 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge-Guided Masked Autoencoder with Linear Spectral Mixing and Spectral-Angle-Aware Reconstruction
Dec 13, 2025Integrating domain knowledge into deep learning has emerged as a promising direction for improving model interpretability, generalization, and data efficiency. In this work, we present a novel knowledge-guided ViT-based Masked Autoencoder that embeds scientific domain knowledge within the self-supervised reconstruction process. Instead of relying solely on data-driven optimization, our proposed approach incorporates the Linear Spectral Mixing Model (LSMM) as a physical constraint and physically-based Spectral Angle Mapper (SAM), ensuring that learned representations adhere to known structural relationships between observed signals and their latent components. The framework jointly optimizes LSMM and SAM loss with a conventional Huber loss objective, promoting both numerical accuracy and geometric consistency in the feature space. This knowledge-guided design enhances reconstruction fidelity, stabilizes training under limited supervision, and yields interpretable latent representations grounded in physical principles. The experimental findings indicate that the proposed model substantially enhances reconstruction quality and improves downstream task performance, highlighting the promise of embedding physics-informed inductive biases within transformer-based self-supervised learning.
DeepSalt: Bridging Laboratory and Satellite Spectra through Domain Adaptation and Knowledge Distillation for Large-Scale Soil Salinity Estimation
Oct 27, 2025Soil salinization poses a significant threat to both ecosystems and agriculture because it limits plants' ability to absorb water and, in doing so, reduces crop productivity. This phenomenon alters the soil's spectral properties, creating a measurable relationship between salinity and light reflectance that enables remote monitoring. While laboratory spectroscopy provides precise measurements, its reliance on in-situ sampling limits scalability to regional or global levels. Conversely, hyperspectral satellite imagery enables wide-area observation but lacks the fine-grained interpretability of laboratory instruments. To bridge this gap, we introduce DeepSalt, a deep-learning-based spectral transfer framework that leverages knowledge distillation and a novel Spectral Adaptation Unit to transfer high-resolution spectral insights from laboratory-based spectroscopy to satellite-based hyperspectral sensing. Our approach eliminates the need for extensive ground sampling while enabling accurate, large-scale salinity estimation, as demonstrated through comprehensive empirical benchmarks. DeepSalt achieves significant performance gains over methods without explicit domain adaptation, underscoring the impact of the proposed Spectral Adaptation Unit and the knowledge distillation strategy. The model also effectively generalized to unseen geographic regions, explaining a substantial portion of the salinity variance.
TerraMAE: Learning Spatial-Spectral Representations from Hyperspectral Earth Observation Data via Adaptive Masked Autoencoders
Aug 09, 2025Hyperspectral satellite imagery offers sub-30 m views of Earth in hundreds of contiguous spectral bands, enabling fine-grained mapping of soils, crops, and land cover. While self-supervised Masked Autoencoders excel on RGB and low-band multispectral data, they struggle to exploit the intricate spatial-spectral correlations in 200+ band hyperspectral images. We introduce TerraMAE, a novel HSI encoding framework specifically designed to learn highly representative spatial-spectral embeddings for diverse geospatial analyses. TerraMAE features an adaptive channel grouping strategy, based on statistical reflectance properties to capture spectral similarities, and an enhanced reconstruction loss function that incorporates spatial and spectral quality metrics. We demonstrate TerraMAE's effectiveness through superior spatial-spectral information preservation in high-fidelity image reconstruction. Furthermore, we validate its practical utility and the quality of its learned representations through strong performance on three key downstream geospatial tasks: crop identification, land cover classification, and soil texture prediction.
