 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCode-Mixed Probes Show How Pre-Trained Models Generalise On Code-Switched Text
Mar 07, 2024



Code-switching is a prevalent linguistic phenomenon in which multilingual individuals seamlessly alternate between languages. Despite its widespread use online and recent research trends in this area, research in code-switching presents unique challenges, primarily stemming from the scarcity of labelled data and available resources. In this study we investigate how pre-trained Language Models handle code-switched text in three dimensions: a) the ability of PLMs to detect code-switched text, b) variations in the structural information that PLMs utilise to capture code-switched text, and c) the consistency of semantic information representation in code-switched text. To conduct a systematic and controlled evaluation of the language models in question, we create a novel dataset of well-formed naturalistic code-switched text along with parallel translations into the source languages. Our findings reveal that pre-trained language models are effective in generalising to code-switched text, shedding light on the abilities of these models to generalise representations to CS corpora. We release all our code and data including the novel corpus at https://github.com/francesita/code-mixed-probes.
Standardize: Aligning Language Models with Expert-Defined Standards for Content Generation
Feb 19, 2024



Domain experts across engineering, healthcare, and education follow strict standards for producing quality content such as technical manuals, medication instructions, and children's reading materials. However, current works in controllable text generation have yet to explore using these standards as references for control. Towards this end, we introduce Standardize, a retrieval-style in-context learning-based framework to guide large language models to align with expert-defined standards. Focusing on English language standards in the education domain as a use case, we consider the Common European Framework of Reference for Languages (CEFR) and Common Core Standards (CCS) for the task of open-ended content generation. Our findings show that models can gain 40% to 100% increase in precise accuracy for Llama2 and GPT-4, respectively, demonstrating that the use of knowledge artifacts extracted from standards and integrating them in the generation process can effectively guide models to produce better standard-aligned content.
Word Boundary Information Isn't Useful for Encoder Language Models
Jan 15, 2024



