 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeighted Fisher Discriminant Analysis in the Input and Feature Spaces
Apr 04, 2020
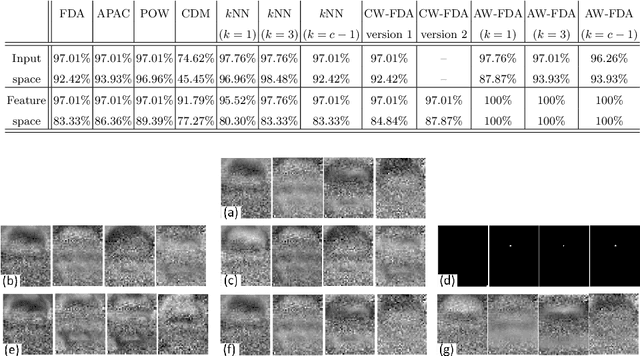
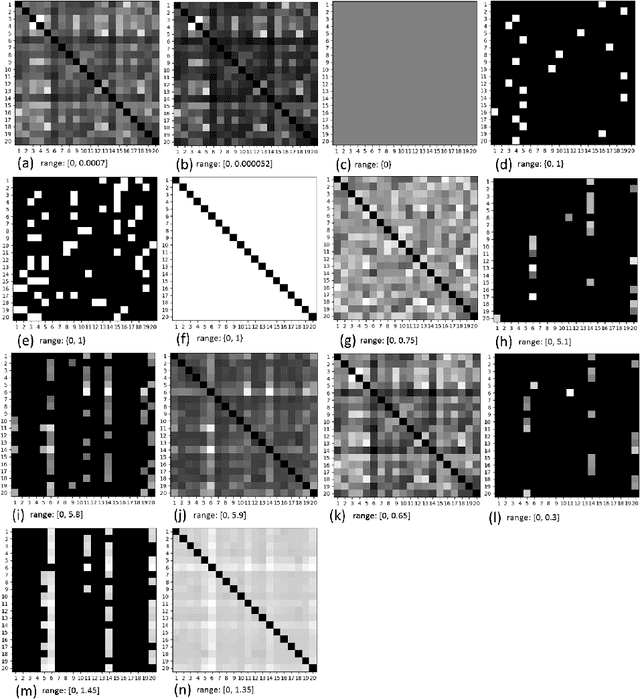
Fisher Discriminant Analysis (FDA) is a subspace learning method which minimizes and maximizes the intra- and inter-class scatters of data, respectively. Although, in FDA, all the pairs of classes are treated the same way, some classes are closer than the others. Weighted FDA assigns weights to the pairs of classes to address this shortcoming of FDA. In this paper, we propose a cosine-weighted FDA as well as an automatically weighted FDA in which weights are found automatically. We also propose a weighted FDA in the feature space to establish a weighted kernel FDA for both existing and newly proposed weights. Our experiments on the ORL face recognition dataset show the effectiveness of the proposed weighting schemes.
