 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Sound Separation Using Mixtures of Mixtures
Jun 23, 2020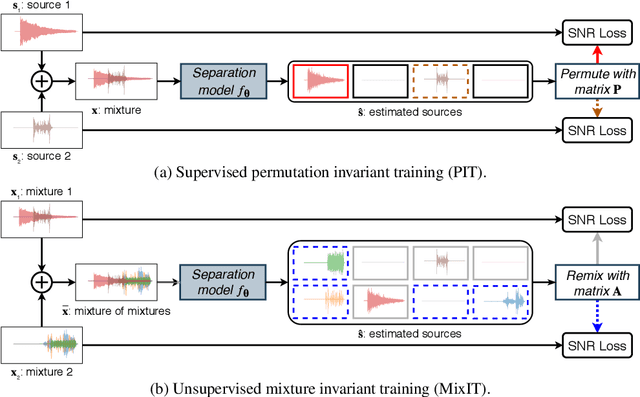
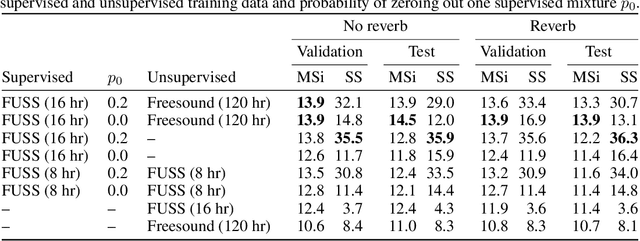
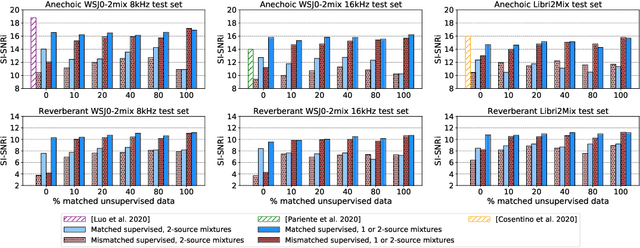
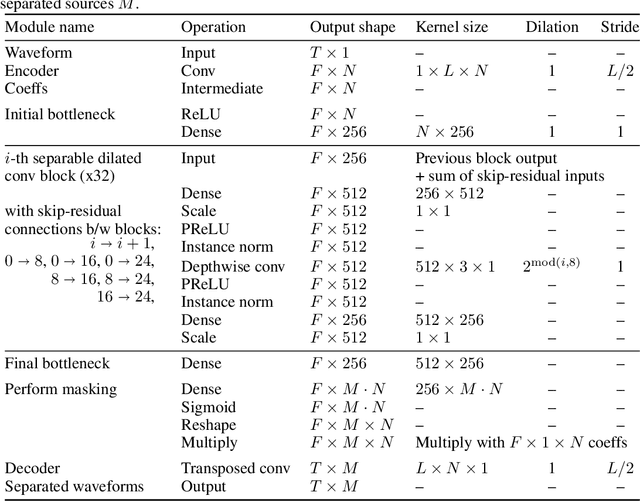
In recent years, rapid progress has been made on the problem of single-channel sound separation using supervised training of deep neural networks. In such supervised approaches, the model is trained to predict the component sources from synthetic mixtures created by adding up isolated ground-truth sources. The reliance on this synthetic training data is problematic because good performance depends upon the degree of match between the training data and real-world audio, especially in terms of the acoustic conditions and distribution of sources. The acoustic properties can be challenging to accurately simulate, and the distribution of sound types may be hard to replicate. In this paper, we propose a completely unsupervised method, mixture invariant training (MixIT), that requires only single-channel acoustic mixtures. In MixIT, training examples are constructed by mixing together existing mixtures, and the model separates them into a variable number of latent sources, such that the separated sources can be remixed to approximate the original mixtures. We show that MixIT can achieve competitive performance compared to supervised methods on speech separation. Using MixIT in a semi-supervised learning setting enables unsupervised domain adaptation and learning from large amounts of real-world data without ground-truth source waveforms. In particular, we significantly improve reverberant speech separation performance by incorporating reverberant mixtures, train a speech enhancement system from noisy mixtures, and improve universal sound separation by incorporating a large amount of in-the-wild data.
