 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimulation-free Schrödinger bridges via score and flow matching
Jul 07, 2023We present simulation-free score and flow matching ([SF]$^2$M), a simulation-free objective for inferring stochastic dynamics given unpaired source and target samples drawn from arbitrary distributions. Our method generalizes both the score-matching loss used in the training of diffusion models and the recently proposed flow matching loss used in the training of continuous normalizing flows. [SF]$^2$M interprets continuous-time stochastic generative modeling as a Schr\"odinger bridge (SB) problem. It relies on static entropy-regularized optimal transport, or a minibatch approximation, to efficiently learn the SB without simulating the learned stochastic process. We find that [SF]$^2$M is more efficient and gives more accurate solutions to the SB problem than simulation-based methods from prior work. Finally, we apply [SF]$^2$M to the problem of learning cell dynamics from snapshot data. Notably, [SF]$^2$M is the first method to accurately model cell dynamics in high dimensions and can recover known gene regulatory networks from simulated data.
Inferring dynamic regulatory interaction graphs from time series data with perturbations
Jun 13, 2023



Complex systems are characterized by intricate interactions between entities that evolve dynamically over time. Accurate inference of these dynamic relationships is crucial for understanding and predicting system behavior. In this paper, we propose Regulatory Temporal Interaction Network Inference (RiTINI) for inferring time-varying interaction graphs in complex systems using a novel combination of space-and-time graph attentions and graph neural ordinary differential equations (ODEs). RiTINI leverages time-lapse signals on a graph prior, as well as perturbations of signals at various nodes in order to effectively capture the dynamics of the underlying system. This approach is distinct from traditional causal inference networks, which are limited to inferring acyclic and static graphs. In contrast, RiTINI can infer cyclic, directed, and time-varying graphs, providing a more comprehensive and accurate representation of complex systems. The graph attention mechanism in RiTINI allows the model to adaptively focus on the most relevant interactions in time and space, while the graph neural ODEs enable continuous-time modeling of the system's dynamics. We evaluate RiTINI's performance on various simulated and real-world datasets, demonstrating its state-of-the-art capability in inferring interaction graphs compared to previous methods.
Neural FIM for learning Fisher Information Metrics from point cloud data
Jun 12, 2023Although data diffusion embeddings are ubiquitous in unsupervised learning and have proven to be a viable technique for uncovering the underlying intrinsic geometry of data, diffusion embeddings are inherently limited due to their discrete nature. To this end, we propose neural FIM, a method for computing the Fisher information metric (FIM) from point cloud data - allowing for a continuous manifold model for the data. Neural FIM creates an extensible metric space from discrete point cloud data such that information from the metric can inform us of manifold characteristics such as volume and geodesics. We demonstrate Neural FIM's utility in selecting parameters for the PHATE visualization method as well as its ability to obtain information pertaining to local volume illuminating branching points and cluster centers embeddings of a toy dataset and two single-cell datasets of IPSC reprogramming and PBMCs (immune cells).
Graph Fourier MMD for Signals on Graphs
Jun 05, 2023



While numerous methods have been proposed for computing distances between probability distributions in Euclidean space, relatively little attention has been given to computing such distances for distributions on graphs. However, there has been a marked increase in data that either lies on graph (such as protein interaction networks) or can be modeled as a graph (single cell data), particularly in the biomedical sciences. Thus, it becomes important to find ways to compare signals defined on such graphs. Here, we propose Graph Fourier MMD (GFMMD), a novel distance between distributions and signals on graphs. GFMMD is defined via an optimal witness function that is both smooth on the graph and maximizes difference in expectation between the pair of distributions on the graph. We find an analytical solution to this optimization problem as well as an embedding of distributions that results from this method. We also prove several properties of this method including scale invariance and applicability to disconnected graphs. We showcase it on graph benchmark datasets as well on single cell RNA-sequencing data analysis. In the latter, we use the GFMMD-based gene embeddings to find meaningful gene clusters. We also propose a novel type of score for gene selection called "gene localization score" which helps select genes for cellular state space characterization.