Yottixel -- An Image Search Engine for Large Archives of Histopathology Whole Slide Images
Nov 20, 2019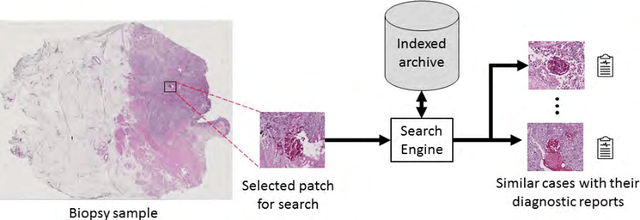
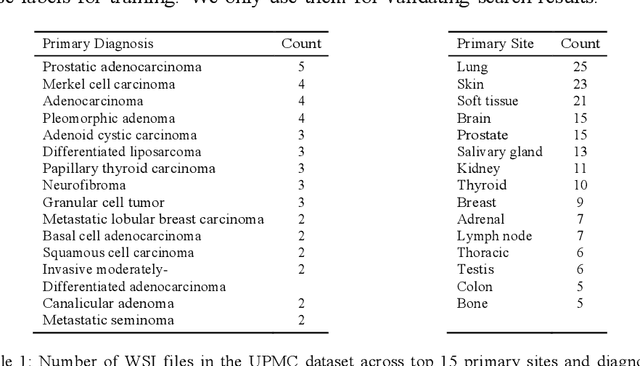
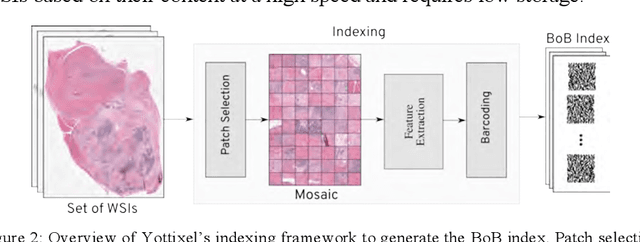

With the emergence of digital pathology, searching for similar images in large archives has gained considerable attention. Image retrieval can provide pathologists with unprecedented access to the evidence embodied in already diagnosed and treated cases from the past. This paper proposes a search engine specialized for digital pathology, called Yottixel, a portmanteau for "one yotta pixel," alluding to the big-data nature of histopathology images. The most impressive characteristic of Yottixel is its ability to represent whole slide images (WSIs) in a compact manner. Yottixel can perform millions of searches in real-time with a high search accuracy and low storage profile. Yottixel uses an intelligent indexing algorithm capable of representing WSIs with a mosaic of patches by converting them into a small number of methodically extracted barcodes, called "Bunch of Barcodes" (BoB), the most prominent performance enabler of Yottixel. The performance of the prototype platform is qualitatively tested using 300 WSIs from the University of Pittsburgh Medical Center (UPMC) and 2,020 WSIs from The Cancer Genome Atlas Program (TCGA) provided by the National Cancer Institute. Both datasets amount to more than 4,000,000 patches of 1000x1000 pixels. We report three sets of experiments that show that Yottixel can accurately retrieve organs and malignancies, and its semantic ordering shows good agreement with the subjective evaluation of human observers.
Pan-Cancer Diagnostic Consensus Through Searching Archival Histopathology Images Using Artificial Intelligence
Nov 20, 2019
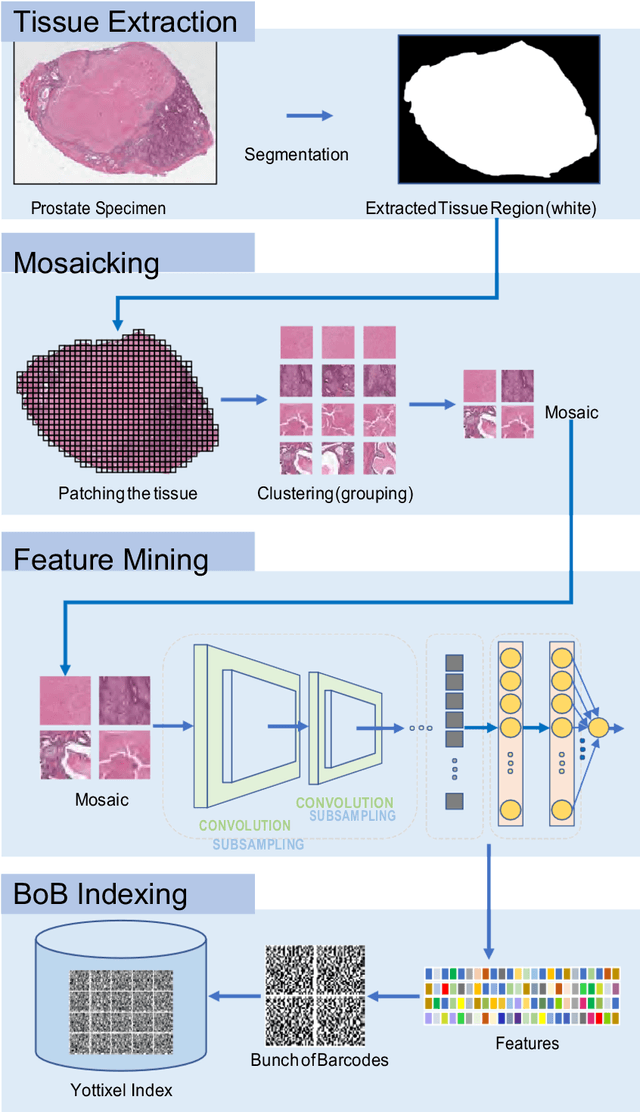
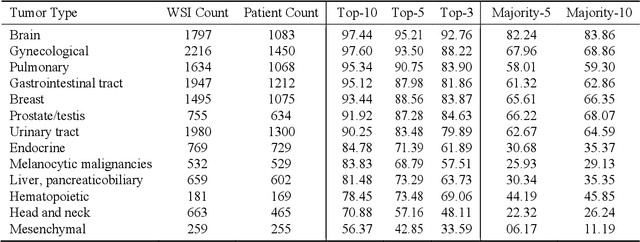
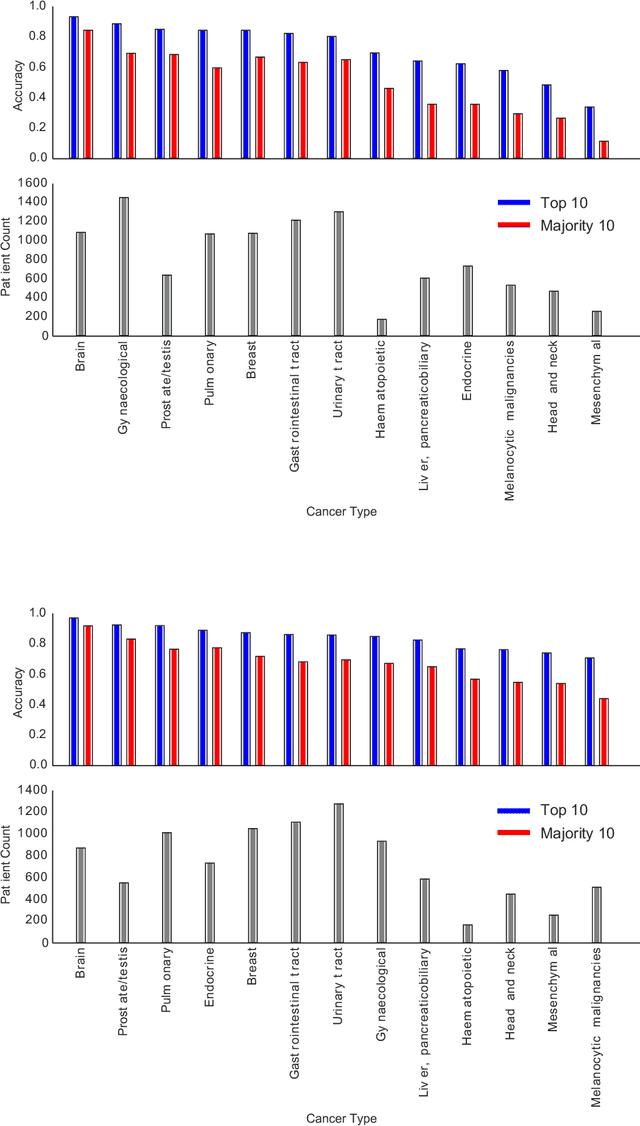