Universal Sound Separation
May 08, 2019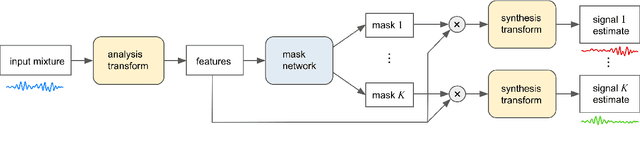
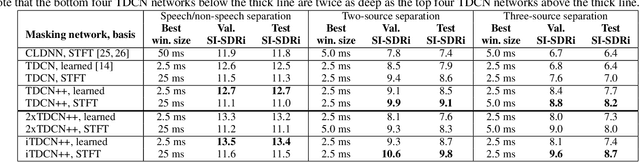
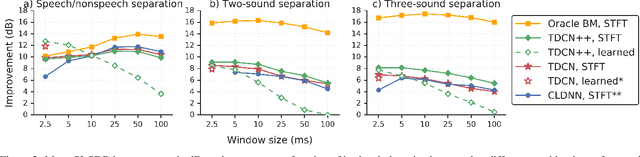
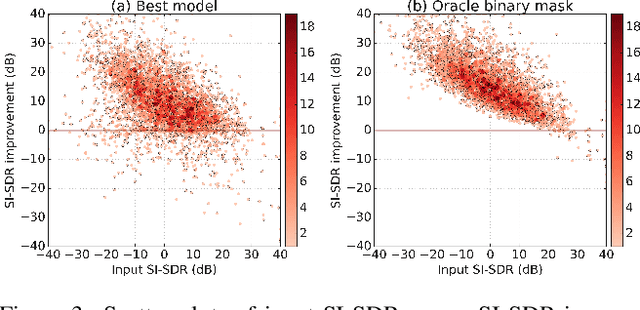
Recent deep learning approaches have achieved impressive performance on speech enhancement and separation tasks. However, these approaches have not been investigated for separating mixtures of arbitrary sounds of different types, a task we refer to as universal sound separation, and it is unknown whether performance on speech tasks carries over to non-speech tasks. To study this question, we develop a universal dataset of mixtures containing arbitrary sounds, and use it to investigate the space of mask-based separation architectures, varying both the overall network architecture and the framewise analysis-synthesis basis for signal transformations. These network architectures include convolutional long short-term memory networks and time-dilated convolution stacks inspired by the recent success of time-domain enhancement networks like ConvTasNet. For the latter architecture, we also propose novel modifications that further improve separation performance. In terms of the framewise analysis-synthesis basis, we explore using either a short-time Fourier transform (STFT) or a learnable basis, as used in ConvTasNet, and for both of these bases, we examine the effect of window size. In particular, for STFTs, we find that longer windows (25-50 ms) work best for speech/non-speech separation, while shorter windows (2.5 ms) work best for arbitrary sounds. For learnable bases, shorter windows (2.5 ms) work best on all tasks. Surprisingly, for universal sound separation, STFTs outperform learnable bases. Our best methods produce an improvement in scale-invariant signal-to-distortion ratio of over 13 dB for speech/non-speech separation and close to 10 dB for universal sound separation.