All existing transformer-based approaches to NLP using subword tokenisation algorithms encode whitespace (word boundary information) through the use of special space symbols (such as \#\# or \_) forming part of tokens. These symbols have been shown to a) lead to reduced morphological validity of tokenisations, and b) give substantial vocabulary redundancy. As such, removing these symbols has been shown to have a beneficial effect on the processing of morphologically complex words for transformer encoders in the pretrain-finetune paradigm. In this work, we explore whether word boundary information is at all useful to such models. In particular, we train transformer encoders across four different training scales, and investigate several alternative approaches to including word boundary information, evaluating on a range of tasks across different domains and problem set-ups: GLUE (for sentence-level classification), NER (for token-level classification), and two classification datasets involving complex words (Superbizarre and FLOTA). Overall, through an extensive experimental setup that includes the pre-training of 29 models, we find no substantial improvements from our alternative approaches, suggesting that modifying tokenisers to remove word boundary information isn't leading to a loss of useful information.
Flesch or Fumble? Evaluating Readability Standard Alignment of Instruction-Tuned Language Models
Sep 11, 2023Readability metrics and standards such as Flesch Kincaid Grade Level (FKGL) and the Common European Framework of Reference for Languages (CEFR) exist to guide teachers and educators to properly assess the complexity of educational materials before administering them for classroom use. In this study, we select a diverse set of open and closed-source instruction-tuned language models and investigate their performances in writing story completions and simplifying narratives$-$tasks that teachers perform$-$using standard-guided prompts controlling text readability. Our extensive findings provide empirical proof of how globally recognized models like ChatGPT may be considered less effective and may require more refined prompts for these generative tasks compared to other open-sourced models such as BLOOMZ and FlanT5$-$which have shown promising results.
Are Emergent Abilities in Large Language Models just In-Context Learning?
Sep 04, 2023Large language models have exhibited emergent abilities, demonstrating exceptional performance across diverse tasks for which they were not explicitly trained, including those that require complex reasoning abilities. The emergence of such abilities carries profound implications for the future direction of research in NLP, especially as the deployment of such models becomes more prevalent. However, one key challenge is that the evaluation of these abilities is often confounded by competencies that arise in models through alternative prompting techniques, such as in-context learning and instruction following, which also emerge as the models are scaled up. In this study, we provide the first comprehensive examination of these emergent abilities while accounting for various potentially biasing factors that can influence the evaluation of models. We conduct rigorous tests on a set of 18 models, encompassing a parameter range from 60 million to 175 billion parameters, across a comprehensive set of 22 tasks. Through an extensive series of over 1,000 experiments, we provide compelling evidence that emergent abilities can primarily be ascribed to in-context learning. We find no evidence for the emergence of reasoning abilities, thus providing valuable insights into the underlying mechanisms driving the observed abilities and thus alleviating safety concerns regarding their use.
Construction Grammar and Language Models
Sep 04, 2023
Recent progress in deep learning and natural language processing has given rise to powerful models that are primarily trained on a cloze-like task and show some evidence of having access to substantial linguistic information, including some constructional knowledge. This groundbreaking discovery presents an exciting opportunity for a synergistic relationship between computational methods and Construction Grammar research. In this chapter, we explore three distinct approaches to the interplay between computational methods and Construction Grammar: (i) computational methods for text analysis, (ii) computational Construction Grammar, and (iii) deep learning models, with a particular focus on language models. We touch upon the first two approaches as a contextual foundation for the use of computational methods before providing an accessible, yet comprehensive overview of deep learning models, which also addresses reservations construction grammarians may have. Additionally, we delve into experiments that explore the emergence of constructionally relevant information within these models while also examining the aspects of Construction Grammar that may pose challenges for these models. This chapter aims to foster collaboration between researchers in the fields of natural language processing and Construction Grammar. By doing so, we hope to pave the way for new insights and advancements in both these fields.
Effective Cross-Task Transfer Learning for Explainable Natural Language Inference with T5
Oct 31, 2022We compare sequential fine-tuning with a model for multi-task learning in the context where we are interested in boosting performance on two tasks, one of which depends on the other. We test these models on the FigLang2022 shared task which requires participants to predict language inference labels on figurative language along with corresponding textual explanations of the inference predictions. Our results show that while sequential multi-task learning can be tuned to be good at the first of two target tasks, it performs less well on the second and additionally struggles with overfitting. Our findings show that simple sequential fine-tuning of text-to-text models is an extraordinarily powerful method for cross-task knowledge transfer while simultaneously predicting multiple interdependent targets. So much so, that our best model achieved the (tied) highest score on the task.
Abstraction not Memory: BERT and the English Article System
Jun 08, 2022
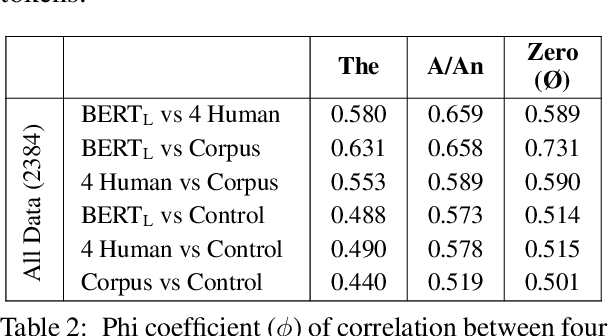
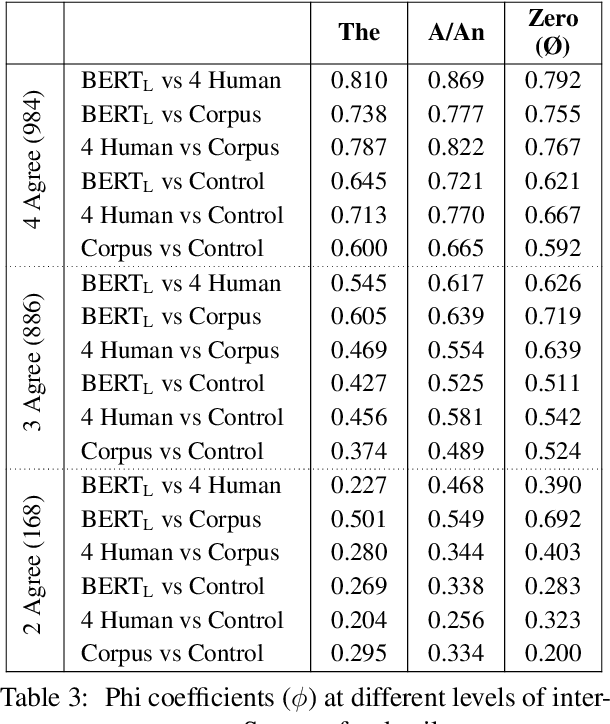
Article prediction is a task that has long defied accurate linguistic description. As such, this task is ideally suited to evaluate models on their ability to emulate native-speaker intuition. To this end, we compare the performance of native English speakers and pre-trained models on the task of article prediction set up as a three way choice (a/an, the, zero). Our experiments with BERT show that BERT outperforms humans on this task across all articles. In particular, BERT is far superior to humans at detecting the zero article, possibly because we insert them using rules that the deep neural model can easily pick up. More interestingly, we find that BERT tends to agree more with annotators than with the corpus when inter-annotator agreement is high but switches to agreeing more with the corpus as inter-annotator agreement drops. We contend that this alignment with annotators, despite being trained on the corpus, suggests that BERT is not memorising article use, but captures a high level generalisation of article use akin to human intuition.
Sample Efficient Approaches for Idiomaticity Detection
May 23, 2022
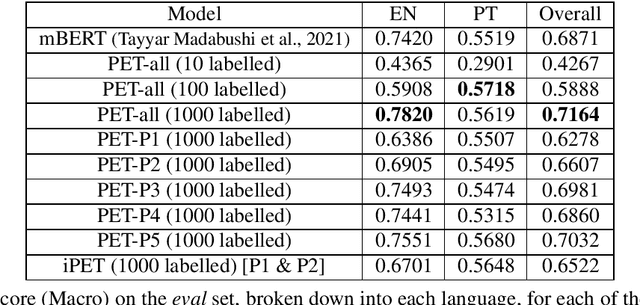
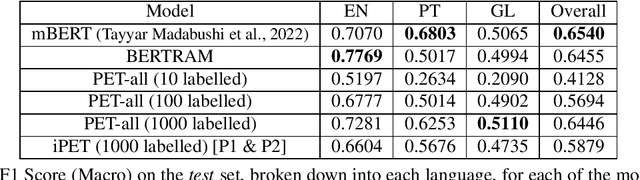