The emergence of digital pathology has opened new horizons for histopathology and cytology. Artificial-intelligence algorithms are able to operate on digitized slides to assist pathologists with diagnostic tasks. Whereas machine learning involving classification and segmentation methods have obvious benefits for image analysis in pathology, image search represents a fundamental shift in computational pathology. Matching the pathology of new patients with already diagnosed and curated cases offers pathologist a novel approach to improve diagnostic accuracy through visual inspection of similar cases and computational majority vote for consensus building. In this study, we report the results from searching the largest public repository (The Cancer Genome Atlas [TCGA] program by National Cancer Institute, USA) of whole slide images from almost 11,000 patients depicting different types of malignancies. For the first time, we successfully indexed and searched almost 30,000 high-resolution digitized slides constituting 16 terabytes of data comprised of 20 million 1000x1000 pixels image patches. The TCGA image database covers 25 anatomic sites and contains 32 cancer subtypes. High-performance storage and GPU power were employed for experimentation. The results were assessed with conservative "majority voting" to build consensus for subtype diagnosis through vertical search and demonstrated high accuracy values for both frozen sections slides (e.g., bladder urothelial carcinoma 93%, kidney renal clear cell carcinoma 97%, and ovarian serous cystadenocarcinoma 99%) and permanent histopathology slides (e.g., prostate adenocarcinoma 98%, skin cutaneous melanoma 99%, and thymoma 100%). The key finding of this validation study was that computational consensus appears to be possible for rendering diagnoses if a sufficiently large number of searchable cases are available for each cancer subtype.
