 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Adversarial Robustness by Contrastive Guided Diffusion Process
Oct 18, 2022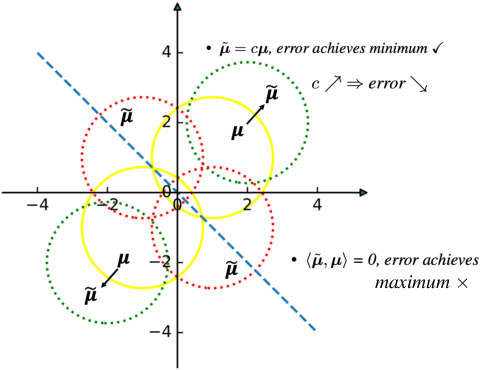
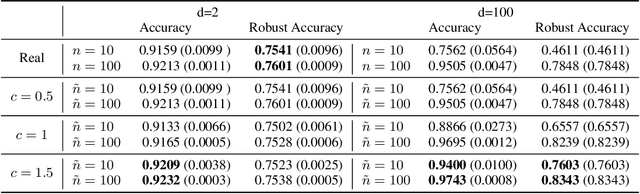
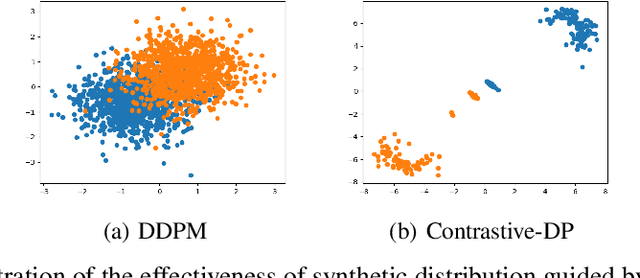
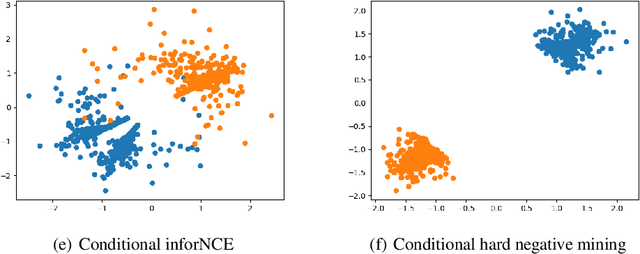
Synthetic data generation has become an emerging tool to help improve the adversarial robustness in classification tasks since robust learning requires a significantly larger amount of training samples compared with standard classification tasks. Among various deep generative models, the diffusion model has been shown to produce high-quality synthetic images and has achieved good performance in improving the adversarial robustness. However, diffusion-type methods are typically slow in data generation as compared with other generative models. Although different acceleration techniques have been proposed recently, it is also of great importance to study how to improve the sample efficiency of generated data for the downstream task. In this paper, we first analyze the optimality condition of synthetic distribution for achieving non-trivial robust accuracy. We show that enhancing the distinguishability among the generated data is critical for improving adversarial robustness. Thus, we propose the Contrastive-Guided Diffusion Process (Contrastive-DP), which adopts the contrastive loss to guide the diffusion model in data generation. We verify our theoretical results using simulations and demonstrate the good performance of Contrastive-DP on image datasets.
