 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Multimodal Interactive Agents with Reinforcement Learning from Human Feedback
Nov 21, 2022An important goal in artificial intelligence is to create agents that can both interact naturally with humans and learn from their feedback. Here we demonstrate how to use reinforcement learning from human feedback (RLHF) to improve upon simulated, embodied agents trained to a base level of competency with imitation learning. First, we collected data of humans interacting with agents in a simulated 3D world. We then asked annotators to record moments where they believed that agents either progressed toward or regressed from their human-instructed goal. Using this annotation data we leveraged a novel method - which we call "Inter-temporal Bradley-Terry" (IBT) modelling - to build a reward model that captures human judgments. Agents trained to optimise rewards delivered from IBT reward models improved with respect to all of our metrics, including subsequent human judgment during live interactions with agents. Altogether our results demonstrate how one can successfully leverage human judgments to improve agent behaviour, allowing us to use reinforcement learning in complex, embodied domains without programmatic reward functions. Videos of agent behaviour may be found at https://youtu.be/v_Z9F2_eKk4.
Creating Multimodal Interactive Agents with Imitation and Self-Supervised Learning
Dec 07, 2021
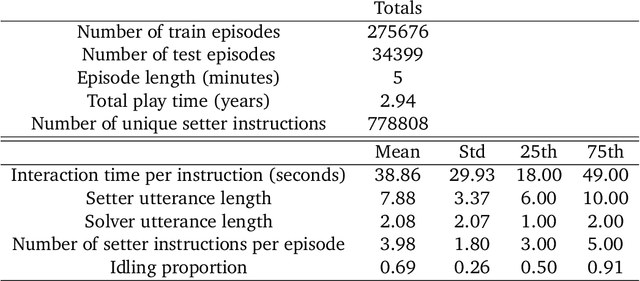
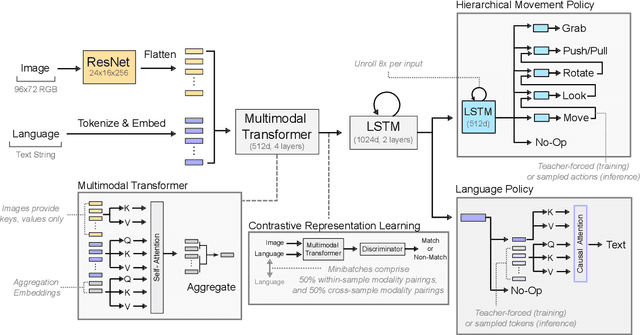
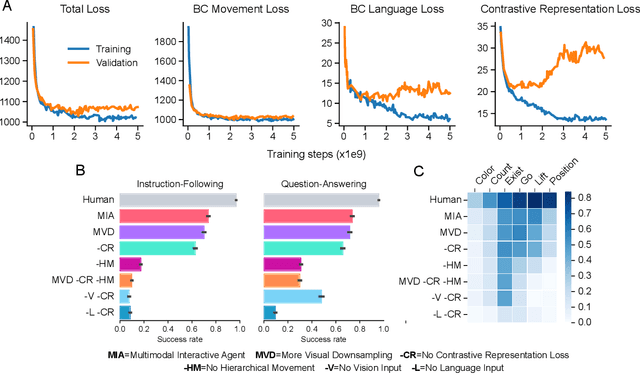
A common vision from science fiction is that robots will one day inhabit our physical spaces, sense the world as we do, assist our physical labours, and communicate with us through natural language. Here we study how to design artificial agents that can interact naturally with humans using the simplification of a virtual environment. We show that imitation learning of human-human interactions in a simulated world, in conjunction with self-supervised learning, is sufficient to produce a multimodal interactive agent, which we call MIA, that successfully interacts with non-adversarial humans 75% of the time. We further identify architectural and algorithmic techniques that improve performance, such as hierarchical action selection. Altogether, our results demonstrate that imitation of multi-modal, real-time human behaviour may provide a straightforward and surprisingly effective means of imbuing agents with a rich behavioural prior from which agents might then be fine-tuned for specific purposes, thus laying a foundation for training capable agents for interactive robots or digital assistants. A video of MIA's behaviour may be found at https://youtu.be/ZFgRhviF7mY