 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEXAONE 4.5 Technical Report
Apr 09, 2026This technical report introduces EXAONE 4.5, the first open-weight vision language model released by LG AI Research. EXAONE 4.5 is architected by integrating a dedicated visual encoder into the existing EXAONE 4.0 framework, enabling native multimodal pretraining over both visual and textual modalities. The model is trained on large-scale data with careful curation, particularly emphasizing document-centric corpora that align with LG's strategic application domains. This targeted data design enables substantial performance gains in document understanding and related tasks, while also delivering broad improvements across general language capabilities. EXAONE 4.5 extends context length up to 256K tokens, facilitating long-context reasoning and enterprise-scale use cases. Comparative evaluations demonstrate that EXAONE 4.5 achieves competitive performance in general benchmarks while outperforming state-of-the-art models of similar scale in document understanding and Korean contextual reasoning. As part of LG's ongoing effort toward practical industrial deployment, EXAONE 4.5 is designed to be continuously extended with additional domains and application scenarios to advance AI for a better life.
K-EXAONE Technical Report
Jan 05, 2026This technical report presents K-EXAONE, a large-scale multilingual language model developed by LG AI Research. K-EXAONE is built on a Mixture-of-Experts architecture with 236B total parameters, activating 23B parameters during inference. It supports a 256K-token context window and covers six languages: Korean, English, Spanish, German, Japanese, and Vietnamese. We evaluate K-EXAONE on a comprehensive benchmark suite spanning reasoning, agentic, general, Korean, and multilingual abilities. Across these evaluations, K-EXAONE demonstrates performance comparable to open-weight models of similar size. K-EXAONE, designed to advance AI for a better life, is positioned as a powerful proprietary AI foundation model for a wide range of industrial and research applications.
EXAONE 4.0: Unified Large Language Models Integrating Non-reasoning and Reasoning Modes
Jul 15, 2025This technical report introduces EXAONE 4.0, which integrates a Non-reasoning mode and a Reasoning mode to achieve both the excellent usability of EXAONE 3.5 and the advanced reasoning abilities of EXAONE Deep. To pave the way for the agentic AI era, EXAONE 4.0 incorporates essential features such as agentic tool use, and its multilingual capabilities are extended to support Spanish in addition to English and Korean. The EXAONE 4.0 model series consists of two sizes: a mid-size 32B model optimized for high performance, and a small-size 1.2B model designed for on-device applications. The EXAONE 4.0 demonstrates superior performance compared to open-weight models in its class and remains competitive even against frontier-class models. The models are publicly available for research purposes and can be easily downloaded via https://huggingface.co/LGAI-EXAONE.
EXAONE Deep: Reasoning Enhanced Language Models
Mar 16, 2025We present EXAONE Deep series, which exhibits superior capabilities in various reasoning tasks, including math and coding benchmarks. We train our models mainly on the reasoning-specialized dataset that incorporates long streams of thought processes. Evaluation results show that our smaller models, EXAONE Deep 2.4B and 7.8B, outperform other models of comparable size, while the largest model, EXAONE Deep 32B, demonstrates competitive performance against leading open-weight models. All EXAONE Deep models are openly available for research purposes and can be downloaded from https://huggingface.co/LGAI-EXAONE
EXAONE 3.5: Series of Large Language Models for Real-world Use Cases
Dec 09, 2024



This technical report introduces the EXAONE 3.5 instruction-tuned language models, developed and released by LG AI Research. The EXAONE 3.5 language models are offered in three configurations: 32B, 7.8B, and 2.4B. These models feature several standout capabilities: 1) exceptional instruction following capabilities in real-world scenarios, achieving the highest scores across seven benchmarks, 2) outstanding long-context comprehension, attaining the top performance in four benchmarks, and 3) competitive results compared to state-of-the-art open models of similar sizes across nine general benchmarks. The EXAONE 3.5 language models are open to anyone for research purposes and can be downloaded from https://huggingface.co/LGAI-EXAONE. For commercial use, please reach out to the official contact point of LG AI Research: contact_us@lgresearch.ai.
EXAONE 3.0 7.8B Instruction Tuned Language Model
Aug 07, 2024