Differentially Private Bootstrap: New Privacy Analysis and Inference Strategies
Oct 12, 2022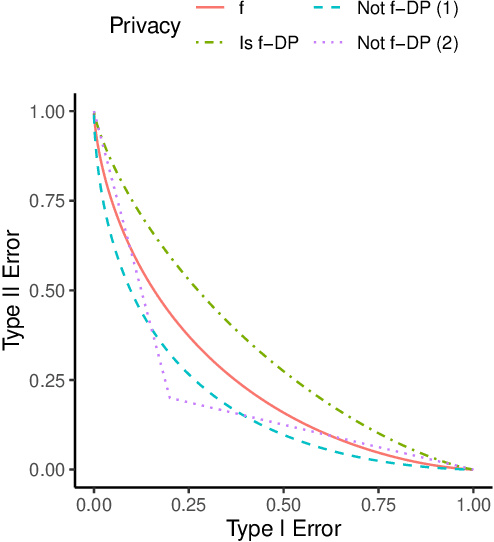

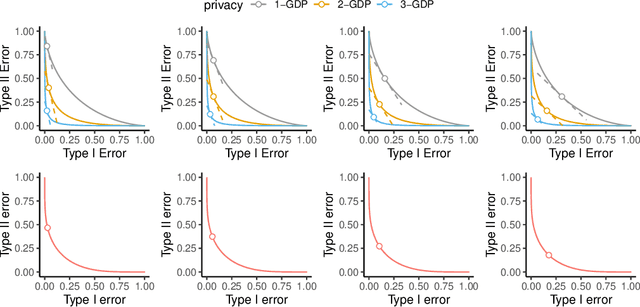
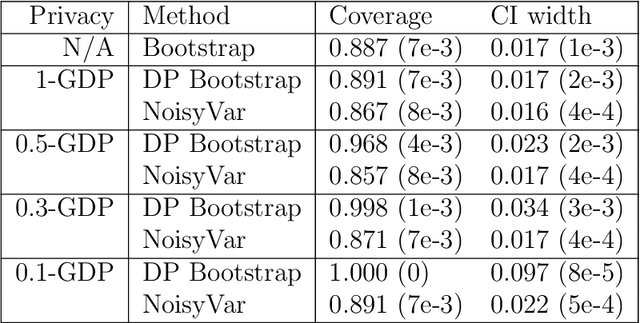
Differential private (DP) mechanisms protect individual-level information by introducing randomness into the statistical analysis procedure. While there are now many DP tools for various statistical problems, there is still a lack of general techniques to understand the sampling distribution of a DP estimator, which is crucial for uncertainty quantification in statistical inference. We analyze a DP bootstrap procedure that releases multiple private bootstrap estimates to infer the sampling distribution and construct confidence intervals. Our privacy analysis includes new results on the privacy cost of a single DP bootstrap estimate applicable to incorporate arbitrary DP mechanisms and identifies some misuses of the bootstrap in the existing literature. We show that the release of $B$ DP bootstrap estimates from mechanisms satisfying $(\mu/\sqrt{(2-2/\mathrm{e})B})$-Gaussian DP asymptotically satisfies $\mu$-Gaussian DP as $B$ goes to infinity. We also develop a statistical procedure based on the DP bootstrap estimates to correctly infer the sampling distribution using techniques related to the deconvolution of probability measures, an approach which is novel in analyzing DP procedures. From our density estimate, we construct confidence intervals and compare them to existing methods through simulations and real-world experiments using the 2016 Canada Census Public Use Microdata. The coverage of our private confidence intervals achieves the nominal confidence level, while other methods fail to meet this guarantee.
