 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Relative Depth Learning for Urban Scene Understanding
Apr 02, 2018
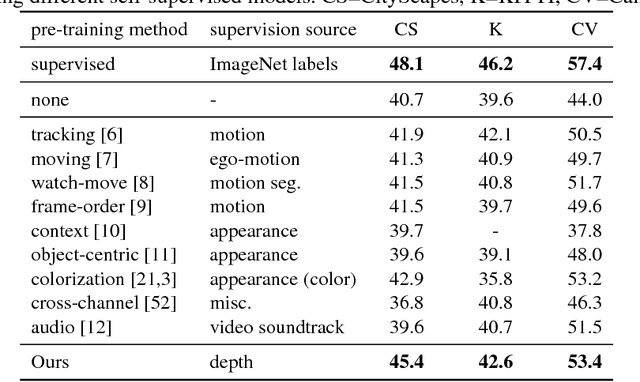

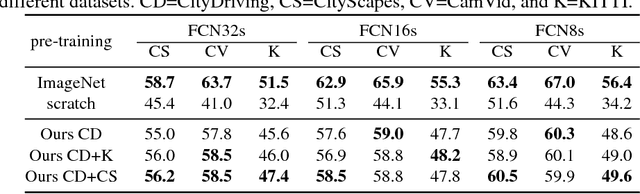
As an agent moves through the world, the apparent motion of scene elements is (usually) inversely proportional to their depth. It is natural for a learning agent to associate image patterns with the magnitude of their displacement over time: as the agent moves, faraway mountains don't move much; nearby trees move a lot. This natural relationship between the appearance of objects and their motion is a rich source of information about the world. In this work, we start by training a deep network, using fully automatic supervision, to predict relative scene depth from single images. The relative depth training images are automatically derived from simple videos of cars moving through a scene, using recent motion segmentation techniques, and no human-provided labels. This proxy task of predicting relative depth from a single image induces features in the network that result in large improvements in a set of downstream tasks including semantic segmentation, joint road segmentation and car detection, and monocular (absolute) depth estimation, over a network trained from scratch. The improvement on the semantic segmentation task is greater than those produced by any other automatically supervised methods. Moreover, for monocular depth estimation, our unsupervised pre-training method even outperforms supervised pre-training with ImageNet. In addition, we demonstrate benefits from learning to predict (unsupervised) relative depth in the specific videos associated with various downstream tasks. We adapt to the specific scenes in those tasks in an unsupervised manner to improve performance. In summary, for semantic segmentation, we present state-of-the-art results among methods that do not use supervised pre-training, and we even exceed the performance of supervised ImageNet pre-trained models for monocular depth estimation, achieving results that are comparable with state-of-the-art methods.
Discovery of Visual Semantics by Unsupervised and Self-Supervised Representation Learning
Aug 19, 2017
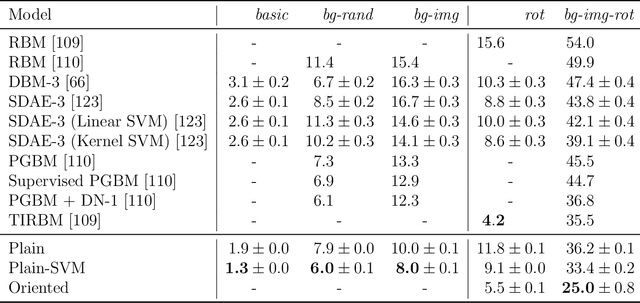

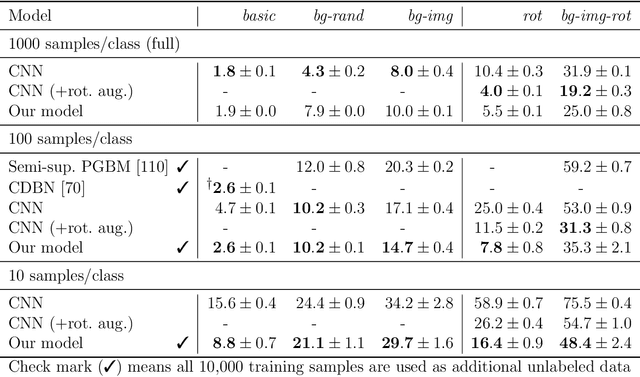
The success of deep learning in computer vision is rooted in the ability of deep networks to scale up model complexity as demanded by challenging visual tasks. As complexity is increased, so is the need for large amounts of labeled data to train the model. This is associated with a costly human annotation effort. To address this concern, with the long-term goal of leveraging the abundance of cheap unlabeled data, we explore methods of unsupervised "pre-training." In particular, we propose to use self-supervised automatic image colorization. We show that traditional methods for unsupervised learning, such as layer-wise clustering or autoencoders, remain inferior to supervised pre-training. In search for an alternative, we develop a fully automatic image colorization method. Our method sets a new state-of-the-art in revitalizing old black-and-white photography, without requiring human effort or expertise. Additionally, it gives us a method for self-supervised representation learning. In order for the model to appropriately re-color a grayscale object, it must first be able to identify it. This ability, learned entirely self-supervised, can be used to improve other visual tasks, such as classification and semantic segmentation. As a future direction for self-supervision, we investigate if multiple proxy tasks can be combined to improve generalization. This turns out to be a challenging open problem. We hope that our contributions to this endeavor will provide a foundation for future efforts in making self-supervision compete with supervised pre-training.