Subtractive Perceptrons for Learning Images: A Preliminary Report
Sep 15, 2019
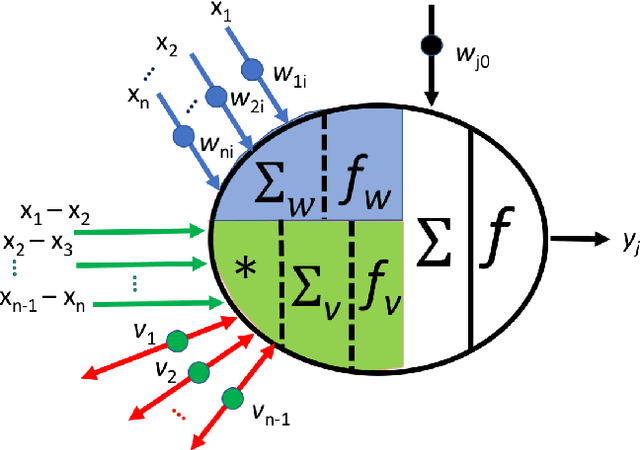
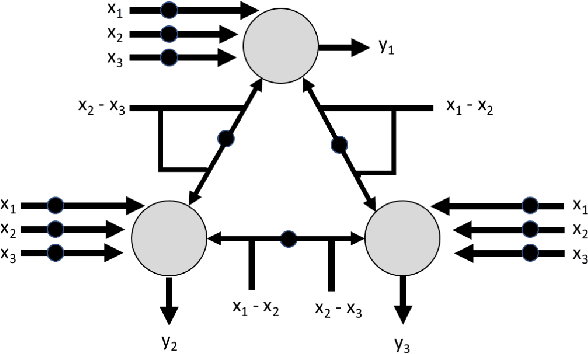
In recent years, artificial neural networks have achieved tremendous success for many vision-based tasks. However, this success remains within the paradigm of \emph{weak AI} where networks, among others, are specialized for just one given task. The path toward \emph{strong AI}, or Artificial General Intelligence, remains rather obscure. One factor, however, is clear, namely that the feed-forward structure of current networks is not a realistic abstraction of the human brain. In this preliminary work, some ideas are proposed to define a \textit{subtractive Perceptron} (s-Perceptron), a graph-based neural network that delivers a more compact topology to learn one specific task. In this preliminary study, we test the s-Perceptron with the MNIST dataset, a commonly used image archive for digit recognition. The proposed network achieves excellent results compared to the benchmark networks that rely on more complex topologies.
Atrial Fibrillation Detection Using Deep Features and Convolutional Networks
Mar 28, 2019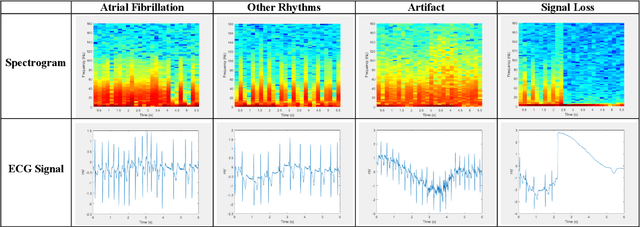
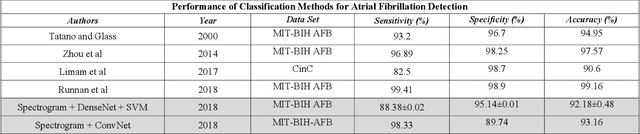

Atrial fibrillation is a cardiac arrhythmia that affects an estimated 33.5 million people globally and is the potential cause of 1 in 3 strokes in people over the age of 60. Detection and diagnosis of atrial fibrillation (AFIB) is done noninvasively in the clinical environment through the evaluation of electrocardiograms (ECGs). Early research into automated methods for the detection of AFIB in ECG signals focused on traditional bio-medical signal analysis to extract important features for use in statistical classification models. Artificial intelligence models have more recently been used that employ convolutional and/or recurrent network architectures. In this work, significant time and frequency domain characteristics of the ECG signal are extracted by applying the short-time Fourier trans-form and then visually representing the information in a spectrogram. Two different classification approaches were investigated that utilized deep features in the spectrograms construct-ed from ECG segments. The first approach used a pretrained DenseNet model to extract features that were then classified using Support Vector Machines, and the second approach used the spectrograms as direct input into a convolutional network. Both approaches were evaluated against the MIT-BIH AFIB dataset, where the convolutional network approach achieved a classification accuracy of 93.16%. While these results do not surpass established automated atrial fibrillation detection methods, they are promising and warrant further investigation given they did not require any noise prefiltering, hand-crafted features, nor a reliance on beat detection.