Fair Bayes-Optimal Classifiers Under Predictive Parity
May 15, 2022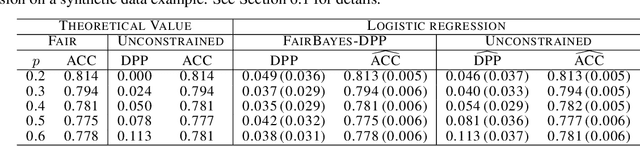
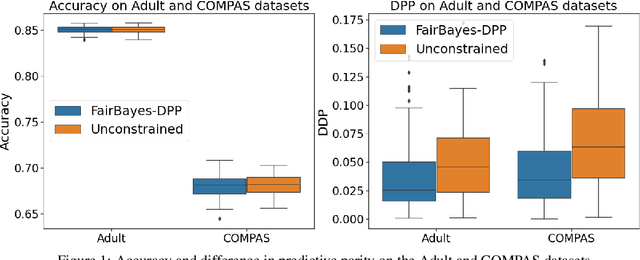
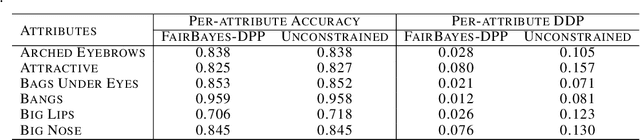
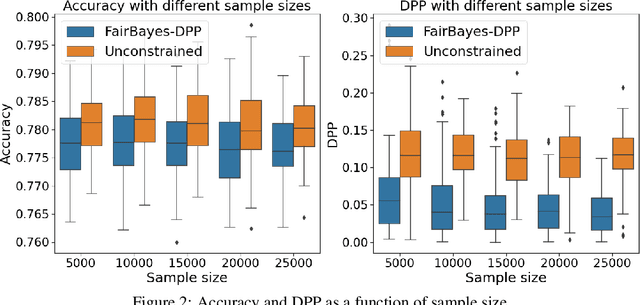
Increasing concerns about disparate effects of AI have motivated a great deal of work on fair machine learning. Existing works mainly focus on independence- and separation-based measures (e.g., demographic parity, equality of opportunity, equalized odds), while sufficiency-based measures such as predictive parity are much less studied. This paper considers predictive parity, which requires equalizing the probability of success given a positive prediction among different protected groups. We prove that, if the overall performances of different groups vary only moderately, all fair Bayes-optimal classifiers under predictive parity are group-wise thresholding rules. Perhaps surprisingly, this may not hold if group performance levels vary widely; in this case we find that predictive parity among protected groups may lead to within-group unfairness. We then propose an algorithm we call FairBayes-DPP, aiming to ensure predictive parity when our condition is satisfied. FairBayes-DPP is an adaptive thresholding algorithm that aims to achieve predictive parity, while also seeking to maximize test accuracy. We provide supporting experiments conducted on synthetic and empirical data.
Rate-Optimal Contextual Online Matching Bandit
May 07, 2022
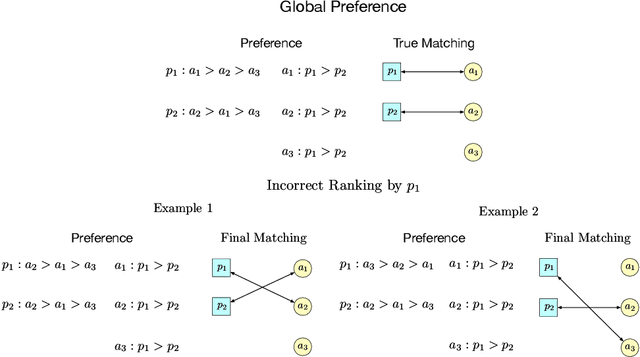
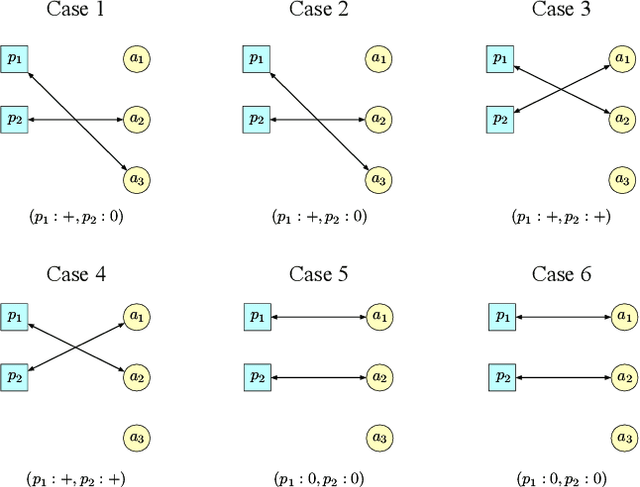
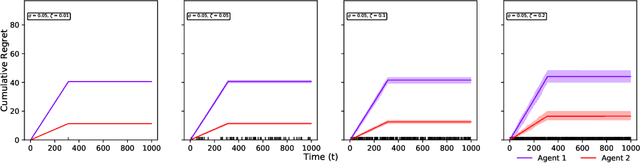
Two-sided online matching platforms have been employed in various markets. However, agents' preferences in present market are usually implicit and unknown and must be learned from data. With the growing availability of side information involved in the decision process, modern online matching methodology demands the capability to track