 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCloudCons: A Comprehensive End-to-End Benchmark for Cloud Resource Consolidation
Jun 11, 2026Driven by conservative over-provisioning to guarantee service reliability, resource utilization in cloud data centers remains at low levels. To mitigate this, the forecast-then-optimize paradigm has emerged to optimize consolidation by anticipating future demands. While emerging time series foundation models promise to enhance this paradigm through zero-shot generalization, existing benchmarks focus solely on prediction error metrics. The actual decision utility of these advanced models remains unverified, rendering their practical value for downstream tasks uncertain. To bridge this gap, we propose CloudCons, a comprehensive end-to-end benchmark designed to evaluate forecasting models within the specific context of cloud resource consolidation. We build high-quality datasets that cover diverse workloads from Huawei Cloud, Microsoft Azure, and Google Borg, capturing distinct service characteristics ranging from synchronized diurnal rhythms to stochastic, pulse-like bursts and high-frequency noise. We conduct an extensive evaluation of statistical, deep learning, and foundation models. Our experiments reveal a pivotal finding: while foundation models demonstrate superior zero-shot forecasting accuracy, this advantage does not inherently translate into better decision utility. Of practical significance, we systematically analyze how the selection of predictive quantiles acts as a critical lever. We provide actionable guidelines for calibrating these selections to balance the trade-off between resource efficiency and service reliability, offering vital insights for real-world deployment decisions.
TSFMAudit: Data Contamination Auditing in Forecasting Time Series Foundation Models
May 24, 2026Time series foundation models (TSFMs) are increasingly pretrained on large corpora, raising concerns that evaluation datasets may have been exposed during pretraining and thus yield overly optimistic performance estimates. Auditing such contamination is challenging in time series because signals are continuous and heterogeneous, and often lack corpus documentation. To the best of our knowledge, this is the first work to study pretraining contamination auditing for TSFMs. We formalize the problem of pretraining contamination auditing for TSFMs and propose TSFMAudit, a method based on probe adaptation dynamics. Our key intuition is that contamination manifests as unusually efficient adaptation: after a fine tuning probe, contaminated datasets tend to exhibit faster loss reduction with smaller backbone movement. We evaluate TSFMAudit on 6 TSFMs and 187 datasets using documented training source evidence as supervision, and compare against 10 competitive baselines adapted from the LLM literature.
The Power of Architecture: Deep Dive into Transformer Architectures for Long-Term Time Series Forecasting
Jul 17, 2025



Transformer-based models have recently become dominant in Long-term Time Series Forecasting (LTSF), yet the variations in their architecture, such as encoder-only, encoder-decoder, and decoder-only designs, raise a crucial question: What Transformer architecture works best for LTSF tasks? However, existing models are often tightly coupled with various time-series-specific designs, making it difficult to isolate the impact of the architecture itself. To address this, we propose a novel taxonomy that disentangles these designs, enabling clearer and more unified comparisons of Transformer architectures. Our taxonomy considers key aspects such as attention mechanisms, forecasting aggregations, forecasting paradigms, and normalization layers. Through extensive experiments, we uncover several key insights: bi-directional attention with joint-attention is most effective; more complete forecasting aggregation improves performance; and the direct-mapping paradigm outperforms autoregressive approaches. Furthermore, our combined model, utilizing optimal architectural choices, consistently outperforms several existing models, reinforcing the validity of our conclusions. We hope these findings offer valuable guidance for future research on Transformer architectural designs in LTSF. Our code is available at https://github.com/HALF111/TSF_architecture.
PEMT: Multi-Task Correlation Guided Mixture-of-Experts Enables Parameter-Efficient Transfer Learning
Feb 23, 2024



Parameter-efficient fine-tuning (PEFT) has emerged as an effective method for adapting pre-trained language models to various tasks efficiently. Recently, there has been a growing interest in transferring knowledge from one or multiple tasks to the downstream target task to achieve performance improvements. However, current approaches typically either train adapters on individual tasks or distill shared knowledge from source tasks, failing to fully exploit task-specific knowledge and the correlation between source and target tasks. To overcome these limitations, we propose PEMT, a novel parameter-efficient fine-tuning framework based on multi-task transfer learning. PEMT extends the mixture-of-experts (MoE) framework to capture the transferable knowledge as a weighted combination of adapters trained on source tasks. These weights are determined by a gated unit, measuring the correlation between the target and each source task using task description prompt vectors. To fully exploit the task-specific knowledge, we also propose the Task Sparsity Loss to improve the sparsity of the gated unit. We conduct experiments on a broad range of tasks over 17 datasets. The experimental results demonstrate our PEMT yields stable improvements over full fine-tuning, and state-of-the-art PEFT and knowledge transferring methods on various tasks. The results highlight the effectiveness of our method which is capable of sufficiently exploiting the knowledge and correlation features across multiple tasks.
Calibration of Time-Series Forecasting Transformers: Detecting and Adapting Context-Driven Distribution Shift
Oct 23, 2023