Learning Representations for Automatic Colorization
Aug 13, 2017
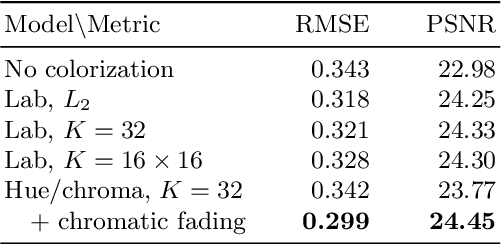
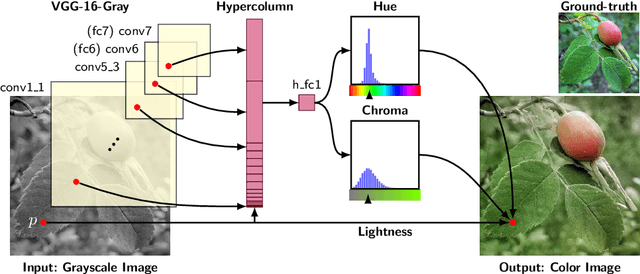
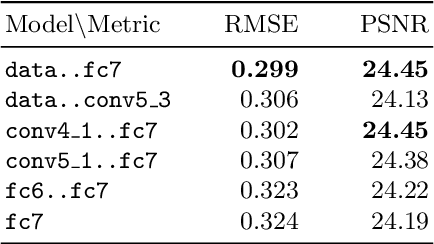
We develop a fully automatic image colorization system. Our approach leverages recent advances in deep networks, exploiting both low-level and semantic representations. As many scene elements naturally appear according to multimodal color distributions, we train our model to predict per-pixel color histograms. This intermediate output can be used to automatically generate a color image, or further manipulated prior to image formation. On both fully and partially automatic colorization tasks, we outperform existing methods. We also explore colorization as a vehicle for self-supervised visual representation learning.
Colorization as a Proxy Task for Visual Understanding
Aug 13, 2017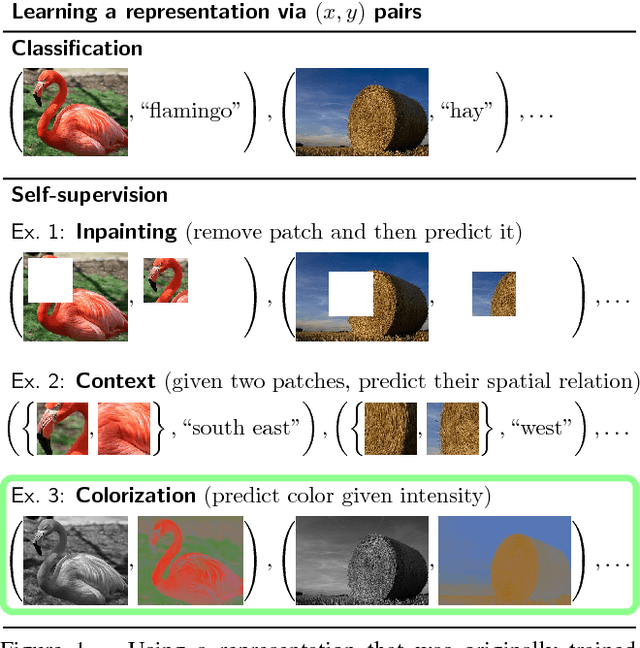
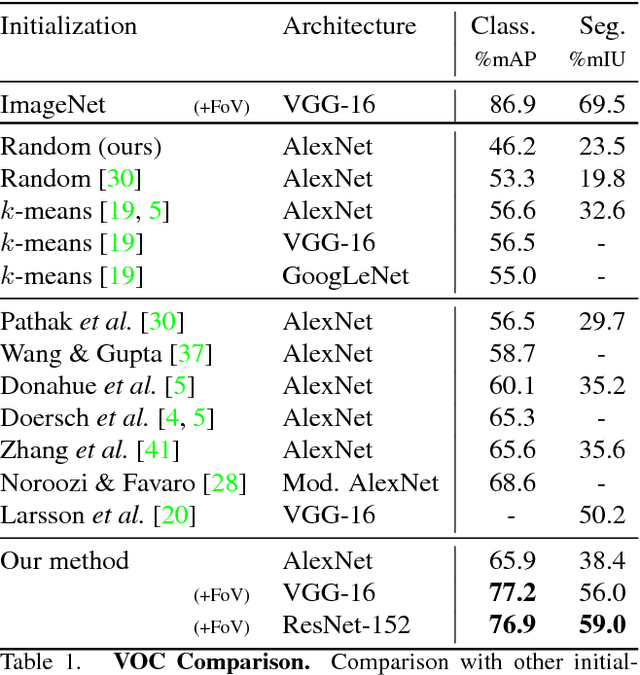


We investigate and improve self-supervision as a drop-in replacement for ImageNet pretraining, focusing on automatic colorization as the proxy task. Self-supervised training has been shown to be more promising for utilizing unlabeled data than other, traditional unsupervised learning methods. We build on this success and evaluate the ability of our self-supervised network in several contexts. On VOC segmentation and classification tasks, we present results that are state-of-the-art among methods not using ImageNet labels for pretraining representations. Moreover, we present the first in-depth analysis of self-supervision via colorization, concluding that formulation of the loss, training details and network architecture play important roles in its effectiveness. This investigation is further expanded by revisiting the ImageNet pretraining paradigm, asking questions such as: How much training data is needed? How many labels are needed? How much do features change when fine-tuned? We relate these questions back to self-supervision by showing that colorization provides a similarly powerful supervisory signal as various flavors of ImageNet pretraining.