The Severity Prediction of The Binary And Multi-Class Cardiovascular Disease -- A Machine Learning-Based Fusion Approach
Mar 09, 2022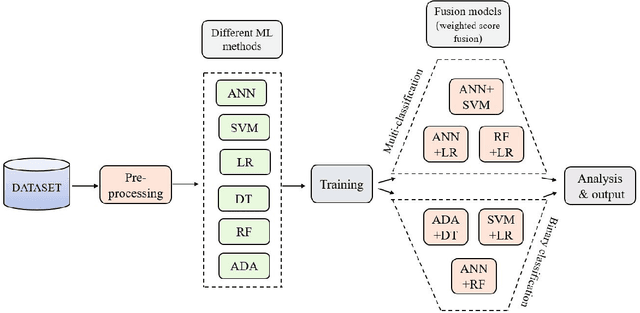
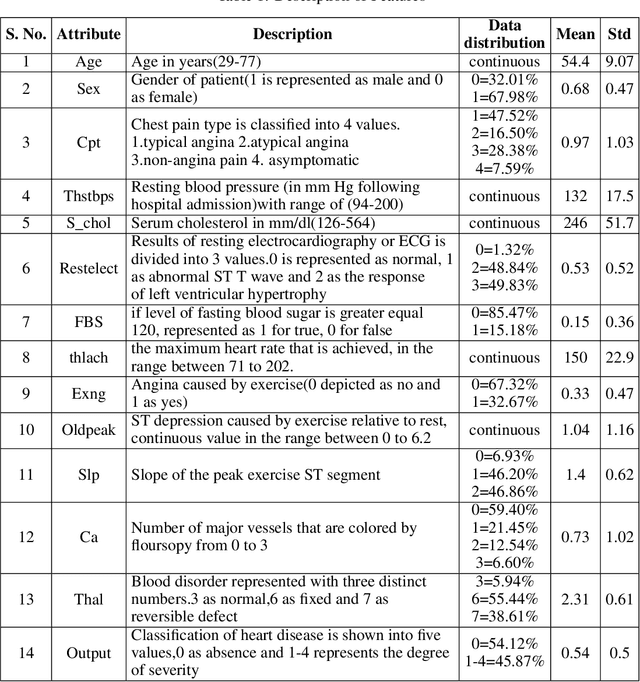
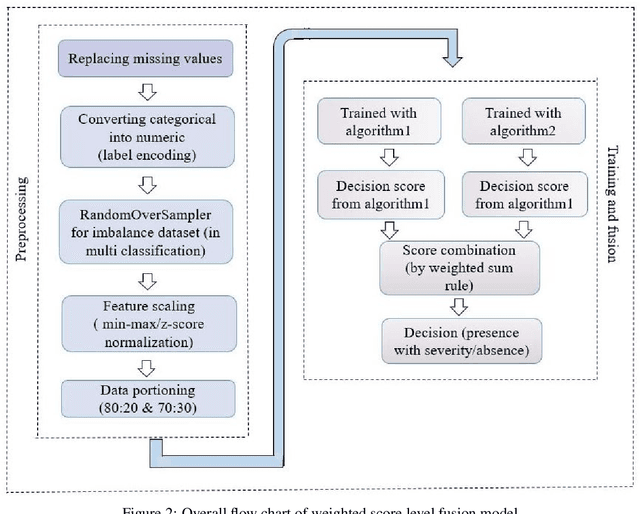
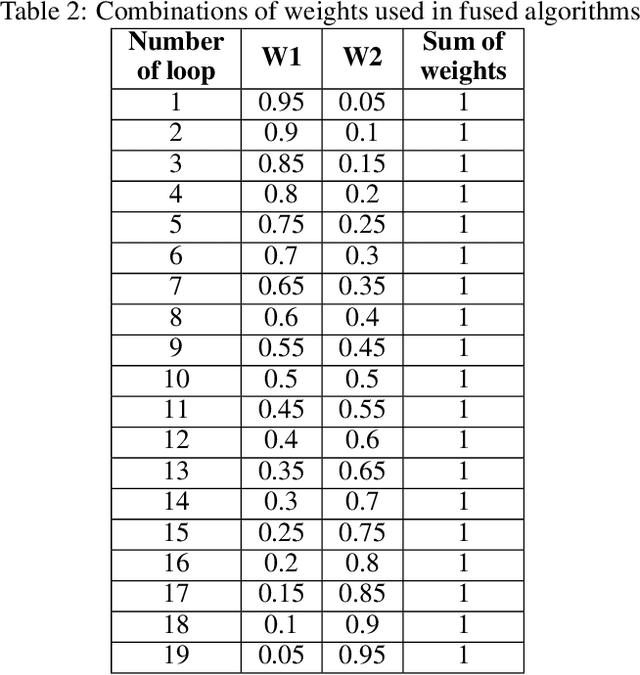
In today's world, a massive amount of data is available in almost every sector. This data has become an asset as we can use this enormous amount of data to find information. Mainly health care industry contains many data consisting of patient and disease-related information. By using the machine learning technique, we can look for hidden data patterns to predict various diseases. Recently CVDs, or cardiovascular disease, have become a leading cause of death around the world. The number of death due to CVDs is frightening. That is why many researchers are trying their best to design a predictive model that can save many lives using the data mining model. In this research, some fusion models have been constructed to diagnose CVDs along with its severity. Machine learning(ML) algorithms like artificial neural network, SVM, logistic regression, decision tree, random forest, and AdaBoost have been applied to the heart disease dataset to predict disease. Randomoversampler was implemented because of the class imbalance in multiclass classification. To improve the performance of classification, a weighted score fusion approach was taken. At first, the models were trained. After training, two algorithms' decision was combined using a weighted sum rule. A total of three fusion models have been developed from the six ML algorithms. The results were promising in the performance parameter. The proposed approach has been experimented with different test training ratios for binary and multiclass classification problems, and for both of them, the fusion models performed well. The highest accuracy for multiclass classification was found as 75%, and it was 95% for binary. The code can be found in : https://github.com/hafsa-kibria/Weighted_score_fusion_model_heart_disease_prediction