Patch Clustering for Representation of Histopathology Images
Mar 17, 2019
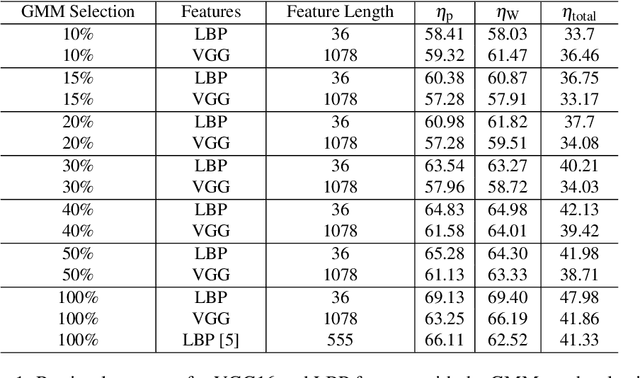
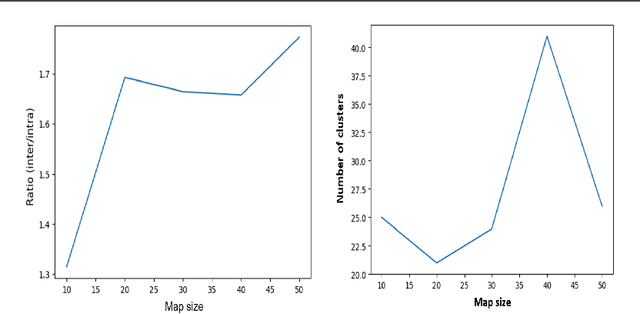
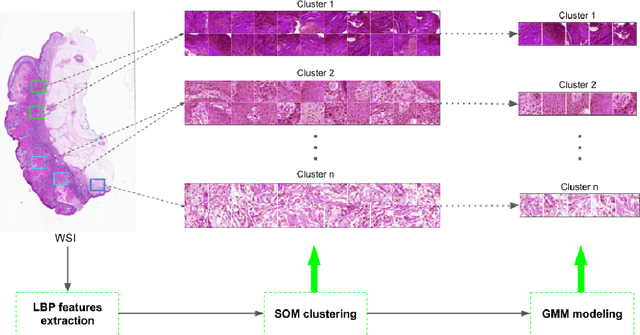
Whole Slide Imaging (WSI) has become an important topic during the last decade. Even though significant progress in both medical image processing and computational resources has been achieved, there are still problems in WSI that need to be solved. A major challenge is the scan size. The dimensions of digitized tissue samples may exceed 100,000 by 100,000 pixels causing memory and efficiency obstacles for real-time processing. The main contribution of this work is representing a WSI by selecting a small number of patches for algorithmic processing (e.g., indexing and search). As a result, we reduced the search time and storage by various factors between ($50\% - 90\%$), while losing only a few percentages in the patch retrieval accuracy. A self-organizing map (SOM) has been applied on local binary patterns (LBP) and deep features of the KimiaPath24 dataset in order to cluster patches that share the same characteristics. We used a Gaussian mixture model (GMM) to represent each class with a rather small ($10\%-50\%$) portion of patches. The results showed that LBP features can outperform deep features. By selecting only $50\%$ of all patches after SOM clustering and GMM patch selection, we received $65\%$ accuracy for retrieval of the best match, while the maximum accuracy (using all patches) was $69\%$.
