 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmotion-Aware Prefix: Towards Explicit Emotion Control in Voice Conversion Models
Mar 10, 2026Recent advances in zero-shot voice conversion have exhibited potential in emotion control, yet the performance is suboptimal or inconsistent due to their limited expressive capacity. We propose Emotion-Aware Prefix for explicit emotion control in a two-stage voice conversion backbone. We significantly improve emotion conversion performance, doubling the baseline Emotion Conversion Accuracy (ECA) from 42.40% to 85.50% while maintaining linguistic integrity and speech quality, without compromising speaker identity. Our ablation study suggests that a joint control of both sequence modulation and acoustic realization is essential to synthesize distinct emotions. Furthermore, comparative analysis verifies the generalizability of proposed method, while it provides insights on the role of acoustic decoupling in maintaining speaker identity.
Speech Recognition on TV Series with Video-guided Post-Correction
Jun 08, 2025
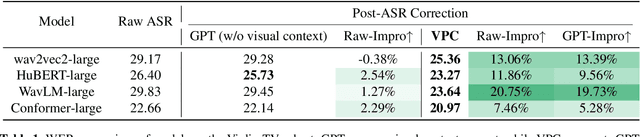

Automatic Speech Recognition (ASR) has achieved remarkable success with deep learning, driving advancements in conversational artificial intelligence, media transcription, and assistive technologies. However, ASR systems still struggle in complex environments such as TV series, where overlapping speech, domain-specific terminology, and long-range contextual dependencies pose significant challenges to transcription accuracy. Existing multimodal approaches fail to correct ASR outputs with the rich temporal and contextual information available in video. To address this limitation, we propose a novel multimodal post-correction framework that refines ASR transcriptions by leveraging contextual cues extracted from video. Our framework consists of two stages: ASR Generation and Video-based Post-Correction, where the first stage produces the initial transcript and the second stage corrects errors using Video-based Contextual Information Extraction and Context-aware ASR Correction. We employ the Video-Large Multimodal Model (VLMM) to extract key contextual information using tailored prompts, which is then integrated with a Large Language Model (LLM) to refine the ASR output. We evaluate our method on a multimodal benchmark for TV series ASR and demonstrate its effectiveness in improving ASR performance by leveraging video-based context to enhance transcription accuracy in complex multimedia environments.
Wasserstein Distance Rivals Kullback-Leibler Divergence for Knowledge Distillation
Dec 11, 2024



Since pioneering work of Hinton et al., knowledge distillation based on Kullback-Leibler Divergence (KL-Div) has been predominant, and recently its variants have achieved compelling performance. However, KL-Div only compares probabilities of the corresponding category between the teacher and student while lacking a mechanism for cross-category comparison. Besides, KL-Div is problematic when applied to intermediate layers, as it cannot handle non-overlapping distributions and is unaware of geometry of the underlying manifold. To address these downsides, we propose a methodology of Wasserstein Distance (WD) based knowledge distillation. Specifically, we propose a logit distillation method called WKD-L based on discrete WD, which performs cross-category comparison of probabilities and thus can explicitly leverage rich interrelations among categories. Moreover, we introduce a feature distillation method called WKD-F, which uses a parametric method for modeling feature distributions and adopts continuous WD for transferring knowledge from intermediate layers. Comprehensive evaluations on image classification and object detection have shown (1) for logit distillation WKD-L outperforms very strong KL-Div variants; (2) for feature distillation WKD-F is superior to the KL-Div counterparts and state-of-the-art competitors. The source code is available at https://peihuali.org/WKD