Low-Latency Speaker-Independent Continuous Speech Separation
Apr 13, 2019
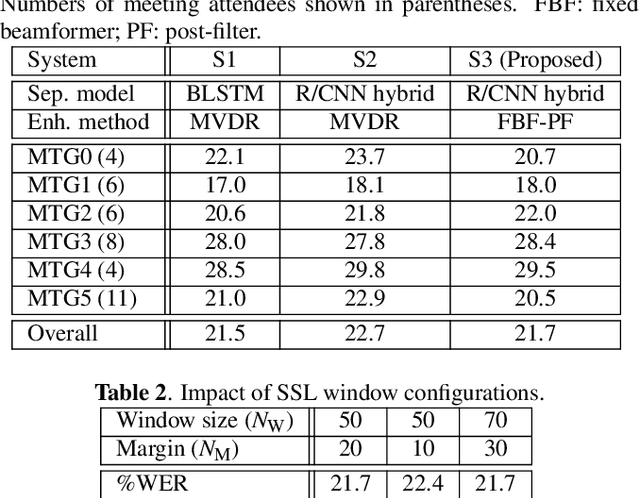

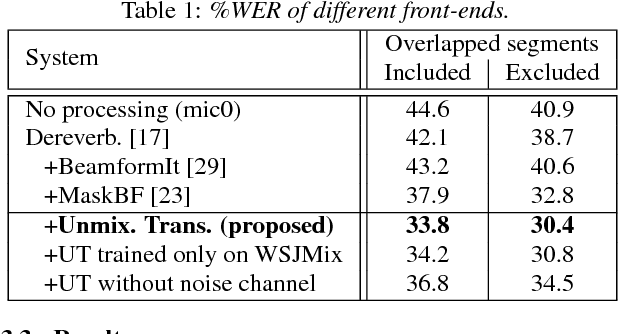
Speaker independent continuous speech separation (SI-CSS) is a task of converting a continuous audio stream, which may contain overlapping voices of unknown speakers, into a fixed number of continuous signals each of which contains no overlapping speech segment. A separated, or cleaned, version of each utterance is generated from one of SI-CSS's output channels nondeterministically without being split up and distributed to multiple channels. A typical application scenario is transcribing multi-party conversations, such as meetings, recorded with microphone arrays. The output signals can be simply sent to a speech recognition engine because they do not include speech overlaps. The previous SI-CSS method uses a neural network trained with permutation invariant training and a data-driven beamformer and thus requires much processing latency. This paper proposes a low-latency SI-CSS method whose performance is comparable to that of the previous method in a microphone array-based meeting transcription task.This is achieved (1) by using a new speech separation network architecture combined with a double buffering scheme and (2) by performing enhancement with a set of fixed beamformers followed by a neural post-filter.
Recognizing Overlapped Speech in Meetings: A Multichannel Separation Approach Using Neural Networks
Oct 08, 2018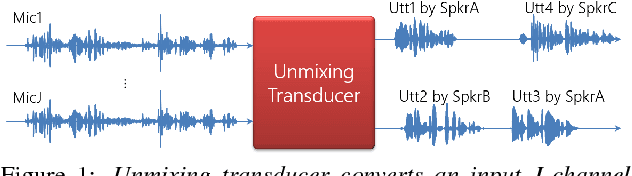
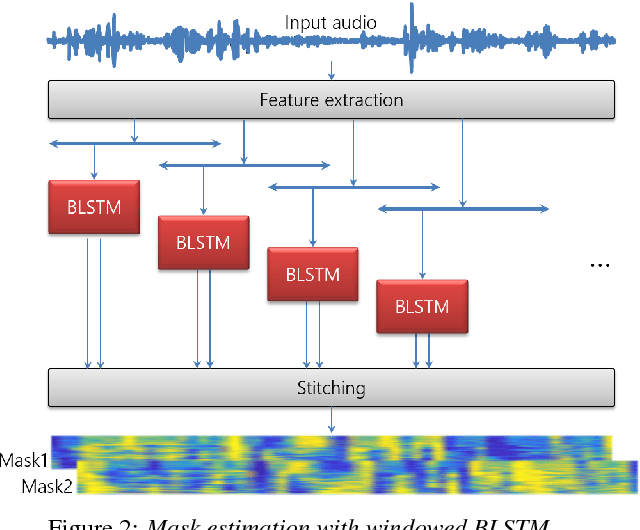
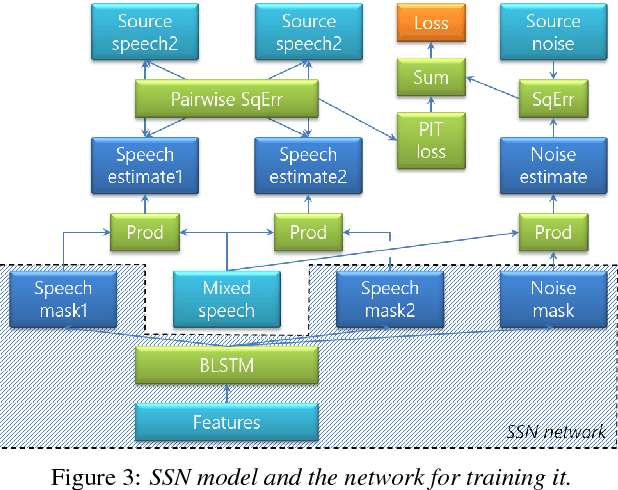
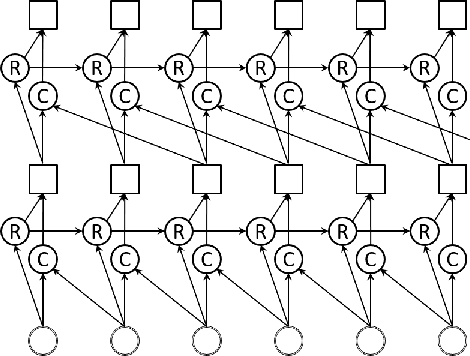
The goal of this work is to develop a meeting transcription system that can recognize speech even when utterances of different speakers are overlapped. While speech overlaps have been regarded as a major obstacle in accurately transcribing meetings, a traditional beamformer with a single output has been exclusively used because previously proposed speech separation techniques have critical constraints for application to real meetings. This