preference dynamics for agents based on their contextual information. This motivates us to consider a novel Contextual Online Matching Bandit prOblem (COMBO), which allows dynamic preferences in matching decisions. Existing works focus on multi-armed bandit with static preference, but this is insufficient: the two-sided preference changes as along as one-side's contextual information updates, resulting in non-static matching. In this paper, we propose a Centralized Contextual - Explore Then Commit (CC-ETC) algorithm to adapt to the COMBO. CC-ETC solves online matching with dynamic preference. In theory, we show that CC-ETC achieves a sublinear regret upper bound O(log(T)) and is a rate-optimal algorithm by proving a matching lower bound. In the experiments, we demonstrate that CC-ETC is robust to variant preference schemes, dimensions of contexts, reward noise levels, and contexts variation levels.
Federated Online Sparse Decision Making
Mar 20, 2022

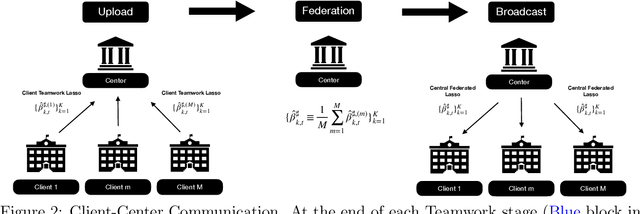
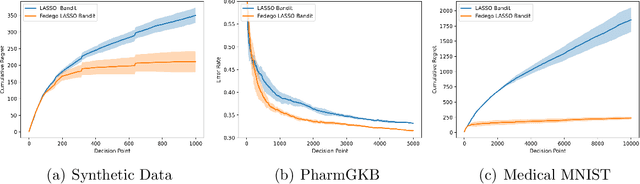
This paper presents a novel federated linear contextual bandits model, where individual clients face different K-armed stochastic bandits with high-dimensional decision context and coupled through common global parameters. By leveraging the sparsity structure of the linear reward , a collaborative algorithm named \texttt{Fedego Lasso} is proposed to cope with the heterogeneity across clients without exchanging local decision context vectors or raw reward data. \texttt{Fedego Lasso} relies on a novel multi-client teamwork-selfish bandit policy design, and achieves near-optimal regrets for shared parameter cases with logarithmic communication costs. In addition, a new conceptual tool called federated-egocentric policies is introduced to delineate exploration-exploitation trade-off. Experiments demonstrate the effectiveness of the proposed algorithms on both synthetic and real-world datasets.
