 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan 3D point cloud data improve automated body condition score prediction in dairy cattle?
Jan 30, 2026Body condition score (BCS) is a widely used indicator of body energy status and is closely associated with metabolic status, reproductive performance, and health in dairy cattle; however, conventional visual scoring is subjective and labor-intensive. Computer vision approaches have been applied to BCS prediction, with depth images widely used because they capture geometric information independent of coat color and texture. More recently, three-dimensional point cloud data have attracted increasing interest due to their ability to represent richer geometric characteristics of animal morphology, but direct head-to-head comparisons with depth image-based approaches remain limited. In this study, we compared top-view depth image and point cloud data for BCS prediction under four settings: 1) unsegmented raw data, 2) segmented full-body data, 3) segmented hindquarter data, and 4) handcrafted feature data. Prediction models were evaluated using data from 1,020 dairy cows collected on a commercial farm, with cow-level cross-validation to prevent data leakage. Depth image-based models consistently achieved higher accuracy than point cloud-based models when unsegmented raw data and segmented full-body data were used, whereas comparable performance was observed when segmented hindquarter data were used. Both depth image and point cloud approaches showed reduced accuracy when handcrafted feature data were employed compared with the other settings. Overall, point cloud-based predictions were more sensitive to noise and model architecture than depth image-based predictions. Taken together, these results indicate that three-dimensional point clouds do not provide a consistent advantage over depth images for BCS prediction in dairy cattle under the evaluated conditions.
Evaluating transfer learning strategies for improving dairy cattle body weight prediction in small farms using depth-image and point-cloud data
Jan 03, 2026Computer vision provides automated, non-invasive, and scalable tools for monitoring dairy cattle, thereby supporting management, health assessment, and phenotypic data collection. Although transfer learning is commonly used for predicting body weight from images, its effectiveness and optimal fine-tuning strategies remain poorly understood in livestock applications, particularly beyond the use of pretrained ImageNet or COCO weights. In addition, while both depth images and three-dimensional point-cloud data have been explored for body weight prediction, direct comparisons of these two modalities in dairy cattle are limited. Therefore, the objectives of this study were to 1) evaluate whether transfer learning from a large farm enhances body weight prediction on a small farm with limited data, and 2) compare the predictive performance of depth-image- and point-cloud-based approaches under three experimental designs. Top-view depth images and point-cloud data were collected from 1,201, 215, and 58 cows at large, medium, and small dairy farms, respectively. Four deep learning models were evaluated: ConvNeXt and MobileViT for depth images, and PointNet and DGCNN for point clouds. Transfer learning markedly improved body weight prediction on the small farm across all four models, outperforming single-source learning and achieving gains comparable to or greater than joint learning. These results indicate that pretrained representations generalize well across farms with differing imaging conditions and dairy cattle populations. No consistent performance difference was observed between depth-image- and point-cloud-based models. Overall, these findings suggest that transfer learning is well suited for small farm prediction scenarios where cross-farm data sharing is limited by privacy, logistical, or policy constraints, as it requires access only to pretrained model weights rather than raw data.