paper proposes a new signal processing module, called an unmixing transducer, and describes its implementation using a windowed BLSTM. The unmixing transducer has a fixed number, say J, of output channels, where J may be different from the number of meeting attendees, and transforms an input multi-channel acoustic signal into J time-synchronous audio streams. Each utterance in the meeting is separated and emitted from one of the output channels. Then, each output signal can be simply fed to a speech recognition back-end for segmentation and transcription. Our meeting transcription system using the unmixing transducer outperforms a system based on a state-of-the-art neural mask-based beamformer by 10.8%. Significant improvements are observed in overlapped segments. To the best of our knowledge, this is the first report that applies overlapped speech recognition to unconstrained real meeting audio.
Deep Long Short-Term Memory Adaptive Beamforming Networks For Multichannel Robust Speech Recognition
Nov 21, 2017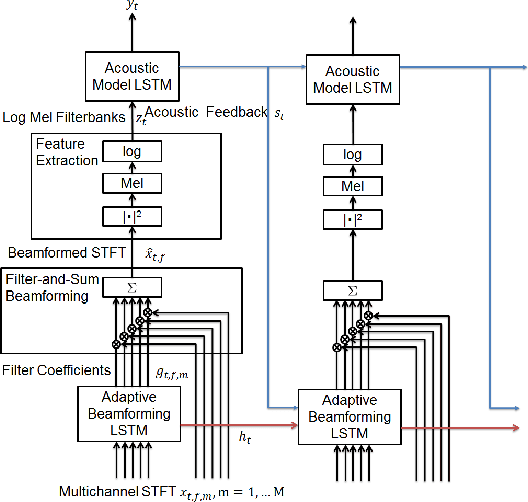
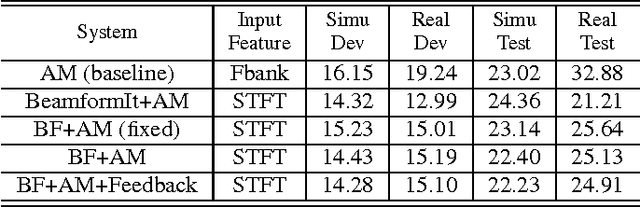
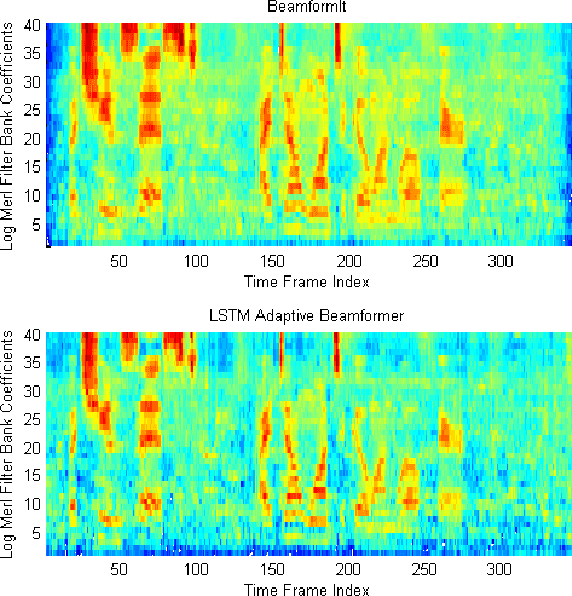
Far-field speech recognition in noisy and reverberant conditions remains a challenging problem despite recent deep learning breakthroughs. This problem is commonly addressed by acquiring a speech signal from multiple microphones and performing beamforming over them. In this paper, we propose to use a recurrent neural network with long short-term memory (LSTM) architecture to adaptively estimate real-time beamforming filter coefficients to cope with non-stationary environmental noise and dynamic nature of source and microphones positions which results in a set of timevarying room impulse responses. The LSTM adaptive beamformer is jointly trained with a deep LSTM acoustic model to predict senone labels. Further, we use hidden units in the deep LSTM acoustic model to assist in predicting the beamforming filter coefficients. The proposed system achieves 7.97% absolute gain over baseline systems with no beamforming on CHiME-3 real evaluation set.