Deep Features for Tissue-Fold Detection in Histopathology Images
Mar 17, 2019
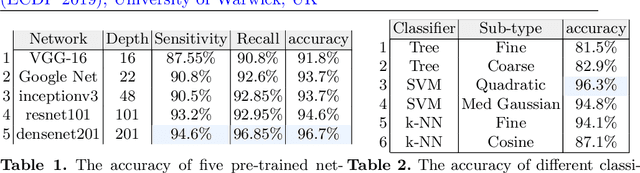
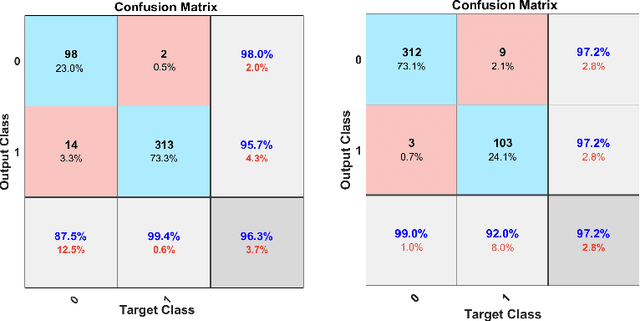

Whole slide imaging (WSI) refers to the digitization of a tissue specimen which enables pathologists to explore high-resolution images on a monitor rather than through a microscope. The formation of tissue folds occur during tissue processing. Their presence may not only cause out-of-focus digitization but can also negatively affect the diagnosis in some cases. In this paper, we have compared five pre-trained convolutional neural networks (CNNs) of different depths as feature extractors to characterize tissue folds. We have also explored common classifiers to discriminate folded tissue against the normal tissue in hematoxylin and eosin (H\&E) stained biopsy samples. In our experiments, we manually select the folded area in roughly 2.5mm $\times$ 2.5mm patches at $20$x magnification level as the training data. The ``DenseNet'' with 201 layers alongside an SVM classifier outperformed all other configurations. Based on the leave-one-out validation strategy, we achieved $96.3\%$ accuracy, whereas with augmentation the accuracy increased to $97.2\%$. We have tested the generalization of our method with five unseen WSIs from the NIH (National Cancer Institute) dataset. The accuracy for patch-wise detection was $81\%$. One folded patch within an image suffices to flag the entire specimen for visual inspection.
Projectron -- A Shallow and Interpretable Network for Classifying Medical Images
Mar 15, 2019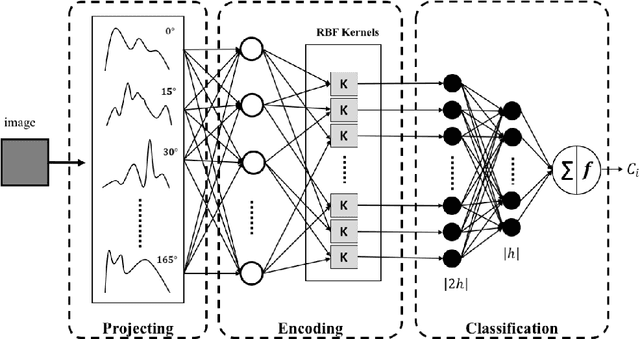
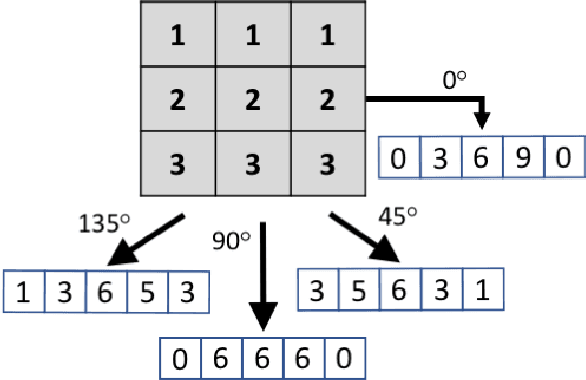
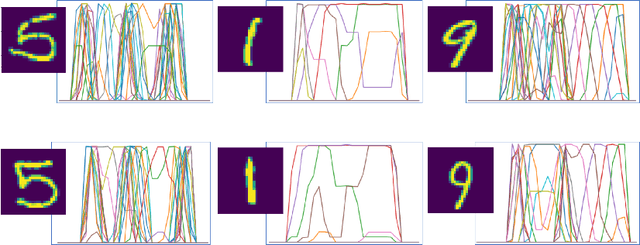
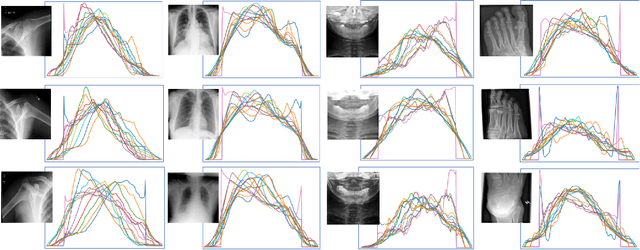
