 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGastroViT: A Vision Transformer Based Ensemble Learning Approach for Gastrointestinal Disease Classification with Grad CAM & SHAP Visualization
Sep 30, 2025The gastrointestinal (GI) tract of humans can have a wide variety of aberrant mucosal abnormality findings, ranging from mild irritations to extremely fatal illnesses. Prompt identification of gastrointestinal disorders greatly contributes to arresting the progression of the illness and improving therapeutic outcomes. This paper presents an ensemble of pre-trained vision transformers (ViTs) for accurately classifying endoscopic images of the GI tract to categorize gastrointestinal problems and illnesses. ViTs, attention-based neural networks, have revolutionized image recognition by leveraging the transformative power of the transformer architecture, achieving state-of-the-art (SOTA) performance across various visual tasks. The proposed model was evaluated on the publicly available HyperKvasir dataset with 10,662 images of 23 different GI diseases for the purpose of identifying GI tract diseases. An ensemble method is proposed utilizing the predictions of two pre-trained models, MobileViT_XS and MobileViT_V2_200, which achieved accuracies of 90.57% and 90.48%, respectively. All the individual models are outperformed by the ensemble model, GastroViT, with an average precision, recall, F1 score, and accuracy of 69%, 63%, 64%, and 91.98%, respectively, in the first testing that involves 23 classes. The model comprises only 20 million (M) parameters, even without data augmentation and despite the highly imbalanced dataset. For the second testing with 16 classes, the scores are even higher, with average precision, recall, F1 score, and accuracy of 87%, 86%, 87%, and 92.70%, respectively. Additionally, the incorporation of explainable AI (XAI) methods such as Grad-CAM (Gradient Weighted Class Activation Mapping) and SHAP (Shapley Additive Explanations) enhances model interpretability, providing valuable insights for reliable GI diagnosis in real-world settings.
