 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMW-GAN: Multi-Warping GAN for Caricature Generation with Multi-Style Geometric Exaggeration
Jan 07, 2020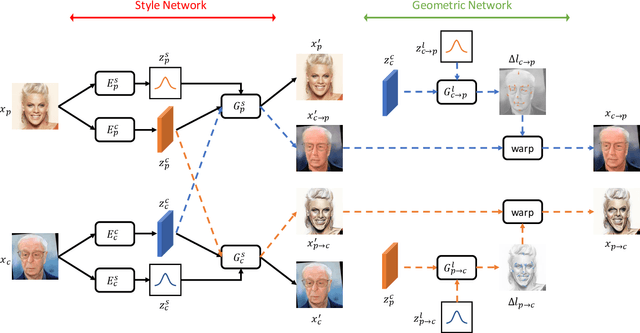
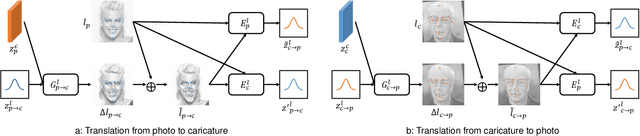
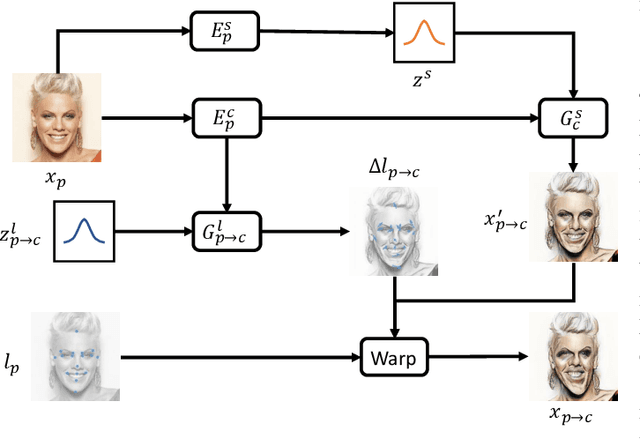

Given an input face photo, the goal of caricature generation is to produce stylized, exaggerated caricatures that share the same identity as the photo. It requires simultaneous style transfer and shape exaggeration with rich diversity, and meanwhile preserving the identity of the input. To address this challenging problem, we propose a novel framework called Multi-Warping GAN (MW-GAN), including a style network and a geometric network that are designed to conduct style transfer and geometric exaggeration respectively. We bridge the gap between the style and landmarks of an image with corresponding latent code spaces by a dual way design, so as to generate caricatures with arbitrary styles and geometric exaggeration, which can be specified either through random sampling of latent code or from a given caricature sample. Besides, we apply identity preserving loss to both image space and landmark space, leading to a great improvement in quality of generated caricatures. Experiments show that caricatures generated by MW-GAN have better quality than existing methods.
Cross-Domain Adversarial Auto-Encoder
Apr 17, 2018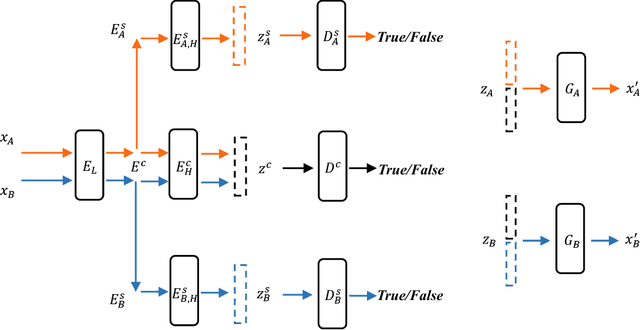


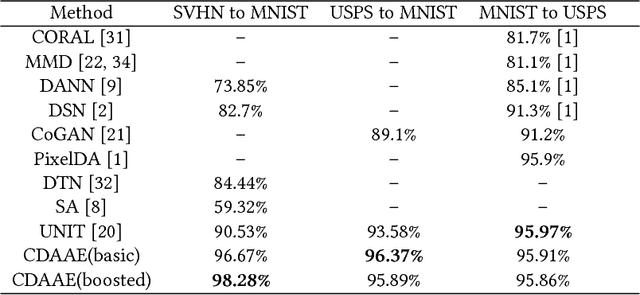
In this paper, we propose the Cross-Domain Adversarial Auto-Encoder (CDAAE) to address the problem of cross-domain image inference, generation and transformation. We make the assumption that images from different domains share the same latent code space for content, while having separate latent code space for style. The proposed framework can map cross-domain data to a latent code vector consisting of a content part and a style part. The latent code vector is matched with a prior distribution so that we can generate meaningful samples from any part of the prior space. Consequently, given a sample of one domain, our framework can generate various samples of the other domain with the same content of the input. This makes the proposed framework different from the current work of cross-domain transformation. Besides, the proposed framework can be trained with both labeled and unlabeled data, which makes it also suitable for domain adaptation. Experimental results on data sets SVHN, MNIST and CASIA show the proposed framework achieved visually appealing performance for image generation task. Besides, we also demonstrate the proposed method achieved superior results for domain adaptation. Code of our experiments is available in https://github.com/luckycallor/CDAAE.