Deep neural models, in particular Transformer-based pre-trained language models, require a significant amount of data to train. This need for data tends to lead to problems when dealing with idiomatic multiword expressions (MWEs), which are inherently less frequent in natural text. As such, this work explores sample efficient methods of idiomaticity detection. In particular we study the impact of Pattern Exploit Training (PET), a few-shot method of classification, and BERTRAM, an efficient method of creating contextual embeddings, on the task of idiomaticity detection. In addition, to further explore generalisability, we focus on the identification of MWEs not present in the training data. Our experiments show that while these methods improve performance on English, they are much less effective on Portuguese and Galician, leading to an overall performance about on par with vanilla mBERT. Regardless, we believe sample efficient methods for both identifying and representing potentially idiomatic MWEs are very encouraging and hold significant potential for future exploration.
SemEval-2022 Task 2: Multilingual Idiomaticity Detection and Sentence Embedding
Apr 21, 2022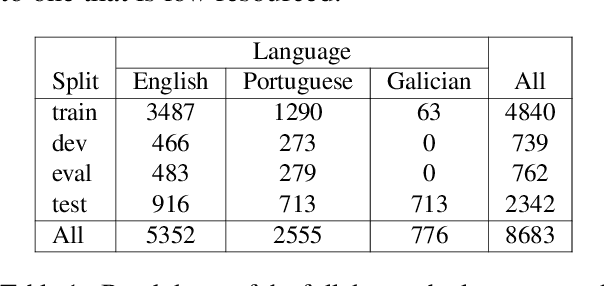
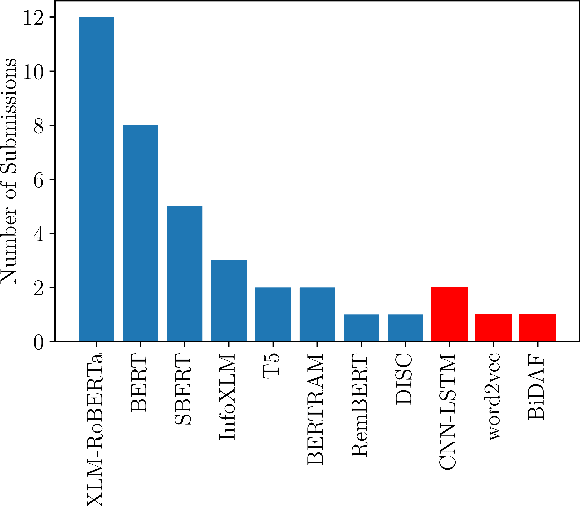

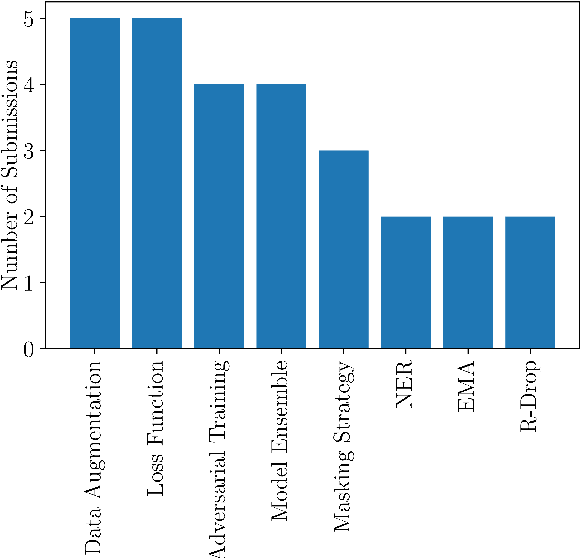
This paper presents the shared task on Multilingual Idiomaticity Detection and Sentence Embedding, which consists of two subtasks: (a) a binary classification one aimed at identifying whether a sentence contains an idiomatic expression, and (b) a task based on semantic text similarity which requires the model to adequately represent potentially idiomatic expressions in context. Each subtask includes different settings regarding the amount of training data. Besides the task description, this paper introduces the datasets in English, Portuguese, and Galician and their annotation procedure, the evaluation metrics, and a summary of the participant systems and their results. The task had close to 100 registered participants organised into twenty five teams making over 650 and 150 submissions in the practice and evaluation phases respectively.