A Heat Diffusion Perspective on Geodesic Preserving Dimensionality Reduction
May 30, 2023Diffusion-based manifold learning methods have proven useful in representation learning and dimensionality reduction of modern high dimensional, high throughput, noisy datasets. Such datasets are especially present in fields like biology and physics. While it is thought that these methods preserve underlying manifold structure of data by learning a proxy for geodesic distances, no specific theoretical links have been established. Here, we establish such a link via results in Riemannian geometry explicitly connecting heat diffusion to manifold distances. In this process, we also formulate a more general heat kernel based manifold embedding method that we call heat geodesic embeddings. This novel perspective makes clearer the choices available in manifold learning and denoising. Results show that our method outperforms existing state of the art in preserving ground truth manifold distances, and preserving cluster structure in toy datasets. We also showcase our method on single cell RNA-sequencing datasets with both continuum and cluster structure, where our method enables interpolation of withheld timepoints of data. Finally, we show that parameters of our more general method can be configured to give results similar to PHATE (a state-of-the-art diffusion based manifold learning method) as well as SNE (an attraction/repulsion neighborhood based method that forms the basis of t-SNE).
Conditional Flow Matching: Simulation-Free Dynamic Optimal Transport
Feb 01, 2023



Continuous normalizing flows (CNFs) are an attractive generative modeling technique, but they have thus far been held back by limitations in their simulation-based maximum likelihood training. In this paper, we introduce a new technique called conditional flow matching (CFM), a simulation-free training objective for CNFs. CFM features a stable regression objective like that used to train the stochastic flow in diffusion models but enjoys the efficient inference of deterministic flow models. In contrast to both diffusion models and prior CNF training algorithms, our CFM objective does not require the source distribution to be Gaussian or require evaluation of its density. Based on this new objective, we also introduce optimal transport CFM (OT-CFM), which creates simpler flows that are more stable to train and lead to faster inference, as evaluated in our experiments. Training CNFs with CFM improves results on a variety of conditional and unconditional generation tasks such as inferring single cell dynamics, unsupervised image translation, and Schr\"odinger bridge inference. Code is available at https://github.com/atong01/conditional-flow-matching .
Reliability of CKA as a Similarity Measure in Deep Learning
Nov 16, 2022



Comparing learned neural representations in neural networks is a challenging but important problem, which has been approached in different ways. The Centered Kernel Alignment (CKA) similarity metric, particularly its linear variant, has recently become a popular approach and has been widely used to compare representations of a network's different layers, of architecturally similar networks trained differently, or of models with different architectures trained on the same data. A wide variety of conclusions about similarity and dissimilarity of these various representations have been made using CKA. In this work we present analysis that formally characterizes CKA sensitivity to a large class of simple transformations, which can naturally occur in the context of modern machine learning. This provides a concrete explanation of CKA sensitivity to outliers, which has been observed in past works, and to transformations that preserve the linear separability of the data, an important generalization attribute. We empirically investigate several weaknesses of the CKA similarity metric, demonstrating situations in which it gives unexpected or counter-intuitive results. Finally we study approaches for modifying representations to maintain functional behaviour while changing the CKA value. Our results illustrate that, in many cases, the CKA value can be easily manipulated without substantial changes to the functional behaviour of the models, and call for caution when leveraging activation alignment metrics.
Geodesic Sinkhorn: optimal transport for high-dimensional datasets
Nov 02, 2022Understanding the dynamics and reactions of cells from population snapshots is a major challenge in single-cell transcriptomics. Here, we present Geodesic Sinkhorn, a method for interpolating populations along a data manifold that leverages existing kernels developed for single-cell dimensionality reduction and visualization methods. Our Geodesic Sinkhorn method uses a heat-geodesic ground distance that, as compared to Euclidean ground distances, is more accurate for interpolating single-cell dynamics on a wide variety of datasets and significantly speeds up the computation for sparse kernels. We first apply Geodesic Sinkhorn to 10 single-cell transcriptomics time series interpolation datasets as a drop-in replacement for existing interpolation methods where it outperforms on all datasets, showing its effectiveness in modeling cell dynamics. Second, we show how to efficiently approximate the operator with polynomial kernels allowing us to improve scaling to large datasets. Finally, we define the conditional Wasserstein-average treatment effect and show how it can elucidate the treatment effect on single-cell populations on a drug screen.
Manifold Alignment with Label Information
Oct 31, 2022Multi-domain data is becoming increasingly common and presents both challenges and opportunities in the data science community. The integration of distinct data-views can be used for exploratory data analysis, and benefit downstream analysis including machine learning related tasks. With this in mind, we present a novel manifold alignment method called MALI (Manifold alignment with label information) that learns a correspondence between two distinct domains. MALI can be considered as belonging to a middle ground between the more commonly addressed semi-supervised manifold alignment problem with some known correspondences between the two domains, and the purely unsupervised case, where no known correspondences are provided. To do this, MALI learns the manifold structure in both domains via a diffusion process and then leverages discrete class labels to guide the alignment. By aligning two distinct domains, MALI recovers a pairing and a common representation that reveals related samples in both domains. Additionally, MALI can be used for the transfer learning problem known as domain adaptation. We show that MALI outperforms the current state-of-the-art manifold alignment methods across multiple datasets.