* in 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)
Confidence-Based Dynamic Classifier Combination For Mean-Shift Tracking
Jul 22, 2014
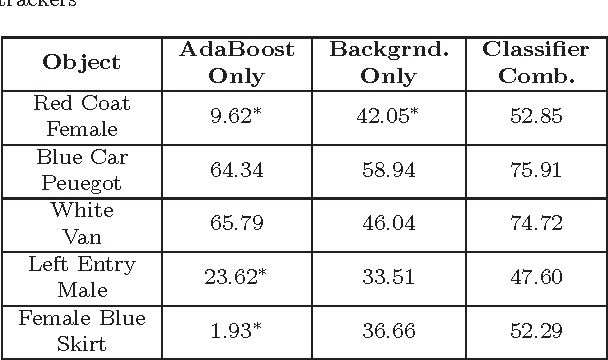


We introduce a novel tracking technique which uses dynamic confidence-based fusion of two different information sources for robust and efficient tracking of visual objects. Mean-shift tracking is a popular and well known method used in object tracking problems. Originally, the algorithm uses a similarity measure which is optimized by shifting a search area to the center of a generated weight image to track objects. Recent improvements on the original mean-shift algorithm involves using a classifier that differentiates the object from its surroundings. We adopt this classifier-based approach and propose an application of a classifier fusion technique within this classifier-based context in this work. We use two different classifiers, where one comes from a background modeling method, to generate the weight image and we calculate contributions of the classifiers dynamically using their confidences to generate a final weight image to be used in tracking. The contributions of the classifiers are calculated by using correlations between histograms of their weight images and histogram of a defined ideal weight image in the previous frame. We show with experiments that our dynamic combination scheme selects good contributions for classifiers for different cases and improves tracking accuracy significantly.
Deep neural networks for single channel source separation
Nov 12, 2013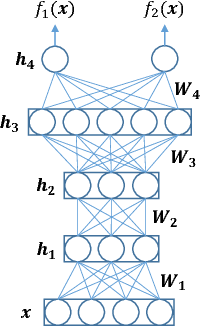
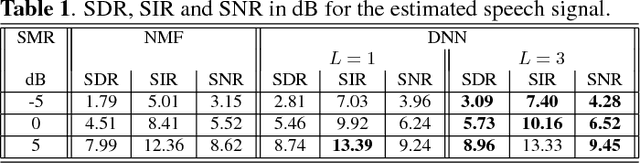
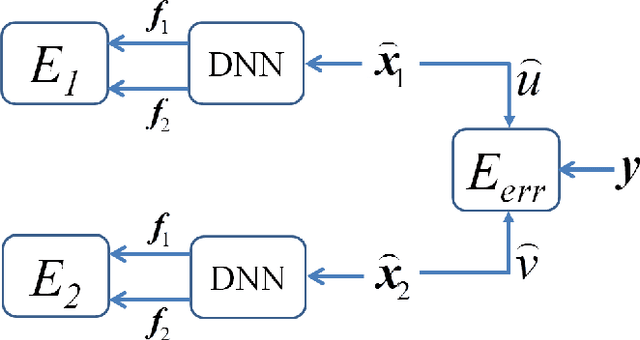
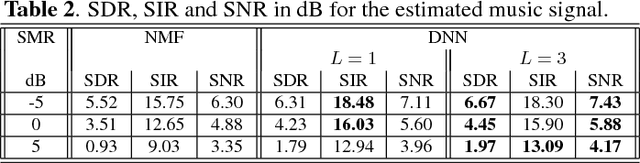
In this paper, a novel approach for single channel source separation (SCSS) using a deep neural network (DNN) architecture is introduced. Unlike previous studies in which DNN and other classifiers were used for classifying time-frequency bins to obtain hard masks for each source, we use the DNN to classify estimated source spectra to check for their validity during separation. In the training stage, the training data for the source signals are used to train a DNN. In the separation stage, the trained DNN is utilized to aid in estimation of each source in the mixed signal. Single channel source separation problem is formulated as an energy minimization problem where each source spectra estimate is encouraged to fit the trained DNN model and the mixed signal spectrum is encouraged to be written as a weighted sum of the estimated source spectra. The proposed approach works regardless of the energy scale differences between the source signals in the training and separation stages. Nonnegative matrix factorization (NMF) is used to initialize the DNN estimate for each source. The experimental results show that using DNN initialized by NMF for source separation improves the quality of the separated signal compared with using NMF for source separation.
