 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAVEN: A Mesh-Aware Volumetric Encoding Network for Simulating 3D Flexible Deformation
Apr 06, 2026Deep learning-based approaches, particularly graph neural networks (GNNs), have gained prominence in simulating flexible deformations and contacts of solids, due to their ability to handle unstructured physical fields and nonlinear regression on graph structures. However, existing GNNs commonly represent meshes with graphs built solely from vertices and edges. These approaches tend to overlook higher-dimensional spatial features, e.g., 2D facets and 3D cells, from the original geometry. As a result, it is challenging to accurately capture boundary representations and volumetric characteristics, though this information is critically important for modeling contact interactions and internal physical quantity propagation, particularly under sparse mesh discretization. In this paper, we introduce MAVEN, a mesh-aware volumetric encoding network for simulating 3D flexible deformation, which explicitly models geometric mesh elements of higher dimension to achieve a more accurate and natural physical simulation. MAVEN establishes learnable mappings among 3D cells, 2D facets, and vertices, enabling flexible mutual transformations. Explicit geometric features are incorporated into the model to alleviate the burden of implicitly learning geometric patterns. Experimental results show that MAVEN consistently achieves state-of-the-art performance across established datasets and a novel metal stretch-bending task featuring large deformations and prolonged contacts.
ATime-Consistent Benchmark for Repository-Level Software Engineering Evaluation
Mar 27, 2026Evaluation of repository-aware software engineering systems is often confounded by synthetic task design, prompt leakage, and temporal contamination between repository knowledge and future code changes. We present a time-consistent benchmark methodology that snapshots a repository at time T0, constructs repository-derived code knowledge using only artifacts available before T0, and evaluates on engineering tasks derived from pull requests merged in the future interval (T0, T1]. Each historical pull request is transformed into a natural-language task through an LLM-assisted prompt-generation pipeline, and the benchmark is formalized as a matched A/B comparison in which the same software engineering agent is evaluated with and without repository-derived code knowledge while all other variables are held constant. We also report a baseline characterization study on two open-source repositories, DragonFly and React, using three Claude-family models and four prompt granularities. Across both repositories, file-level F1 increases monotonically from minimal to guided prompts, reaching 0.8081 on DragonFly and 0.8078 on React for the strongest tested model. These results show that prompt construction is a first-order benchmark variable. More broadly, the benchmark highlights that temporal consistency and prompt control are core validity requirements for repository-aware software engineering evaluation.
FilDeep: Learning Large Deformations of Elastic-Plastic Solids with Multi-Fidelity Data
Jan 15, 2026The scientific computation of large deformations in elastic-plastic solids is crucial in various manufacturing applications. Traditional numerical methods exhibit several inherent limitations, prompting Deep Learning (DL) as a promising alternative. The effectiveness of current DL techniques typically depends on the availability of high-quantity and high-accuracy datasets, which are yet difficult to obtain in large deformation problems. During the dataset construction process, a dilemma stands between data quantity and data accuracy, leading to suboptimal performance in the DL models. To address this challenge, we focus on a representative application of large deformations, the stretch bending problem, and propose FilDeep, a Fidelity-based Deep Learning framework for large Deformation of elastic-plastic solids. Our FilDeep aims to resolve the quantity-accuracy dilemma by simultaneously training with both low-fidelity and high-fidelity data, where the former provides greater quantity but lower accuracy, while the latter offers higher accuracy but in less quantity. In FilDeep, we provide meticulous designs for the practical large deformation problem. Particularly, we propose attention-enabled cross-fidelity modules to effectively capture long-range physical interactions across MF data. To the best of our knowledge, our FilDeep presents the first DL framework for large deformation problems using MF data. Extensive experiments demonstrate that our FilDeep consistently achieves state-of-the-art performance and can be efficiently deployed in manufacturing.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
LaDEEP: A Deep Learning-based Surrogate Model for Large Deformation of Elastic-Plastic Solids
Jun 06, 2025Scientific computing for large deformation of elastic-plastic solids is critical for numerous real-world applications. Classical numerical solvers rely primarily on local discrete linear approximation and are constrained by an inherent trade-off between accuracy and efficiency. Recently, deep learning models have achieved impressive progress in solving the continuum mechanism. While previous models have explored various architectures and constructed coefficient-solution mappings, they are designed for general instances without considering specific problem properties and hard to accurately handle with complex elastic-plastic solids involving contact, loading and unloading. In this work, we take stretch bending, a popular metal fabrication technique, as our case study and introduce LaDEEP, a deep learning-based surrogate model for \textbf{La}rge \textbf{De}formation of \textbf{E}lastic-\textbf{P}lastic Solids. We encode the partitioned regions of the involved slender solids into a token sequence to maintain their essential order property. To characterize the physical process of the solid deformation, a two-stage Transformer-based module is designed to predict the deformation with the sequence of tokens as input. Empirically, LaDEEP achieves five magnitudes faster speed than finite element methods with a comparable accuracy, and gains 20.47\% relative improvement on average compared to other deep learning baselines. We have also deployed our model into a real-world industrial production system, and it has shown remarkable performance in both accuracy and efficiency.
