 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimeSeriesGym: A Scalable Benchmark for (Time Series) Machine Learning Engineering Agents
May 19, 2025We introduce TimeSeriesGym, a scalable benchmarking framework for evaluating Artificial Intelligence (AI) agents on time series machine learning engineering challenges. Existing benchmarks lack scalability, focus narrowly on model building in well-defined settings, and evaluate only a limited set of research artifacts (e.g., CSV submission files). To make AI agent benchmarking more relevant to the practice of machine learning engineering, our framework scales along two critical dimensions. First, recognizing that effective ML engineering requires a range of diverse skills, TimeSeriesGym incorporates challenges from diverse sources spanning multiple domains and tasks. We design challenges to evaluate both isolated capabilities (including data handling, understanding research repositories, and code translation) and their combinations, and rather than addressing each challenge independently, we develop tools that support designing multiple challenges at scale. Second, we implement evaluation mechanisms for multiple research artifacts, including submission files, code, and models, using both precise numeric measures and more flexible LLM-based evaluation approaches. This dual strategy balances objective assessment with contextual judgment. Although our initial focus is on time series applications, our framework can be readily extended to other data modalities, broadly enhancing the comprehensiveness and practical utility of agentic AI evaluation. We open-source our benchmarking framework to facilitate future research on the ML engineering capabilities of AI agents.
DMIDAS: Deep Mixed Data Sampling Regression for Long Multi-Horizon Time Series Forecasting
Jun 07, 2021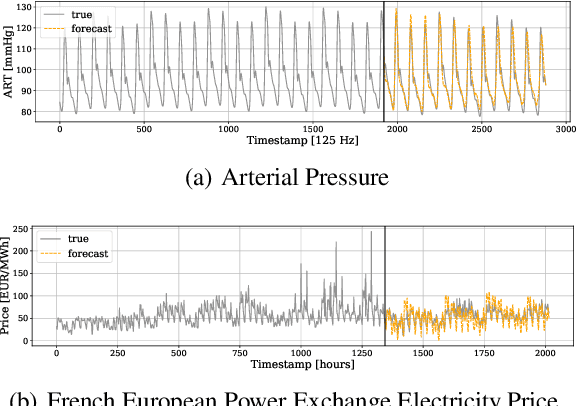
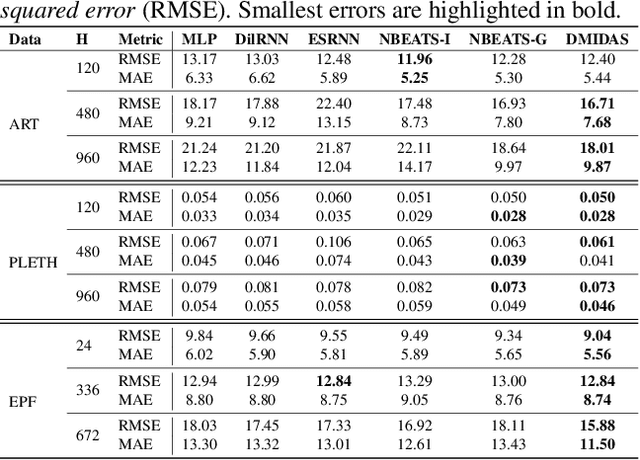
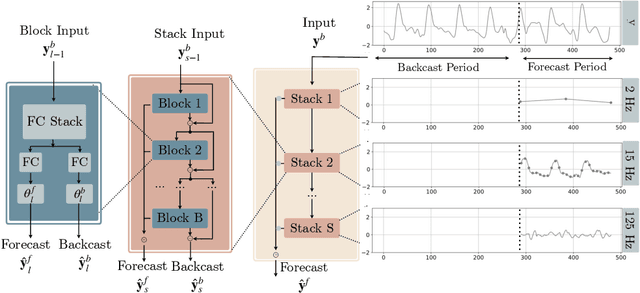
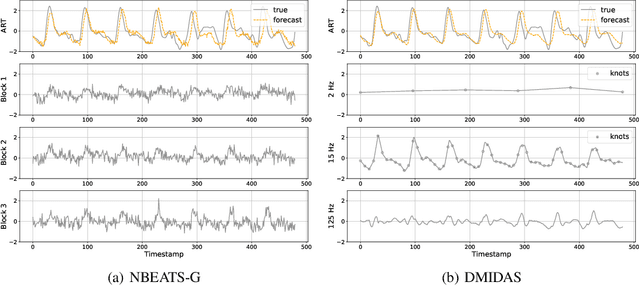
Neural forecasting has shown significant improvements in the accuracy of large-scale systems, yet predicting extremely long horizons remains a challenging task. Two common problems are the volatility of the predictions and their computational complexity; we addressed them by incorporating smoothness regularization and mixed data sampling techniques to a well-performing multi-layer perceptron based architecture (NBEATS). We validate our proposed method, DMIDAS, on high-frequency healthcare and electricity price data with long forecasting horizons (~1000 timestamps) where we improve the prediction accuracy by 5% over state-of-the-art models, reducing the number of parameters of NBEATS by nearly 70%.