Source Separation using Regularized NMF with MMSE Estimates under GMM Priors with Online Learning for The Uncertainties
Feb 28, 2013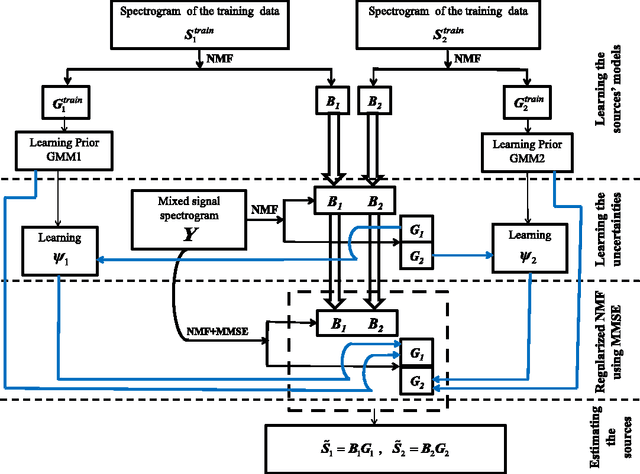

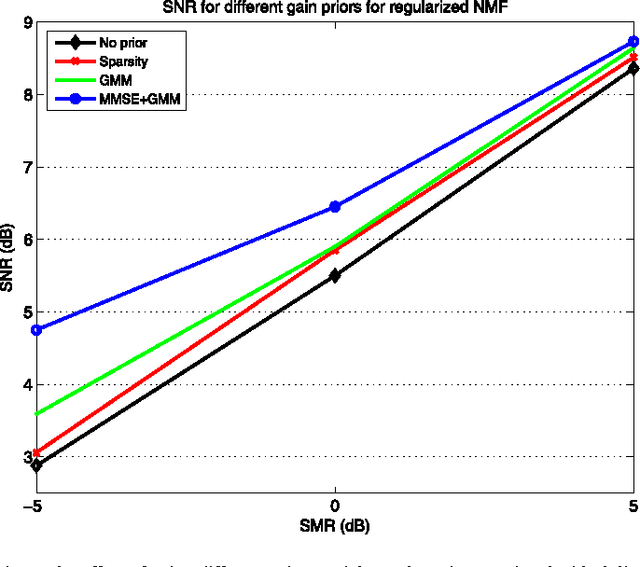
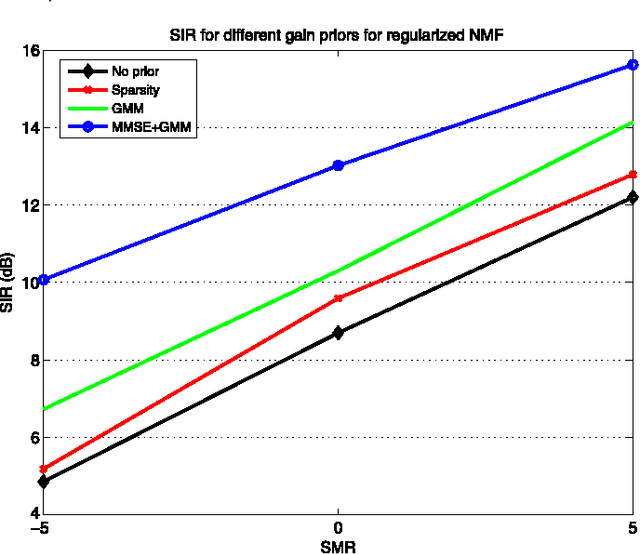
We propose a new method to enforce priors on the solution of the nonnegative matrix factorization (NMF). The proposed algorithm can be used for denoising or single-channel source separation (SCSS) applications. The NMF solution is guided to follow the Minimum Mean Square Error (MMSE) estimates under Gaussian mixture prior models (GMM) for the source signal. In SCSS applications, the spectra of the observed mixed signal are decomposed as a weighted linear combination of trained basis vectors for each source using NMF. In this work, the NMF decomposition weight matrices are treated as a distorted image by a distortion operator, which is learned directly from the observed signals. The MMSE estimate of the weights matrix under GMM prior and log-normal distribution for the distortion is then found to improve the NMF decomposition results. The MMSE estimate is embedded within the optimization objective to form a novel regularized NMF cost function. The corresponding update rules for the new objectives are derived in this paper. Experimental results show that, the proposed regularized NMF algorithm improves the source separation performance compared with using NMF without prior or with other prior models.