Recent years have witnessed the success of introducing Transformers to time series forecasting. From a data generation perspective, we illustrate that existing Transformers are susceptible to distribution shifts driven by temporal contexts, whether observed or unobserved. Such context-driven distribution shift (CDS) introduces biases in predictions within specific contexts and poses challenges for conventional training paradigm. In this paper, we introduce a universal calibration methodology for the detection and adaptation of CDS with a trained Transformer model. To this end, we propose a novel CDS detector, termed the "residual-based CDS detector" or "Reconditionor", which quantifies the model's vulnerability to CDS by evaluating the mutual information between prediction residuals and their corresponding contexts. A high Reconditionor score indicates a severe susceptibility, thereby necessitating model adaptation. In this circumstance, we put forth a straightforward yet potent adapter framework for model calibration, termed the "sample-level contextualized adapter" or "SOLID". This framework involves the curation of a contextually similar dataset to the provided test sample and the subsequent fine-tuning of the model's prediction layer with a limited number of steps. Our theoretical analysis demonstrates that this adaptation strategy is able to achieve an optimal equilibrium between bias and variance. Notably, our proposed Reconditionor and SOLID are model-agnostic and readily adaptable to a wide range of Transformers. Extensive experiments show that SOLID consistently enhances the performance of current SOTA Transformers on real-world datasets, especially on cases with substantial CDS detected by the proposed Reconditionor, thus validate the effectiveness of the calibration approach.
MCEN: Bridging Cross-Modal Gap between Cooking Recipes and Dish Images with Latent Variable Model
Apr 02, 2020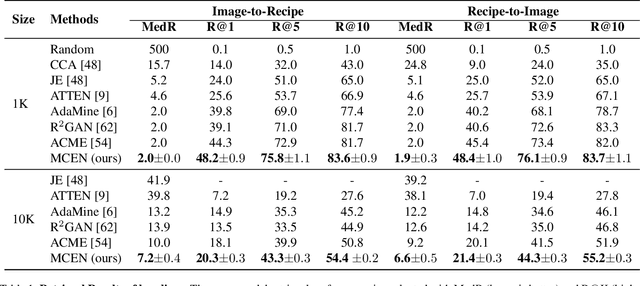
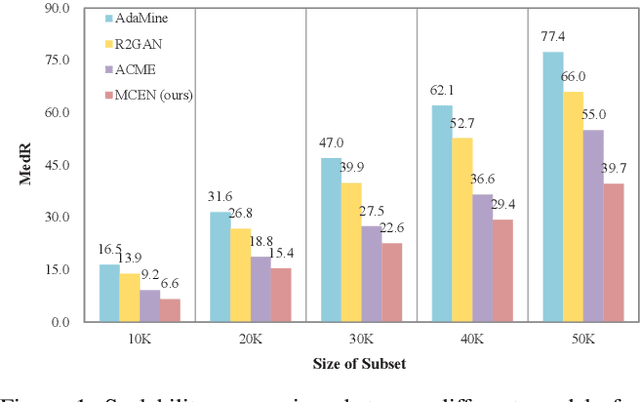
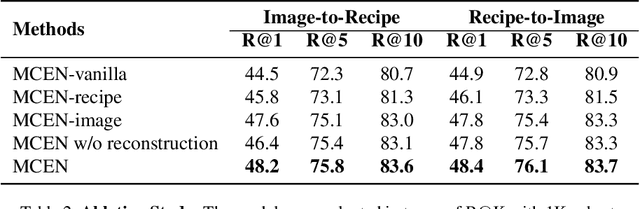
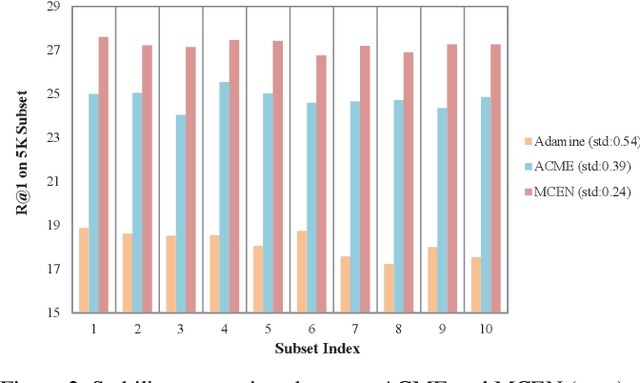
Nowadays, driven by the increasing concern on diet and health, food computing has attracted enormous attention from both industry and research community. One of the most popular research topics in this domain is Food Retrieval, due to its profound influence on health-oriented applications. In this paper, we focus on the task of cross-modal retrieval between food images and cooking recipes. We present Modality-Consistent Embedding Network (MCEN) that learns modality-invariant representations by projecting images and texts to the same embedding space. To capture the latent alignments between modalities, we incorporate stochastic latent variables to explicitly exploit the interactions between textual and visual features. Importantly, our method learns the cross-modal alignments during training but computes embeddings of different modalities independently at inference time for the sake of efficiency. Extensive experimental results clearly demonstrate that the proposed MCEN outperforms all existing approaches on the benchmark Recipe1M dataset and requires less computational cost.
A Machine Learning Framework for Data Ingestion in Document Images
Feb 11, 2020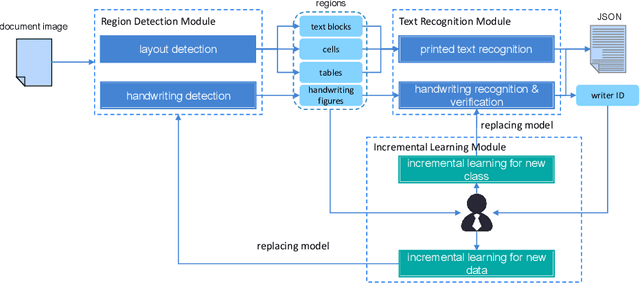

