 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegret Bounds and Regimes of Optimality for User-User and Item-Item Collaborative Filtering
Nov 06, 2017
We consider an online model for recommendation systems, with each user being recommended an item at each time-step and providing 'like' or 'dislike' feedback. A latent variable model specifies the user preferences: both users and items are clustered into types. All users of a given type have identical preferences for the items, and similarly, items of a given type are either all liked or all disliked by a given user. The model captures structure in both the item and user spaces, and in this paper, we assume that the type preference matrix is randomly generated. We describe two algorithms inspired by user-user and item-item collaborative filtering (CF), modified to explicitly make exploratory recommendations, and prove performance guarantees in terms of their expected regret. For two regimes of model parameters, with structure only in item space or only in user space, we prove information-theoretic lower bounds on regret that match our upper bounds up to logarithmic factors. Our analysis elucidates system operating regimes in which existing CF algorithms are nearly optimal.
Regret Guarantees for Item-Item Collaborative Filtering
Jan 08, 2016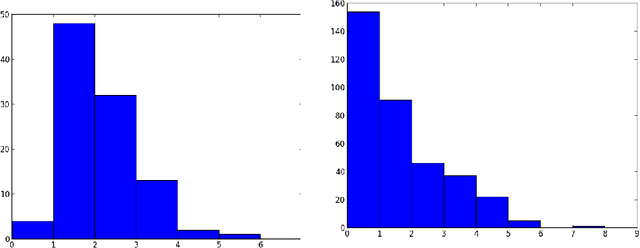
There is much empirical evidence that item-item collaborative filtering works well in practice. Motivated to understand this, we provide a framework to design and analyze various recommendation algorithms. The setup amounts to online binary matrix completion, where at each time a random user requests a recommendation and the algorithm chooses an entry to reveal in the user's row. The goal is to minimize regret, or equivalently to maximize the number of +1 entries revealed at any time. We analyze an item-item collaborative filtering algorithm that can achieve fundamentally better performance compared to user-user collaborative filtering. The algorithm achieves good "cold-start" performance (appropriately defined) by quickly making good recommendations to new users about whom there is little information.
Structure learning of antiferromagnetic Ising models
Dec 03, 2014In this paper we investigate the computational complexity of learning the graph structure underlying a discrete undirected graphical model from i.i.d. samples. We first observe that the notoriously difficult problem of learning parities with noise can be captured as a special case of learning graphical models. This leads to an unconditional computational lower bound of $\Omega (p^{d/2})$ for learning general graphical models on $p$ nodes of maximum degree $d$, for the class of so-called statistical algorithms recently introduced by Feldman et al (2013). The lower bound suggests that the $O(p^d)$ runtime required to exhaustively search over neighborhoods cannot be significantly improved without restricting the class of models. Aside from structural assumptions on the graph such as it being a tree, hypertree, tree-like, etc., many recent papers on structure learning assume that the model has the correlation decay property. Indeed, focusing on ferromagnetic Ising models, Bento and Montanari (2009) showed that all known low-complexity algorithms fail to learn simple graphs when the interaction strength exceeds a number related to the correlation decay threshold. Our second set of results gives a class of repelling (antiferromagnetic) models that have the opposite behavior: very strong interaction allows efficient learning in time $O(p^2)$. We provide an algorithm whose performance interpolates between $O(p^2)$ and $O(p^{d+2})$ depending on the strength of the repulsion.
Efficiently learning Ising models on arbitrary graphs
Dec 01, 2014We consider the problem of reconstructing the graph underlying an Ising model from i.i.d. samples. Over the last fifteen years this problem has been of significant interest in the statistics, machine learning, and statistical physics communities, and much of the effort has been directed towards finding algorithms with low computational cost for various restricted classes of models. Nevertheless, for learning Ising models on general graphs with $p$ nodes of degree at most $d$, it is not known whether or not it is possible to improve upon the $p^{d}$ computation needed to exhaustively search over all possible neighborhoods for each node. In this paper we show that a simple greedy procedure allows to learn the structure of an Ising model on an arbitrary bounded-degree graph in time on the order of $p^2$. We make no assumptions on the parameters except what is necessary for identifiability of the model, and in particular the results hold at low-temperatures as well as for highly non-uniform models. The proof rests on a new structural property of Ising models: we show that for any node there exists at least one neighbor with which it has a high mutual information. This structural property may be of independent interest.
Learning graphical models from the Glauber dynamics
Nov 29, 2014In this paper we consider the problem of learning undirected graphical models from data generated according to the Glauber dynamics. The Glauber dynamics is a Markov chain that sequentially updates individual nodes (variables) in a graphical model and it is frequently used to sample from the stationary distribution (to which it converges given sufficient time). Additionally, the Glauber dynamics is a natural dynamical model in a variety of settings. This work deviates from the standard formulation of graphical model learning in the literature, where one assumes access to i.i.d. samples from the distribution. Much of the research on graphical model learning has been directed towards finding algorithms with low computational cost. As the main result of this work, we establish that the problem of reconstructing binary pairwise graphical models is computationally tractable when we observe the Glauber dynamics. Specifically, we show that a binary pairwise graphical model on $p$ nodes with maximum degree $d$ can be learned in time $f(d)p^2\log p$, for a function $f(d)$, using nearly the information-theoretic minimum number of samples.
