Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCXP949 at WNUT-2020 Task 2: Extracting Informative COVID-19 Tweets -- RoBERTa Ensembles and The Continued Relevance of Handcrafted Features
Paper and Code
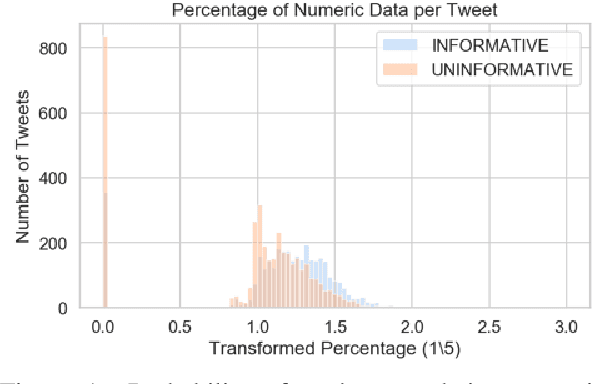

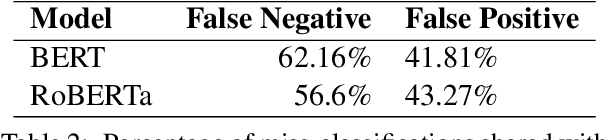
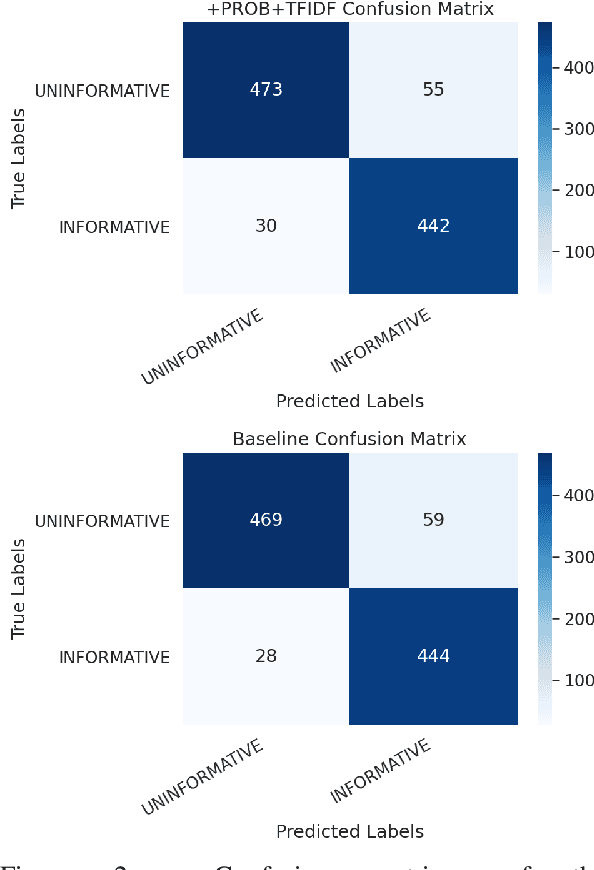
This paper presents our submission to Task 2 of the Workshop on Noisy User-generated Text. We explore improving the performance of a pre-trained transformer-based language model fine-tuned for text classification through an ensemble implementation that makes use of corpus level information and a handcrafted feature. We test the effectiveness of including the aforementioned features in accommodating the challenges of a noisy data set centred on a specific subject outside the remit of the pre-training data. We show that inclusion of additional features can improve classification results and achieve a score within 2 points of the top performing team.
View paper on