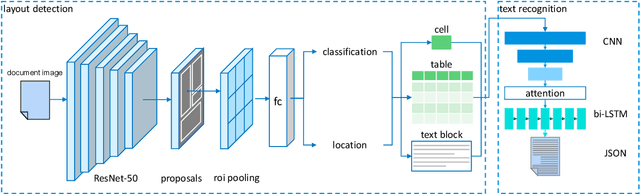

Paper documents are widely used as an irreplaceable channel of information in many fields, especially in financial industry, fostering a great amount of demand for systems which can convert document images into structured data representations. In this paper, we present a machine learning framework for data ingestion in document images, which processes the images uploaded by users and return fine-grained data in JSON format. Details of model architectures, design strategies, distinctions with existing solutions and lessons learned during development are elaborated. We conduct abundant experiments on both synthetic and real-world data in State Street. The experimental results indicate the effectiveness and efficiency of our methods.
Reference Network for Neural Machine Translation
Aug 23, 2019
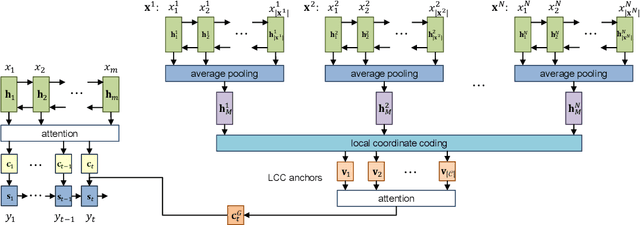
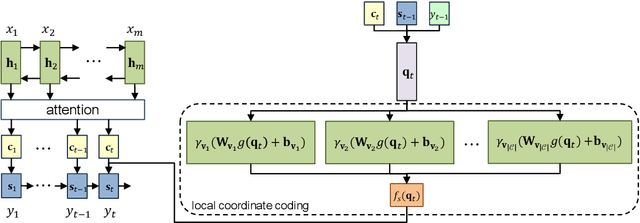
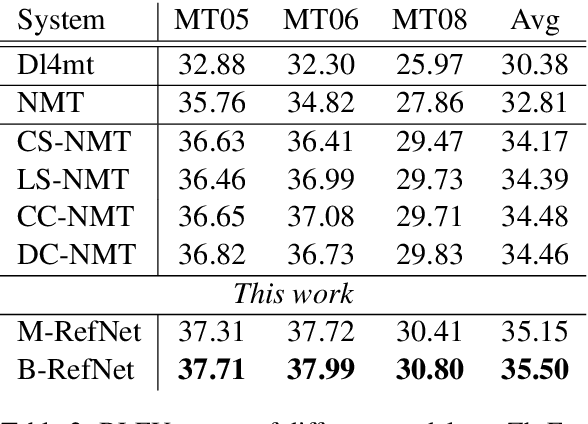
Neural Machine Translation (NMT) has achieved notable success in recent years. Such a framework usually generates translations in isolation. In contrast, human translators often refer to reference data, either rephrasing the intricate sentence fragments with common terms in source language, or just accessing to the golden translation directly. In this paper, we propose a Reference Network to incorporate referring process into translation decoding of NMT. To construct a \emph{reference book}, an intuitive way is to store the detailed translation history with extra memory, which is computationally expensive. Instead, we employ Local Coordinates Coding (LCC) to obtain global context vectors containing monolingual and bilingual contextual information for NMT decoding. Experimental results on Chinese-English and English-German tasks demonstrate that our proposed model is effective in improving the translation quality with lightweight computation cost.