 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGalvatron: An Automatic Distributed System for Efficient Foundation Model Training
Apr 30, 2025

Galvatron is a distributed system for efficiently training large-scale Foundation Models. It overcomes the complexities of selecting optimal parallelism strategies by automatically identifying the most efficient hybrid strategy, incorporating data, tensor, pipeline, sharded data, and sequence parallelism, along with recomputation. The system's architecture includes a profiler for hardware and model analysis, a search engine for strategy optimization using decision trees and dynamic programming, and a runtime for executing these strategies efficiently. Benchmarking on various clusters demonstrates Galvatron's superior throughput compared to existing frameworks. This open-source system offers user-friendly interfaces and comprehensive documentation, making complex distributed training accessible and efficient. The source code of Galvatron is available at https://github.com/PKU-DAIR/Hetu-Galvatron.
Average Convergence Rate of Evolutionary Algorithms
Jun 02, 2015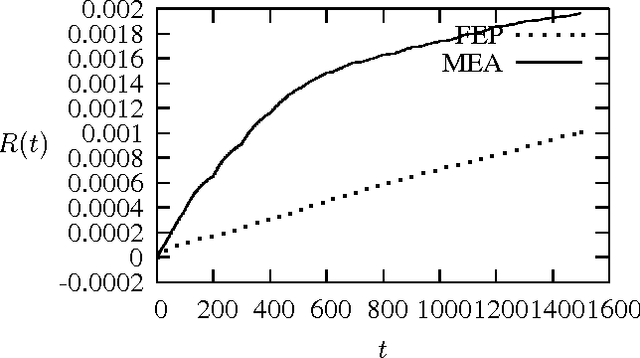
In evolutionary optimization, it is important to understand how fast evolutionary algorithms converge to the optimum per generation, or their convergence rate. This paper proposes a new measure of the convergence rate, called average convergence rate. It is a normalised geometric mean of the reduction ratio of the fitness difference per generation. The calculation of the average convergence rate is very simple and it is applicable for most evolutionary algorithms on both continuous and discrete optimization. A theoretical study of the average convergence rate is conducted for discrete optimization. Lower bounds on the average convergence rate are derived. The limit of the average convergence rate is analysed and then the asymptotic average convergence rate is proposed.