Max-Margin Stacking and Sparse Regularization for Linear Classifier Combination and Selection
Jun 08, 2011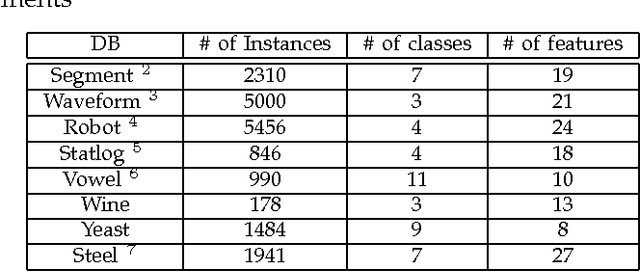
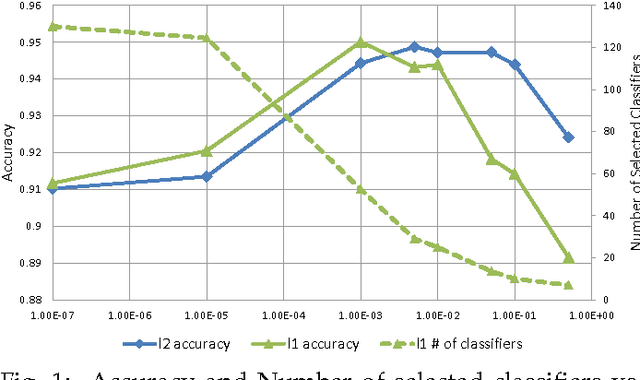
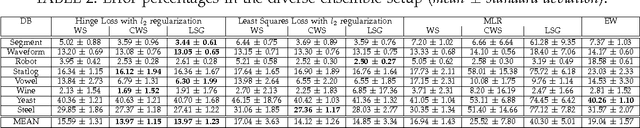
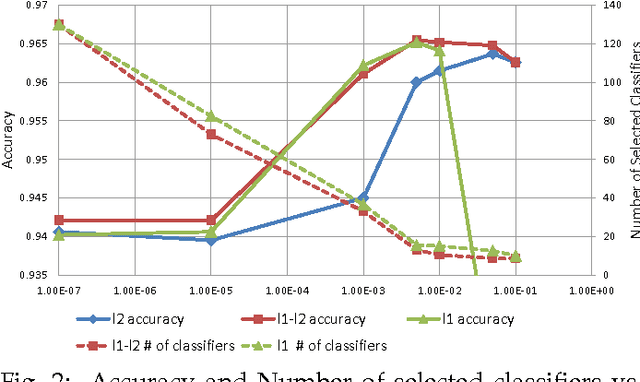
The main principle of stacked generalization (or Stacking) is using a second-level generalizer to combine the outputs of base classifiers in an ensemble. In this paper, we investigate different combination types under the stacking framework; namely weighted sum (WS), class-dependent weighted sum (CWS) and linear stacked generalization (LSG). For learning the weights, we propose using regularized empirical risk minimization with the hinge loss. In addition, we propose using group sparsity for regularization to facilitate classifier selection. We performed experiments using two different ensemble setups with differing diversities on 8 real-world datasets. Results show the power of regularized learning with the hinge loss function. Using sparse regularization, we are able to reduce the number of selected classifiers of the diverse ensemble without sacrificing accuracy. With the non-diverse ensembles, we even gain accuracy on average by using sparse regularization.