FractalNet: Ultra-Deep Neural Networks without Residuals
May 26, 2017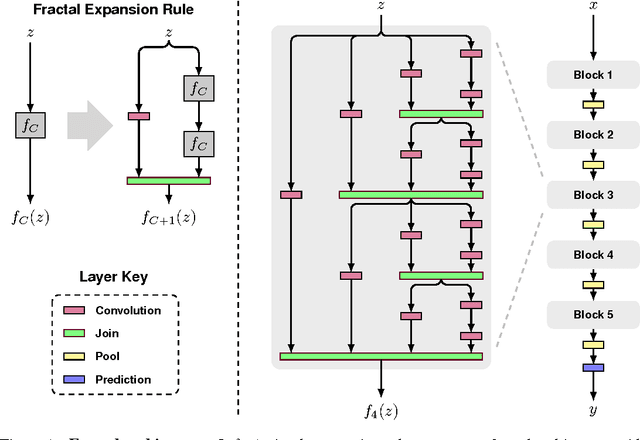
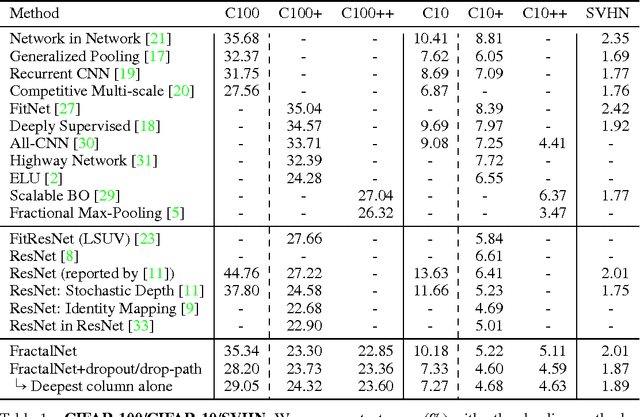
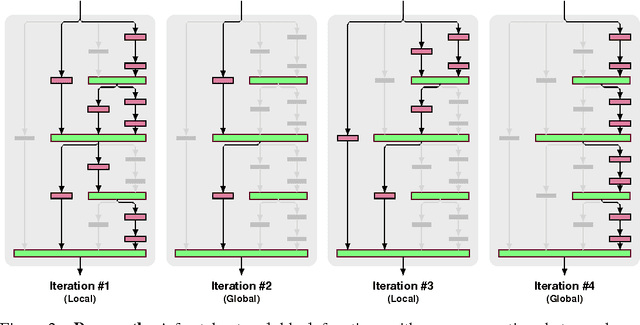
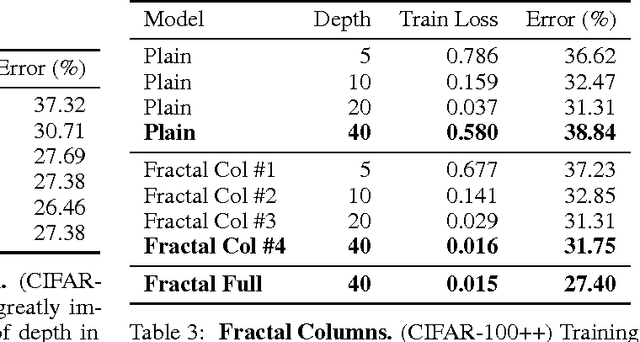
We introduce a design strategy for neural network macro-architecture based on self-similarity. Repeated application of a simple expansion rule generates deep networks whose structural layouts are precisely truncated fractals. These networks contain interacting subpaths of different lengths, but do not include any pass-through or residual connections; every internal signal is transformed by a filter and nonlinearity before being seen by subsequent layers. In experiments, fractal networks match the excellent performance of standard residual networks on both CIFAR and ImageNet classification tasks, thereby demonstrating that residual representations may not be fundamental to the success of extremely deep convolutional neural networks. Rather, the key may be the ability to transition, during training, from effectively shallow to deep. We note similarities with student-teacher behavior and develop drop-path, a natural extension of dropout, to regularize co-adaptation of subpaths in fractal architectures. Such regularization allows extraction of high-performance fixed-depth subnetworks. Additionally, fractal networks exhibit an anytime property: shallow subnetworks provide a quick answer, while deeper subnetworks, with higher latency, provide a more accurate answer.