 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLEAR: Null-Space Projection for Cross-Modal De-Redundancy in Multimodal Recommendation
Mar 02, 2026Multimodal recommendation has emerged as an effective paradigm for enhancing collaborative filtering by incorporating heterogeneous content modalities. Existing multimodal recommenders predominantly focus on reinforcing cross-modal consistency to facilitate multimodal fusion. However, we observe that multimodal representations often exhibit substantial cross-modal redundancy, where dominant shared components overlap across modalities. Such redundancy can limit the effective utilization of complementary information, explaining why incorporating additional modalities does not always yield performance improvements. In this work, we propose CLEAR, a lightweight and plug-and-play cross-modal de-redundancy approach for multimodal recommendation. Rather than enforcing stronger cross-modal alignment, CLEAR explicitly characterizes the redundant shared subspace across modalities by modeling cross-modal covariance between visual and textual representations. By identifying dominant shared directions via singular value decomposition and projecting multimodal features onto the complementary null space, CLEAR reshapes the multimodal representation space by suppressing redundant cross-modal components while preserving modality-specific information. This subspace-level projection implicitly regulates representation learning dynamics, preventing the model from repeatedly amplifying redundant shared semantics during training. Notably, CLEAR can be seamlessly integrated into existing multimodal recommenders without modifying their architectures or training objectives. Extensive experiments on three public benchmark datasets demonstrate that explicitly reducing cross-modal redundancy consistently improves recommendation performance across a wide range of multimodal recommendation models.
SF-Recon: Simplification-Free Lightweight Building Reconstruction via 3D Gaussian Splatting
Nov 17, 2025Lightweight building surface models are crucial for digital city, navigation, and fast geospatial analytics, yet conventional multi-view geometry pipelines remain cumbersome and quality-sensitive due to their reliance on dense reconstruction, meshing, and subsequent simplification. This work presents SF-Recon, a method that directly reconstructs lightweight building surfaces from multi-view images without post-hoc mesh simplification. We first train an initial 3D Gaussian Splatting (3DGS) field to obtain a view-consistent representation. Building structure is then distilled by a normal-gradient-guided Gaussian optimization that selects primitives aligned with roof and wall boundaries, followed by multi-view edge-consistency pruning to enhance structural sharpness and suppress non-structural artifacts without external supervision. Finally, a multi-view depth-constrained Delaunay triangulation converts the structured Gaussian field into a lightweight, structurally faithful building mesh. Based on a proposed SF dataset, the experimental results demonstrate that our SF-Recon can directly reconstruct lightweight building models from multi-view imagery, achieving substantially fewer faces and vertices while maintaining computational efficiency. Website:https://lzh282140127-cell.github.io/SF-Recon-project/
The Controllability of Planning, Responsibility, and Security in Automatic Driving Technology
Feb 01, 2021
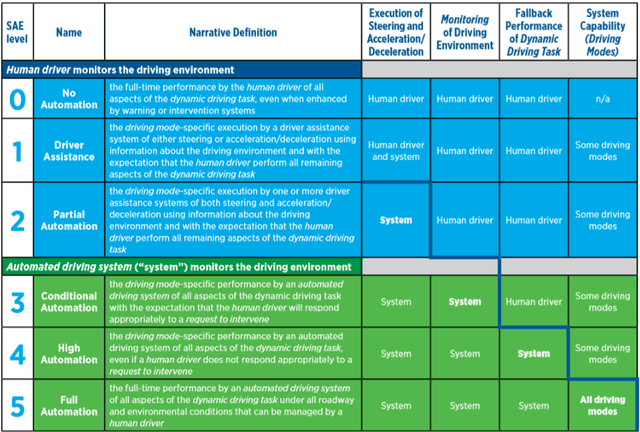
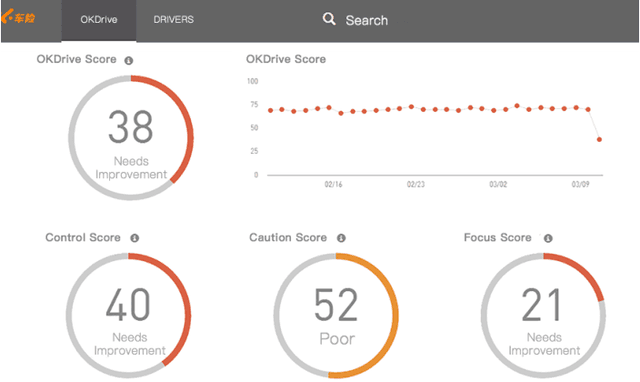

People hope automated driving technology is always in a stable and controllable state; specifically, it can be divided into controllable planning, controllable responsibility, and controllable information. When this controllability is undermined, it brings about the problems, e.g., trolley dilemma, responsibility attribution, information leakage, and security. This article discusses these three types of issues separately and clarifies the misunderstandings.