Technical note: ShinyAnimalCV: open-source cloud-based web application for object detection, segmentation, and three-dimensional visualization of animals using computer vision
Jul 26, 2023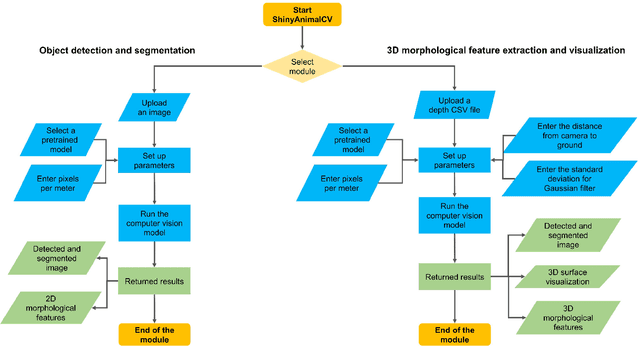

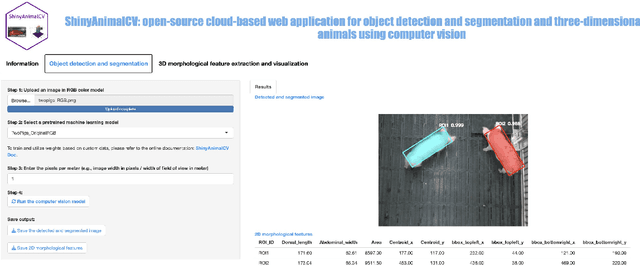
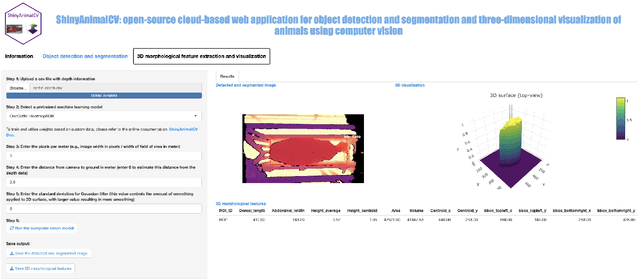
Computer vision (CV), a non-intrusive and cost-effective technology, has furthered the development of precision livestock farming by enabling optimized decision-making through timely and individualized animal care. The availability of affordable two- and three-dimensional camera sensors, combined with various machine learning and deep learning algorithms, has provided a valuable opportunity to improve livestock production systems. However, despite the availability of various CV tools in the public domain, applying these tools to animal data can be challenging, often requiring users to have programming and data analysis skills, as well as access to computing resources. Moreover, the rapid expansion of precision livestock farming is creating a growing need to educate and train animal science students in CV. This presents educators with the challenge of efficiently demonstrating the complex algorithms involved in CV. Thus, the objective of this study was to develop ShinyAnimalCV, an open-source cloud-based web application. This application provides a user-friendly interface for performing CV tasks, including object segmentation, detection, three-dimensional surface visualization, and extraction of two- and three-dimensional morphological features. Nine pre-trained CV models using top-view animal data are included in the application. ShinyAnimalCV has been deployed online using cloud computing platforms. The source code of ShinyAnimalCV is available on GitHub, along with detailed documentation on training CV models using custom data and deploying ShinyAnimalCV locally to allow users to fully leverage the capabilities of the application. ShinyAnimalCV can contribute to CV research and teaching in the animal science community.
Depth video data-enabled predictions of longitudinal dairy cow body weight using thresholding and Mask R-CNN algorithms
Jul 03, 2023



Monitoring cow body weight is crucial to support farm management decisions due to its direct relationship with the growth, nutritional status, and health of dairy cows. Cow body weight is a repeated trait, however, the majority of previous body weight prediction research only used data collected at a single point in time. Furthermore, the utility of deep learning-based segmentation for body weight prediction using videos remains unanswered. Therefore, the objectives of this study were to predict cow body weight from repeatedly measured video data, to compare the performance of the thresholding and Mask R-CNN deep learning approaches, to evaluate the predictive ability of body weight regression models, and to promote open science in the animal science community by releasing the source code for video-based body weight prediction. A total of 40,405 depth images and depth map files were obtained from 10 lactating Holstein cows and 2 non-lactating Jersey cows. Three approaches were investigated to segment the cow's body from the background, including single thresholding, adaptive thresholding, and Mask R-CNN. Four image-derived biometric features, such as dorsal length, abdominal width, height, and volume, were estimated from the segmented images. On average, the Mask-RCNN approach combined with a linear mixed model resulted in the best prediction coefficient of determination and mean absolute percentage error of 0.98 and 2.03%, respectively, in the forecasting cross-validation. The Mask-RCNN approach was also the best in the leave-three-cows-out cross-validation. The prediction coefficients of determination and mean absolute percentage error of the Mask-RCNN coupled with the linear mixed model were 0.90 and 4.70%, respectively. Our results suggest that deep learning-based segmentation improves the prediction performance of cow body weight from longitudinal depth video data.