 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Deep Learning Approach to Private Data Sharing of Medical Images Using Conditional GANs
Jun 24, 2021Sharing data from clinical studies can facilitate innovative data-driven research and ultimately lead to better public health. However, sharing biomedical data can put sensitive personal information at risk. This is usually solved by anonymization, which is a slow and expensive process. An alternative to anonymization is sharing a synthetic dataset that bears a behaviour similar to the real data but preserves privacy. As part of the collaboration between Novartis and the Oxford Big Data Institute, we generate a synthetic dataset based on COSENTYX (secukinumab) Ankylosing Spondylitis (AS) clinical study. We apply an Auxiliary Classifier GAN (ac-GAN) to generate synthetic magnetic resonance images (MRIs) of vertebral units (VUs). The images are conditioned on the VU location (cervical, thoracic and lumbar). In this paper, we present a method for generating a synthetic dataset and conduct an in-depth analysis on its properties of along three key metrics: image fidelity, sample diversity and dataset privacy.
Stein Neural Sampler
Oct 08, 2018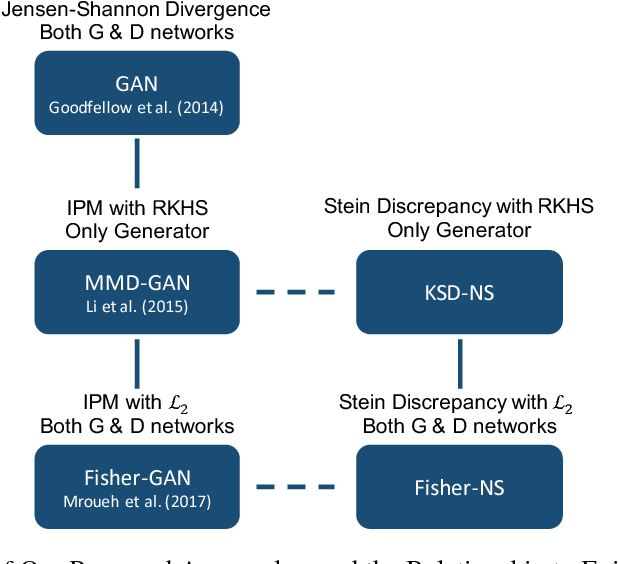
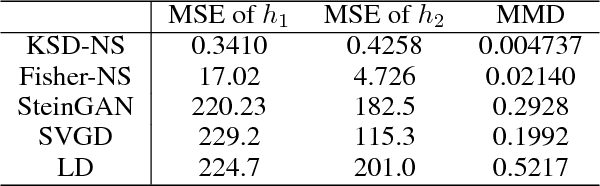
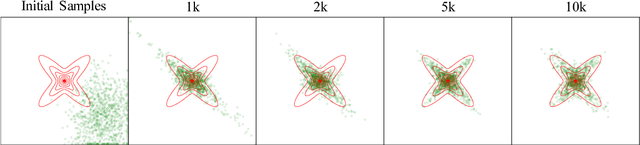
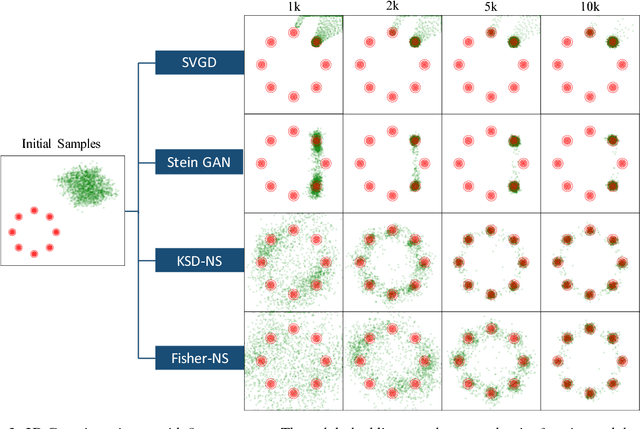
We propose two novel samplers to produce high-quality samples from a given (un-normalized) probability density. The sampling is achieved by transforming a reference distribution to the target distribution with neural networks, which are trained separately by minimizing two kinds of Stein Discrepancies, and hence our method is named as Stein neural sampler. Theoretical and empirical results suggest that, compared with traditional sampling schemes, our samplers share the following three advantages: 1. Being asymptotically correct; 2. Experiencing less convergence issue in practice; 3. Generating samples instantaneously.