 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech Recognition on TV Series with Video-guided Post-Correction
Paper and Code
Jun 08, 2025
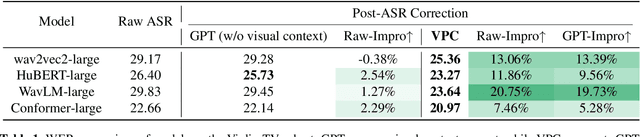

Automatic Speech Recognition (ASR) has achieved remarkable success with deep learning, driving advancements in conversational artificial intelligence, media transcription, and assistive technologies. However, ASR systems still struggle in complex environments such as TV series, where overlapping speech, domain-specific terminology, and long-range contextual dependencies pose significant challenges to transcription accuracy. Existing multimodal approaches fail to correct ASR outputs with the rich temporal and contextual information available in video. To address this limitation, we propose a novel multimodal post-correction framework that refines ASR transcriptions by leveraging contextual cues extracted from video. Our framework consists of two stages: ASR Generation and Video-based Post-Correction, where the first stage produces the initial transcript and the second stage corrects errors using Video-based Contextual Information Extraction and Context-aware ASR Correction. We employ the Video-Large Multimodal Model (VLMM) to extract key contextual information using tailored prompts, which is then integrated with a Large Language Model (LLM) to refine the ASR output. We evaluate our method on a multimodal benchmark for TV series ASR and demonstrate its effectiveness in improving ASR performance by leveraging video-based context to enhance transcription accuracy in complex multimedia environments.