The Severity Prediction of The Binary And Multi-Class Cardiovascular Disease -- A Machine Learning-Based Fusion Approach
Mar 09, 2022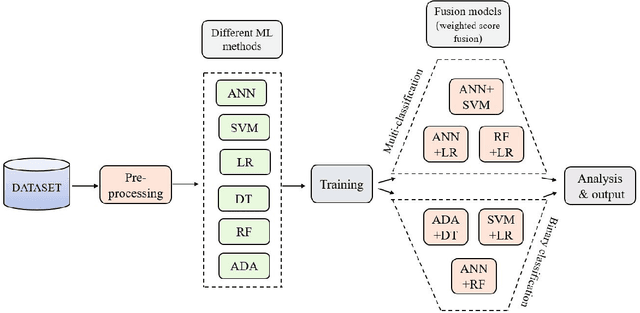
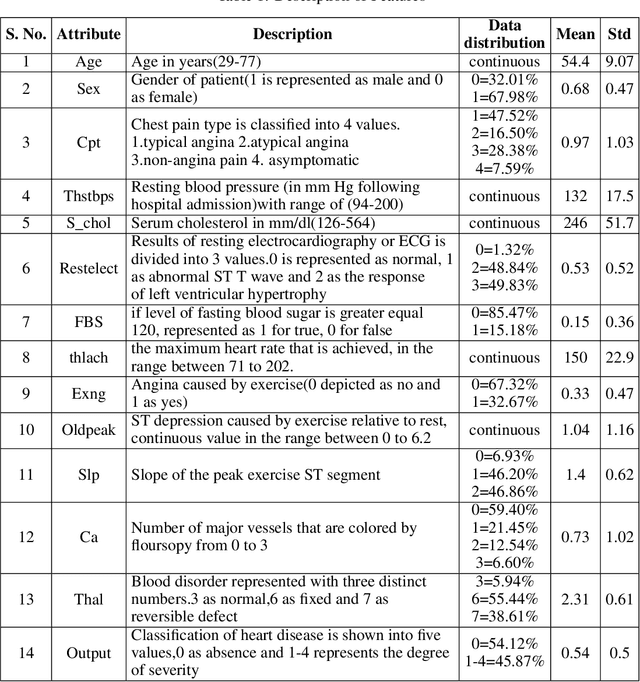
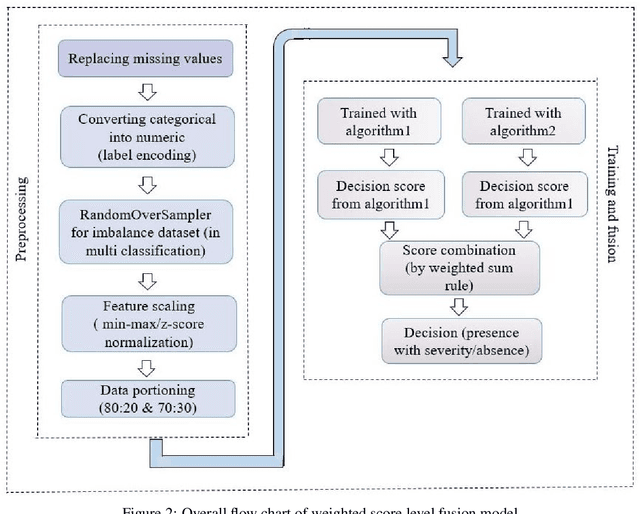
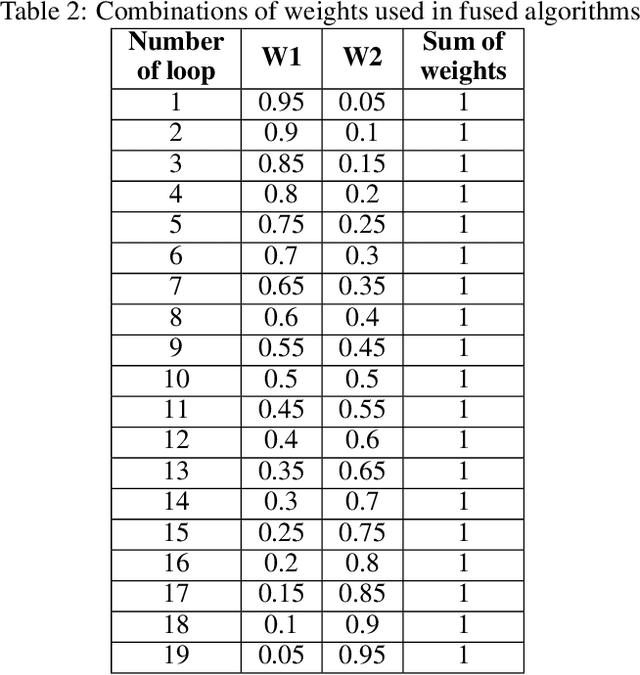
In today's world, a massive amount of data is available in almost every sector. This data has become an asset as we can use this enormous amount of data to find information. Mainly health care industry contains many data consisting of patient and disease-related information. By using the machine learning technique, we can look for hidden data patterns to predict various diseases. Recently CVDs, or cardiovascular disease, have become a leading cause of death around the world. The number of death due to CVDs is frightening. That is why many researchers are trying their best to design a predictive model that can save many lives using the data mining model. In this research, some fusion models have been constructed to diagnose CVDs along with its severity. Machine learning(ML) algorithms like artificial neural network, SVM, logistic regression, decision tree, random forest, and AdaBoost have been applied to the heart disease dataset to predict disease. Randomoversampler was implemented because of the class imbalance in multiclass classification. To improve the performance of classification, a weighted score fusion approach was taken. At first, the models were trained. After training, two algorithms' decision was combined using a weighted sum rule. A total of three fusion models have been developed from the six ML algorithms. The results were promising in the performance parameter. The proposed approach has been experimented with different test training ratios for binary and multiclass classification problems, and for both of them, the fusion models performed well. The highest accuracy for multiclass classification was found as 75%, and it was 95% for binary. The code can be found in : https://github.com/hafsa-kibria/Weighted_score_fusion_model_heart_disease_prediction