Unisoma: A Unified Transformer-based Solver for Multi-Solid Systems
Jun 06, 2025Multi-solid systems are foundational to a wide range of real-world applications, yet modeling their complex interactions remains challenging. Existing deep learning methods predominantly rely on implicit modeling, where the factors influencing solid deformation are not explicitly represented but are instead indirectly learned. However, as the number of solids increases, these methods struggle to accurately capture intricate physical interactions. In this paper, we introduce a novel explicit modeling paradigm that incorporates factors influencing solid deformation through structured modules. Specifically, we present Unisoma, a unified and flexible Transformer-based model capable of handling variable numbers of solids. Unisoma directly captures physical interactions using contact modules and adaptive interaction allocation mechanism, and learns the deformation through a triplet relationship. Compared to implicit modeling techniques, explicit modeling is more well-suited for multi-solid systems with diverse coupling patterns, as it enables detailed treatment of each solid while preventing information blending and confusion. Experimentally, Unisoma achieves consistent state-of-the-art performance across seven well-established datasets and two complex multi-solid tasks. Code is avaiable at \href{this link}{https://github.com/therontau0054/Unisoma}.
Improving the Level of Autism Discrimination through GraphRNN Link Prediction
Feb 19, 2022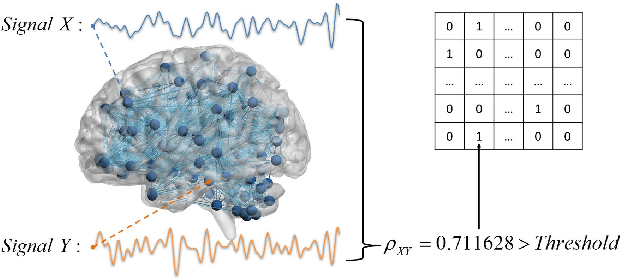
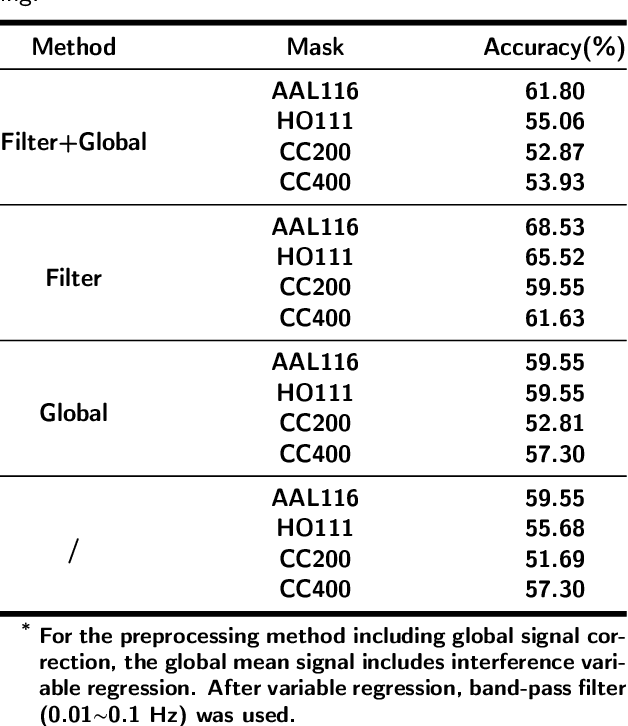
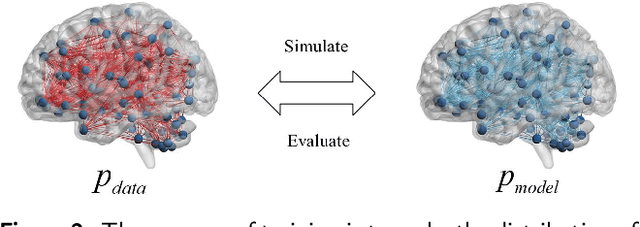
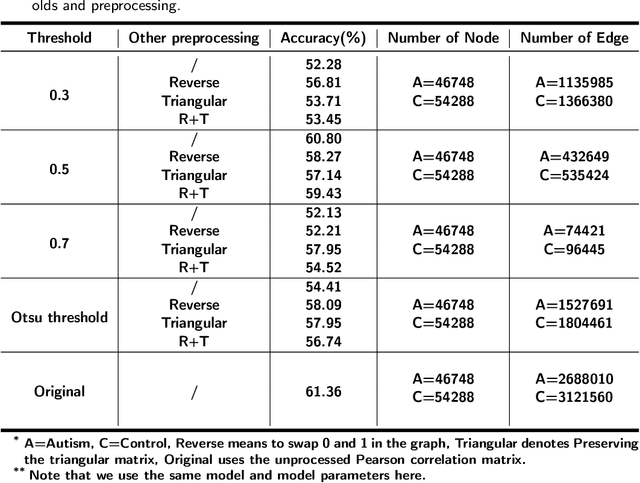
Dataset is the key of deep learning in Autism disease research. However, due to the few quantity and heterogeneity of samples in current dataset, for example ABIDE (Autism Brain Imaging Data Exchange), the recognition research is not effective enough. Previous studies mostly focused on optimizing feature selection methods and data reinforcement to improve accuracy. This paper is based on the latter technique, which learns the edge distribution of real brain network through GraphRNN, and generates the synthetic data which has incentive effect on the discriminant model. The experimental results show that the combination of original and synthetic data greatly improves the discrimination of the neural network. For instance, the most significant effect is the 50-layer ResNet, and the best generation model is GraphRNN, which improves the accuracy by 32.51% compared with the model reference experiment without generation data reinforcement. Because the generated data comes from the learned edge connection distribution of Autism patients and typical controls functional connectivity, but it has better effect than the original data, which has constructive significance for further understanding of disease mechanism and development.
