 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Generative Stochastic Networks Trainable by Backprop
May 24, 2014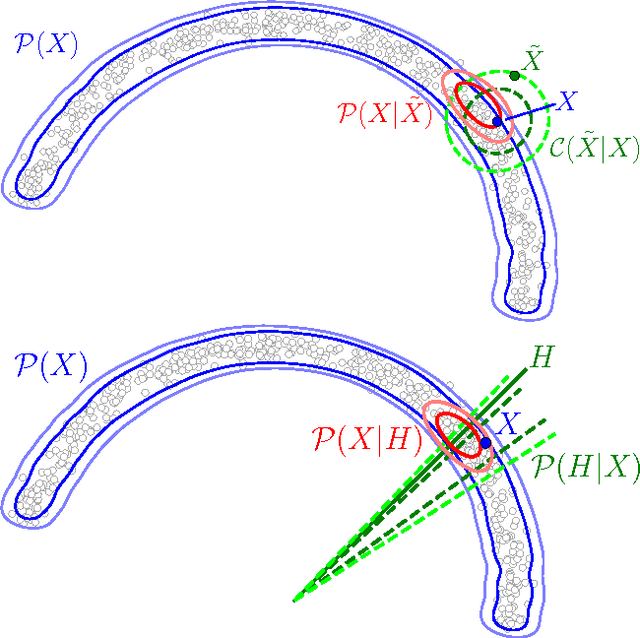

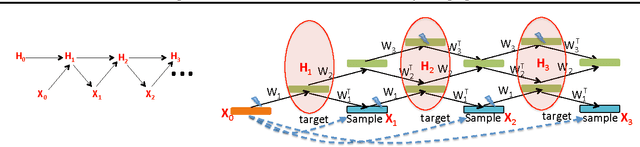

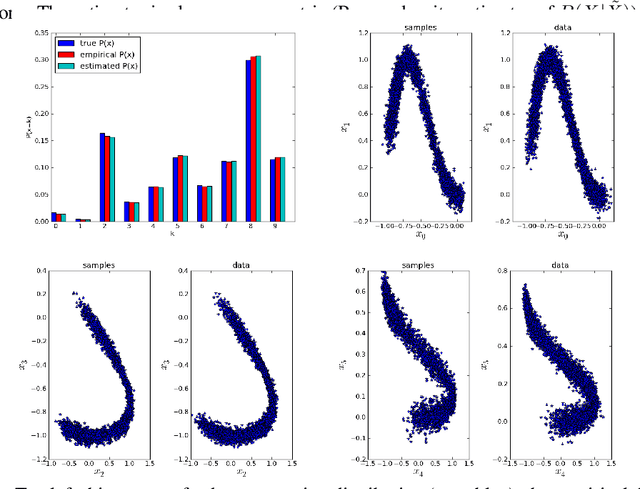
We introduce a novel training principle for probabilistic models that is an alternative to maximum likelihood. The proposed Generative Stochastic Networks (GSN) framework is based on learning the transition operator of a Markov chain whose stationary distribution estimates the data distribution. The transition distribution of the Markov chain is conditional on the previous state, generally involving a small move, so this conditional distribution has fewer dominant modes, being unimodal in the limit of small moves. Thus, it is easier to learn because it is easier to approximate its partition function, more like learning to perform supervised function approximation, with gradients that can be obtained by backprop. We provide theorems that generalize recent work on the probabilistic interpretation of denoising autoencoders and obtain along the way an interesting justification for dependency networks and generalized pseudolikelihood, along with a definition of an appropriate joint distribution and sampling mechanism even when the conditionals are not consistent. GSNs can be used with missing inputs and can be used to sample subsets of variables given the rest. We validate these theoretical results with experiments on two image datasets using an architecture that mimics the Deep Boltzmann Machine Gibbs sampler but allows training to proceed with simple backprop, without the need for layerwise pretraining.
Generalized Denoising Auto-Encoders as Generative Models
Nov 11, 2013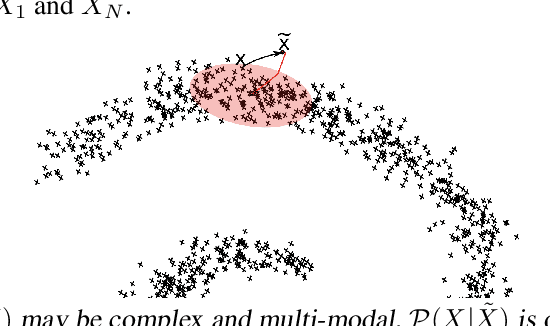
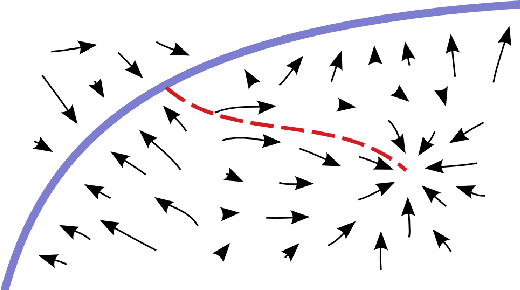

Recent work has shown how denoising and contractive autoencoders implicitly capture the structure of the data-generating density, in the case where the corruption noise is Gaussian, the reconstruction error is the squared error, and the data is continuous-valued. This has led to various proposals for sampling from this implicitly learned density function, using Langevin and Metropolis-Hastings MCMC. However, it remained unclear how to connect the training procedure of regularized auto-encoders to the implicit estimation of the underlying data-generating distribution when the data are discrete, or using other forms of corruption process and reconstruction errors. Another issue is the mathematical justification which is only valid in the limit of small corruption noise. We propose here a different attack on the problem, which deals with all these issues: arbitrary (but noisy enough) corruption, arbitrary reconstruction loss (seen as a log-likelihood), handling both discrete and continuous-valued variables, and removing the bias due to non-infinitesimal corruption noise (or non-infinitesimal contractive penalty).
Implicit Density Estimation by Local Moment Matching to Sample from Auto-Encoders
Jun 30, 2012
Recent work suggests that some auto-encoder variants do a good job of capturing the local manifold structure of the unknown data generating density. This paper contributes to the mathematical understanding of this phenomenon and helps define better justified sampling algorithms for deep learning based on auto-encoder variants. We consider an MCMC where each step samples from a Gaussian whose mean and covariance matrix depend on the previous state, defines through its asymptotic distribution a target density. First, we show that good choices (in the sense of consistency) for these mean and covariance functions are the local expected value and local covariance under that target density. Then we show that an auto-encoder with a contractive penalty captures estimators of these local moments in its reconstruction function and its Jacobian. A contribution of this work is thus a novel alternative to maximum-likelihood density estimation, which we call local moment matching. It also justifies a recently proposed sampling algorithm for the Contractive Auto-Encoder and extends it to the Denoising Auto-Encoder.