This paper introduces the `Projectron' as a new neural network architecture that uses Radon projections to both classify and represent medical images. The motivation is to build shallow networks which are more interpretable in the medical imaging domain. Radon transform is an established technique that can reconstruct images from parallel projections. The Projectron first applies global Radon transform to each image using equidistant angles and then feeds these transformations for encoding to a single layer of neurons followed by a layer of suitable kernels to facilitate a linear separation of projections. Finally, the Projectron provides the output of the encoding as an input to two more layers for final classification. We validate the Projectron on five publicly available datasets, a general dataset (namely MNIST) and four medical datasets (namely Emphysema, IDC, IRMA, and Pneumonia). The results are encouraging as we compared the Projectron's performance against MLPs with raw images and Radon projections as inputs, respectively. Experiments clearly demonstrate the potential of the proposed Projectron for representing/classifying medical images.
Facial Recognition with Encoded Local Projections
Sep 11, 2018
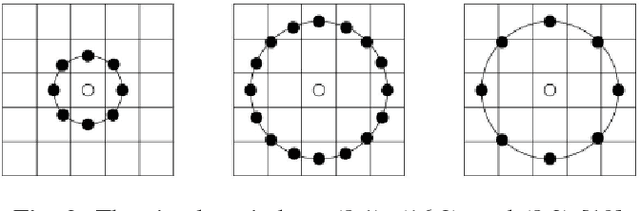

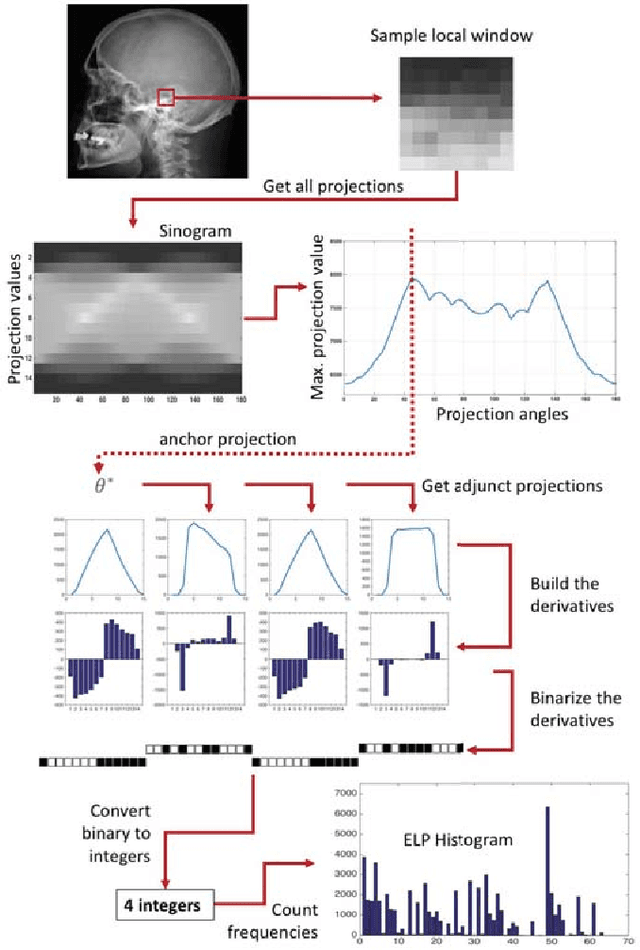
Encoded Local Projections (ELP) is a recently introduced dense sampling image descriptor which uses projections in small neighbourhoods to construct a histogram/descriptor for the entire image. ELP has shown to be as accurate as other state-of-the-art features in searching medical images while being time and resource efficient. This paper attempts for the first time to utilize ELP descriptor as primary features for facial recognition and compare the results with LBP histogram on the Labeled Faces in the Wild dataset. We have evaluated descriptors by comparing the chi-squared distance of each image descriptor versus all others as well as training Support Vector Machines (SVM) with each feature vector. In both cases, the results of ELP were better than LBP in the same sub-image configuration.