A Heterogeneous Graphical Model to Understand User-Level Sentiments in Social Media
Dec 17, 2019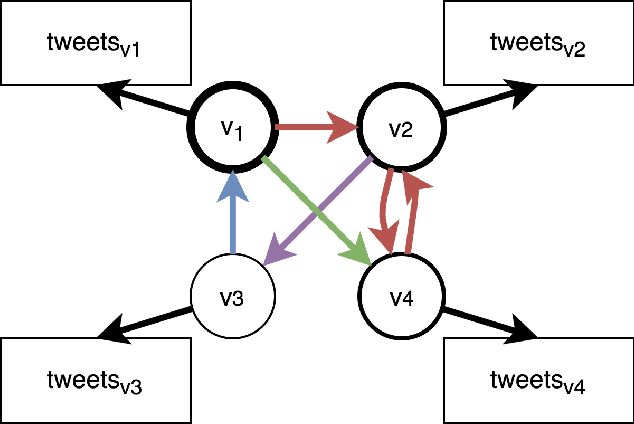
Social Media has seen a tremendous growth in the last decade and is continuing to grow at a rapid pace. With such adoption, it is increasingly becoming a rich source of data for opinion mining and sentiment analysis. The detection and analysis of sentiment in social media is thus a valuable topic and attracts a lot of research efforts. Most of the earlier efforts focus on supervised learning approaches to solve this problem, which require expensive human annotations and therefore limits their practical use. In our work, we propose a semi-supervised approach to predict user-level sentiments for specific topics. We define and utilize a heterogeneous graph built from the social networks of the users with the knowledge that connected users in social networks typically share similar sentiments. Compared with the previous works, we have several novelties: (1) we incorporate the influences/authoritativeness of the users into the model, 2) we include comment-based and like-based user-user links to the graph, 3) we superimpose multiple heterogeneous graphs into one thereby allowing multiple types of links to exist between two users.
Learning to Associate Words and Images Using a Large-scale Graph
May 22, 2017
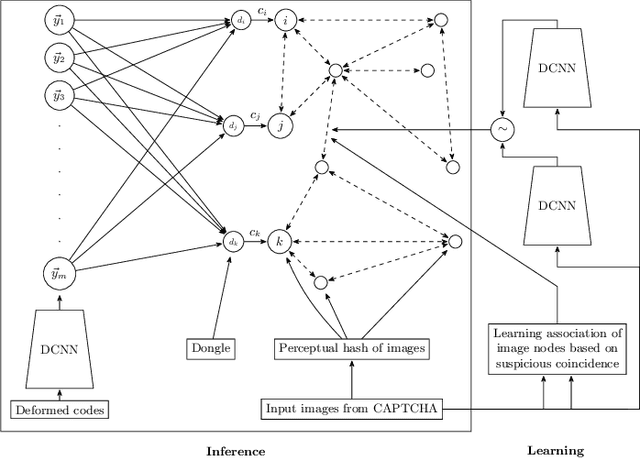

We develop an approach for unsupervised learning of associations between co-occurring perceptual events using a large graph. We applied this approach to successfully solve the image captcha of China's railroad system. The approach is based on the principle of suspicious coincidence. In this particular problem, a user is presented with a deformed picture of a Chinese phrase and eight low-resolution images. They must quickly select the relevant images in order to purchase their train tickets. This problem presents several challenges: (1) the teaching labels for both the Chinese phrases and the images were not available for supervised learning, (2) no pre-trained deep convolutional neural networks are available for recognizing these Chinese phrases or the presented images, and (3) each captcha must be solved within a few seconds. We collected 2.6 million captchas, with 2.6 million deformed Chinese phrases and over 21 million images. From these data, we constructed an association graph, composed of over 6 million vertices, and linked these vertices based on co-occurrence information and feature similarity between pairs of images. We then trained a deep convolutional neural network to learn a projection of the Chinese phrases onto a 230-dimensional latent space. Using label propagation, we computed the likelihood of each of the eight images conditioned on the latent space projection of the deformed phrase for each captcha. The resulting system solved captchas with 77% accuracy in 2 seconds on average. Our work, in answering this practical challenge, illustrates the power of this class of unsupervised association learning techniques, which may be related to the brain's general strategy for associating language stimuli with visual objects on the principle of suspicious coincidence.