We introduce EXAONE 3.0 instruction-tuned language model, the first open model in the family of Large Language Models (LLMs) developed by LG AI Research. Among different model sizes, we publicly release the 7.8B instruction-tuned model to promote open research and innovations. Through extensive evaluations across a wide range of public and in-house benchmarks, EXAONE 3.0 demonstrates highly competitive real-world performance with instruction-following capability against other state-of-the-art open models of similar size. Our comparative analysis shows that EXAONE 3.0 excels particularly in Korean, while achieving compelling performance across general tasks and complex reasoning. With its strong real-world effectiveness and bilingual proficiency, we hope that EXAONE keeps contributing to advancements in Expert AI. Our EXAONE 3.0 instruction-tuned model is available at https://huggingface.co/LGAI-EXAONE/EXAONE-3.0-7.8B-Instruct
Bayesian Multi-Task Transfer Learning for Soft Prompt Tuning
Feb 13, 2024



Prompt tuning, in which prompts are optimized to adapt large-scale pre-trained language models to downstream tasks instead of fine-tuning the full model parameters, has been shown to be particularly effective when the prompts are trained in a multi-task transfer learning setting. These methods generally involve individually training prompts for each source task and then aggregating them to provide the initialization of the prompt for the target task. However, this approach critically ignores the fact that some of the source tasks could be negatively or positively interfering with each other. We argue that when we extract knowledge from source tasks via training source prompts, we need to consider this correlation among source tasks for better transfer to target tasks. To this end, we propose a Bayesian approach where we work with the posterior distribution of prompts across source tasks. We obtain representative source prompts corresponding to the samples from the posterior utilizing Stein Variational Gradient Descent, which are then aggregated to constitute the initial target prompt. We show extensive experimental results on the standard benchmark NLP tasks, where our Bayesian multi-task transfer learning approach outperforms the state-of-the-art methods in many settings. Furthermore, our approach requires no auxiliary models other than the prompt itself, achieving a high degree of parameter efficiency.
Re3val: Reinforced and Reranked Generative Retrieval
Feb 06, 2024



Generative retrieval models encode pointers to information in a corpus as an index within the model's parameters. These models serve as part of a larger pipeline, where retrieved information conditions generation for knowledge-intensive NLP tasks. However, we identify two limitations: the generative retrieval does not account for contextual information. Secondly, the retrieval can't be tuned for the downstream readers as decoding the page title is a non-differentiable operation. This paper introduces Re3val, trained with generative reranking and reinforcement learning using limited data. Re3val leverages context acquired via Dense Passage Retrieval to rerank the retrieved page titles and utilizes REINFORCE to maximize rewards generated by constrained decoding. Additionally, we generate questions from our pre-training dataset to mitigate epistemic uncertainty and bridge the domain gap between the pre-training and fine-tuning datasets. Subsequently, we extract and rerank contexts from the KILT database using the rerank page titles. Upon grounding the top five reranked contexts, Re3val demonstrates the Top 1 KILT scores compared to all other generative retrieval models across five KILT datasets.
Augment & Valuate : A Data Enhancement Pipeline for Data-Centric AI
Dec 07, 2021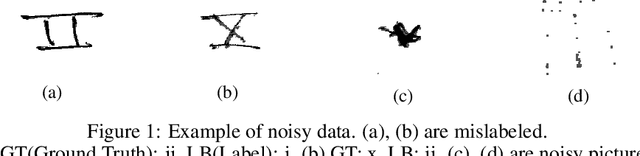



Data scarcity and noise are important issues in industrial applications of machine learning. However, it is often challenging to devise a scalable and generalized approach to address the fundamental distributional and semantic properties of dataset with black box models. For this reason, data-centric approaches are crucial for the automation of machine learning operation pipeline. In order to serve as the basis for this automation, we suggest a domain-agnostic pipeline for refining the quality of data in image classification problems. This pipeline contains data valuation, cleansing, and augmentation. With an appropriate combination of these methods, we could achieve 84.711% test accuracy (ranked #6, Honorable Mention in the Most Innovative) in the Data-Centric AI competition only with the provided dataset.