Auto-Detection of Safety Issues in Baby Products
Jul 21, 2018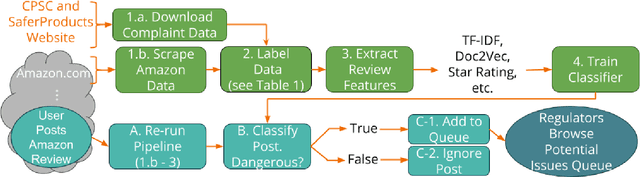
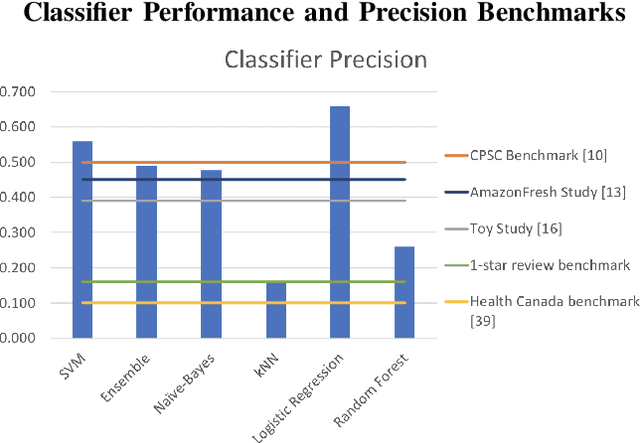
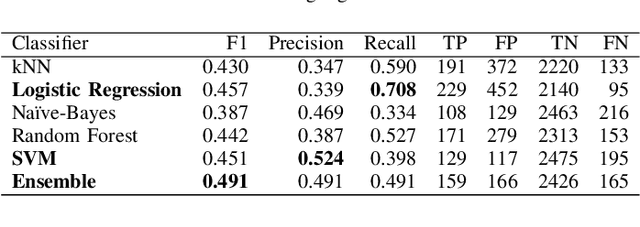
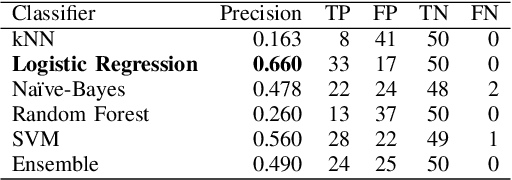
Every year, thousands of people receive consumer product related injuries. Research indicates that online customer reviews can be processed to autonomously identify product safety issues. Early identification of safety issues can lead to earlier recalls, and thus fewer injuries and deaths. A dataset of product reviews from Amazon.com was compiled, along with \emph{SaferProducts.gov} complaints and recall descriptions from the Consumer Product Safety Commission (CPSC) and European Commission Rapid Alert system. A system was built to clean the collected text and to extract relevant features. Dimensionality reduction was performed by computing feature relevance through a Random Forest and discarding features with low information gain. Various classifiers were analyzed, including Logistic Regression, SVMs, Na{\"i}ve-Bayes, Random Forests, and an Ensemble classifier. Experimentation with various features and classifier combinations resulted in a logistic regression model with 66\% precision in the top 50 reviews surfaced. This classifier outperforms all benchmarks set by related literature and consumer product safety professionals.