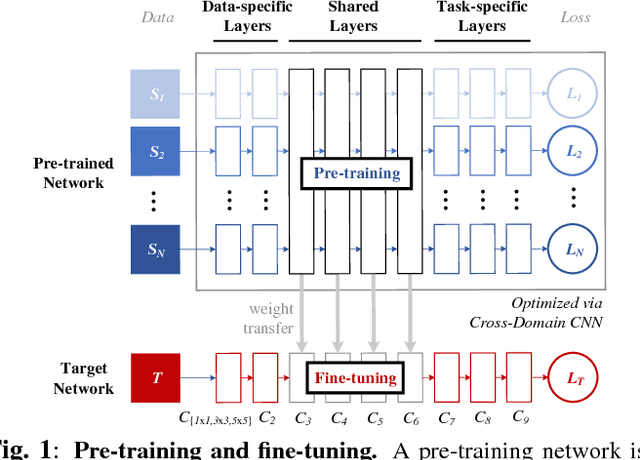
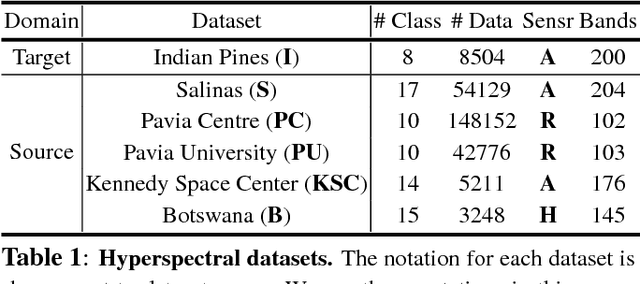

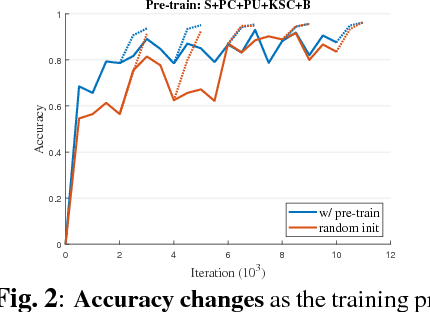
We address two questions for training a convolutional neural network (CNN) for hyperspectral image classification: i) is it possible to build a pre-trained network? and ii) is the pre-training effective in furthering the performance? To answer the first question, we have devised an approach that pre-trains a network on multiple source datasets that differ in their hyperspectral characteristics and fine-tunes on a target dataset. This approach effectively resolves the architectural issue that arises when transferring meaningful information between the source and the target networks. To answer the second question, we carried out several ablation experiments. Based on the experimental results, a network trained from scratch performs as good as a network fine-tuned from a pre-trained network. However, we observed that pre-training the network has its own advantage in achieving better performances when deeper networks are required.
Discovering and Generating Hard Examples for Training a Red Tide Detector
Dec 13, 2018
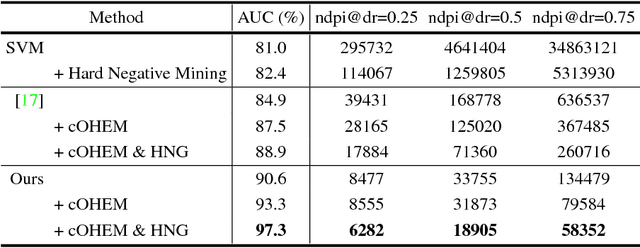


Currently, accurate detection of natural phenomena, such as red tide, that adversely affect wildlife and human, using satellite images has been increasingly utilized. However, red tide detection on satellite images still remains a very hard task due to unpredictable nature of red tide occurrence, extreme sparsity of red tide samples, difficulties in accurate groundtruthing, etc. In this paper, we aim to tackle both the data sparsity and groundtruthing issues by primarily addressing two challenges: i) extreme data imbalance between red tide and non-red tide examples and ii) significant lack of hard examples of non-red tide that can enhance detection performance. In the proposed work, we devise a 9-layer fully convolutional network jointly optimized with two plug-in modules tailored to overcoming the two challenges: i) cascaded online hard example mining (cOHEM) to ease the data imbalance and ii) a hard negative example generator (HNG) to supplement the hard negative (non-red tide) examples. Our proposed network jointly trained with cOHEM and HNG provides state-of-the-art red tide detection accuracy on GOCI satellite images.
DOD-CNN: Doubly-injecting Object Information for Event Recognition
Nov 07, 2018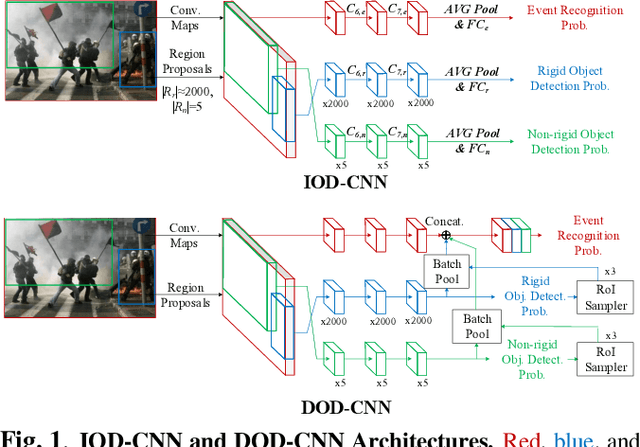

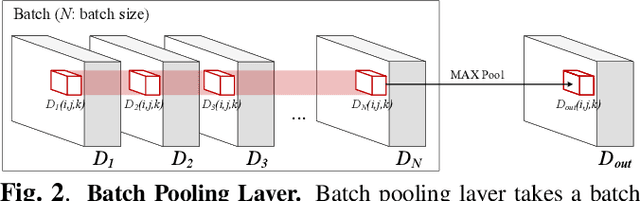
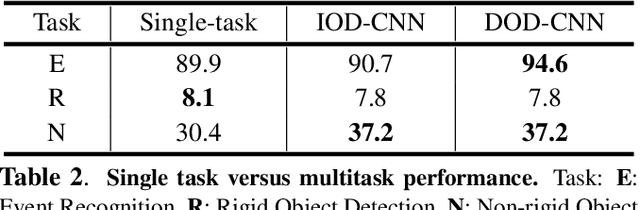
Recognizing an event in an image can be enhanced by detecting relevant objects in two ways: 1) indirectly utilizing object detection information within the unified architecture or 2) directly making use of the object detection output results. We introduce a novel approach, referred to as Doubly-injected Object Detection CNN (DOD-CNN), exploiting the object information in both ways for the task of event recognition. The structure of this network is inspired by the Integrated Object Detection CNN (IOD-CNN) where object information is indirectly exploited by the event recognition module through the shared portion of the network. In the DOD-CNN architecture, the intermediate object detection outputs are directly injected into the event recognition network while keeping the indirect sharing structure inherited from the IOD-CNN, thus being `doubly-injected'. We also introduce a batch pooling layer which constructs one representative feature map from multiple object hypotheses. We have demonstrated the effectiveness of injecting the object detection information in two different ways in the task of malicious event recognition.