Learnable Filters for Geometric Scattering Modules
Aug 15, 2022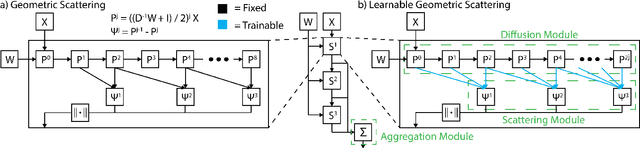
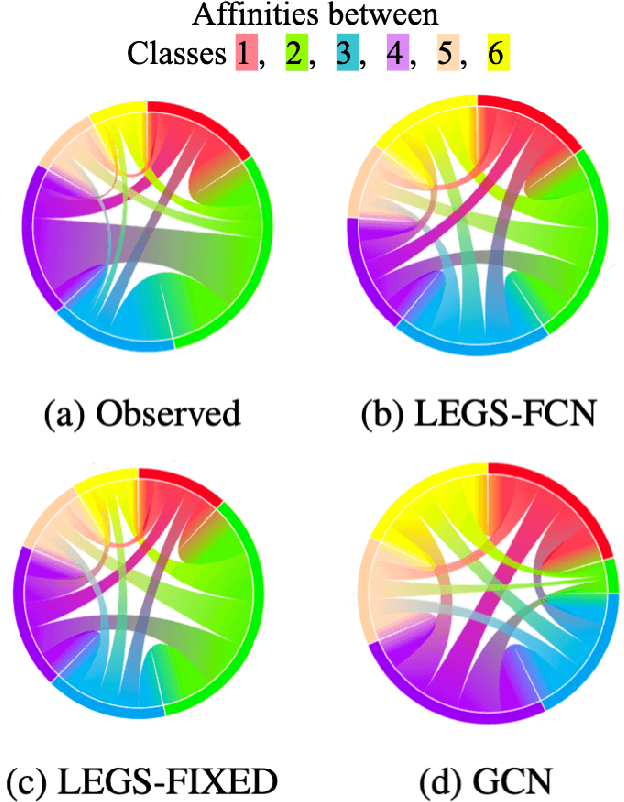
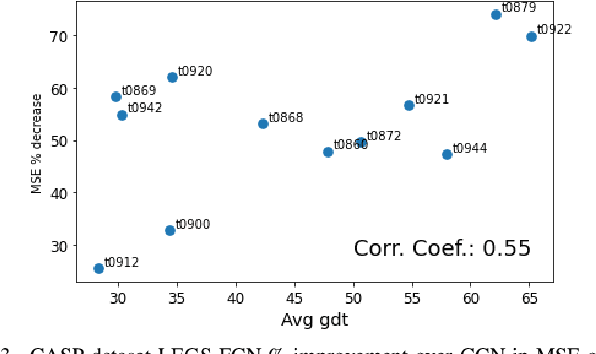
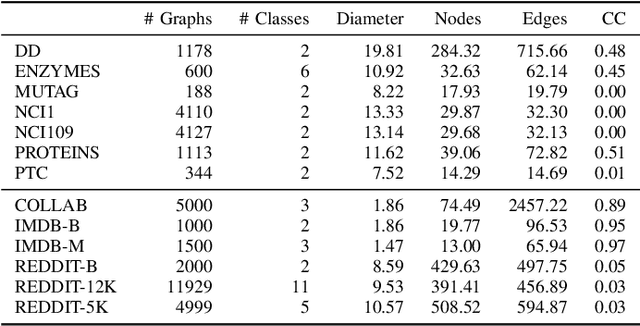
We propose a new graph neural network (GNN) module, based on relaxations of recently proposed geometric scattering transforms, which consist of a cascade of graph wavelet filters. Our learnable geometric scattering (LEGS) module enables adaptive tuning of the wavelets to encourage band-pass features to emerge in learned representations. The incorporation of our LEGS-module in GNNs enables the learning of longer-range graph relations compared to many popular GNNs, which often rely on encoding graph structure via smoothness or similarity between neighbors. Further, its wavelet priors result in simplified architectures with significantly fewer learned parameters compared to competing GNNs. We demonstrate the predictive performance of LEGS-based networks on graph classification benchmarks, as well as the descriptive quality of their learned features in biochemical graph data exploration tasks. Our results show that LEGS-based networks match or outperforms popular GNNs, as well as the original geometric scattering construction, on many datasets, in particular in biochemical domains, while retaining certain mathematical properties of handcrafted (non-learned) geometric scattering.