A Latent Source Model for Online Collaborative Filtering
Oct 31, 2014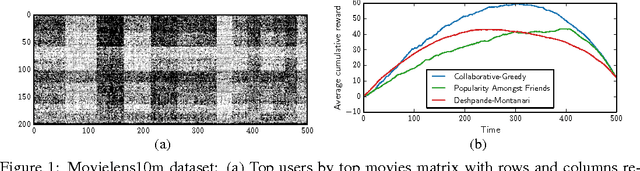
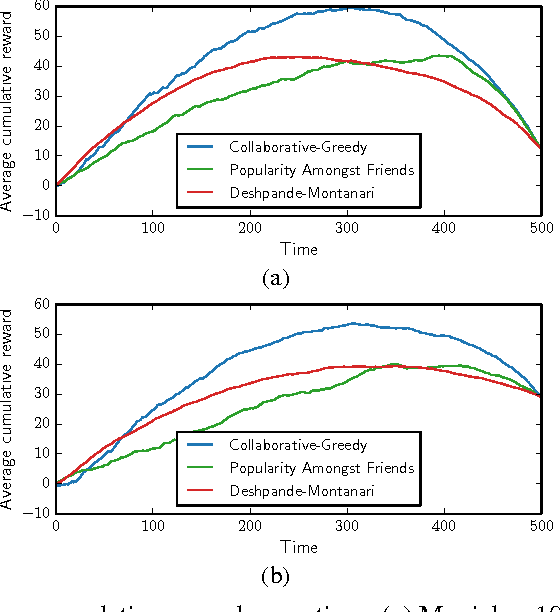
Despite the prevalence of collaborative filtering in recommendation systems, there has been little theoretical development on why and how well it works, especially in the "online" setting, where items are recommended to users over time. We address this theoretical gap by introducing a model for online recommendation systems, cast item recommendation under the model as a learning problem, and analyze the performance of a cosine-similarity collaborative filtering method. In our model, each of $n$ users either likes or dislikes each of $m$ items. We assume there to be $k$ types of users, and all the users of a given type share a common string of probabilities determining the chance of liking each item. At each time step, we recommend an item to each user, where a key distinction from related bandit literature is that once a user consumes an item (e.g., watches a movie), then that item cannot be recommended to the same user again. The goal is to maximize the number of likable items recommended to users over time. Our main result establishes that after nearly $\log(km)$ initial learning time steps, a simple collaborative filtering algorithm achieves essentially optimal performance without knowing $k$. The algorithm has an exploitation step that uses cosine similarity and two types of exploration steps, one to explore the space of items (standard in the literature) and the other to explore similarity between users (novel to this work).
Hardness of parameter estimation in graphical models
Sep 17, 2014We consider the problem of learning the canonical parameters specifying an undirected graphical model (Markov random field) from the mean parameters. For graphical models representing a minimal exponential family, the canonical parameters are uniquely determined by the mean parameters, so the problem is feasible in principle. The goal of this paper is to investigate the computational feasibility of this statistical task. Our main result shows that parameter estimation is in general intractable: no algorithm can learn the canonical parameters of a generic pair-wise binary graphical model from the mean parameters in time bounded by a polynomial in the number of variables (unless RP = NP). Indeed, such a result has been believed to be true (see the monograph by Wainwright and Jordan (2008)) but no proof was known. Our proof gives a polynomial time reduction from approximating the partition function of the hard-core model, known to be hard, to learning approximate parameters. Our reduction entails showing that the marginal polytope boundary has an inherent repulsive property, which validates an optimization procedure over the polytope that does not use any knowledge of its structure (as required by the ellipsoid method and others).
Reconstruction of Markov Random Fields from Samples: Some Easy Observations and Algorithms
Mar 08, 2010Markov random fields are used to model high dimensional distributions in a number of applied areas. Much recent interest has been devoted to the reconstruction of the dependency structure from independent samples from the Markov random fields. We analyze a simple algorithm for reconstructing the underlying graph defining a Markov random field on $n$ nodes and maximum degree $d$ given observations. We show that under mild non-degeneracy conditions it reconstructs the generating graph with high probability using $\Theta(d \epsilon^{-2}\delta^{-4} \log n)$ samples where $\epsilon,\delta$ depend on the local interactions. For most local interaction $\eps,\delta$ are of order $\exp(-O(d))$. Our results are optimal as a function of $n$ up to a multiplicative constant depending on $d$ and the strength of the local interactions. Our results seem to be the first results for general models that guarantee that {\em the} generating model is reconstructed. Furthermore, we provide explicit $O(n^{d+2} \epsilon^{-2}\delta^{-4} \log n)$ running time bound. In cases where the measure on the graph has correlation decay, the running time is $O(n^2 \log n)$ for all fixed $d$. We also discuss the effect of observing noisy samples and show that as long as the noise level is low, our algorithm is effective. On the other hand, we construct an example where large noise implies non-identifiability even for generic noise and interactions. Finally, we briefly show that in some simple cases, models with hidden nodes can also be recovered.