 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting AI-Generated Videos with Spiking Neural Networks
May 07, 2026Modern AI-generated videos are photorealistic at the single-frame level, leaving inter-frame dynamics as the main remaining axis for detection. Existing detectors typically handle this temporal evidence in three ways: feeding the full frame sequence to a generic temporal backbone, reducing one dominant temporal cue to fixed video-level descriptors, or comparing temporal features to real-video statistics through a detection metric. These strategies degrade sharply under cross-generator evaluation, where artifact type and timescale vary across generators. On caption-paired benchmark, GenVidBench, we identify two signatures that prior detectors do not jointly exploit: AI-generated videos exhibit smoother frame-to-frame temporal residuals at the pixel level, and more compact trajectories in the semantic feature space, indicating a temporal smoothness gap at both levels. We further observe that, when raw video is fed into a Spiking Neural Networks (SNNs), fake clips elicit firing predominantly at object and motion boundaries, unlike real clips, suggesting that the SNN responds to temporal artifacts localized at edges. These cues are sparse, asynchronous, and concentrated at moments of change, which makes SNNs a natural choice for this task: their event-driven, sparsely-activated dynamics align with the structure of the residual signal in a way that dense ANN backbones do not. Building on this observation, we propose MAST, a detector that processes multi-channel temporal residuals with a spike-driven temporal branch alongside a frozen semantic encoder for cross-generator generalization. On the GenVideo benchmark, MAST achieves 93.14\% mean accuracy across 10 unseen generators under strict cross-generator evaluation, matching or surpassing the strongest ANN-based detectors and demonstrating the practical applicability of SNNs to AI-generated video detection.
Balancing Domain Experts for Long-Tailed Camera-Trap Recognition
Feb 16, 2022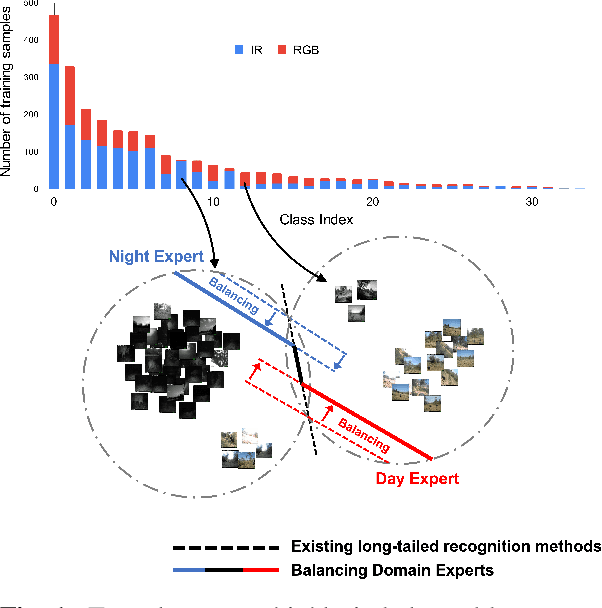
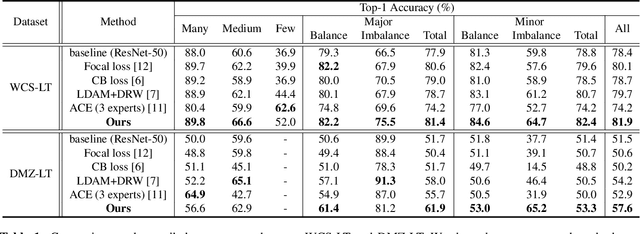
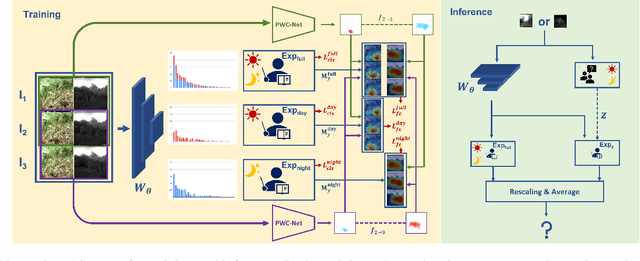
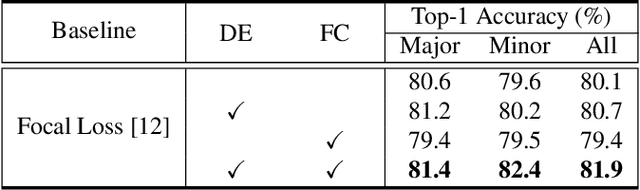
Label distributions in camera-trap images are highly imbalanced and long-tailed, resulting in neural networks tending to be biased towards head-classes that appear frequently. Although long-tail learning has been extremely explored to address data imbalances, few studies have been conducted to consider camera-trap characteristics, such as multi-domain and multi-frame setup. Here, we propose a unified framework and introduce two datasets for long-tailed camera-trap recognition. We first design domain experts, where each expert learns to balance imperfect decision boundaries caused by data imbalances and complement each other to generate domain-balanced decision boundaries. Also, we propose a flow consistency loss to focus on moving objects, expecting class activation maps of multi-frame matches the flow with optical flow maps for input images. Moreover, two long-tailed camera-trap datasets, WCS-LT and DMZ-LT, are introduced to validate our methods. Experimental results show the effectiveness of our framework, and proposed methods outperform previous methods on recessive domain samples.