Bayes-Optimal Classifiers under Group Fairness
Mar 11, 2022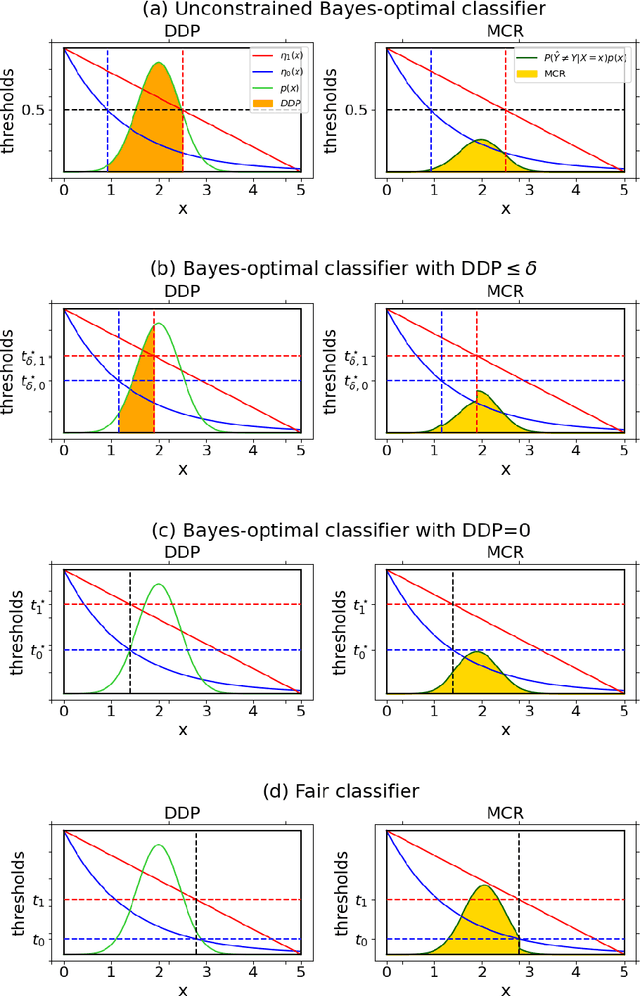
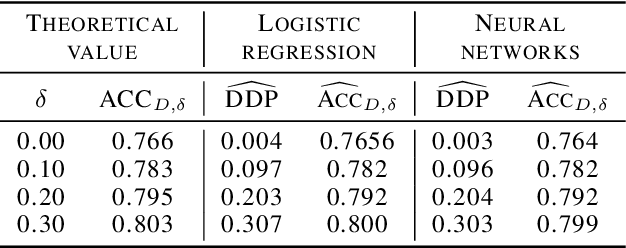
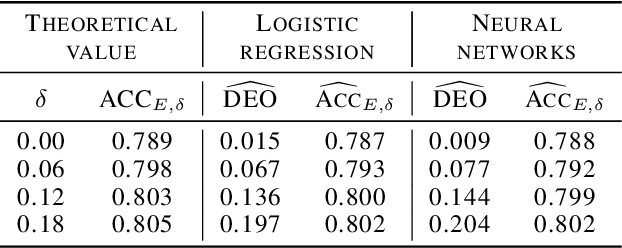
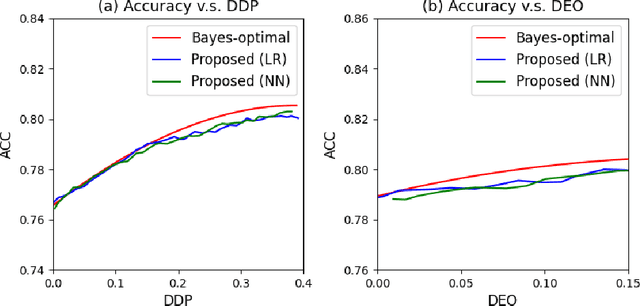
Machine learning algorithms are becoming integrated into more and more high-stakes decision-making processes, such as in social welfare issues. Due to the need of mitigating the potentially disparate impacts from algorithmic predictions, many approaches have been proposed in the emerging area of fair machine learning. However, the fundamental problem of characterizing Bayes-optimal classifiers under various group fairness constraints has only been investigated in some special cases. Based on the classical Neyman-Pearson argument (Neyman and Pearson, 1933; Shao, 2003) for optimal hypothesis testing, this paper provides a unified framework for deriving Bayes-optimal classifiers under group fairness. This enables us to propose a group-based thresholding method that can directly control disparity, and more importantly, achieve an optimal fairness-accuracy tradeoff. These advantages are supported by experiments.
Enhanced Nearest Neighbor Classification for Crowdsourcing
Feb 26, 2022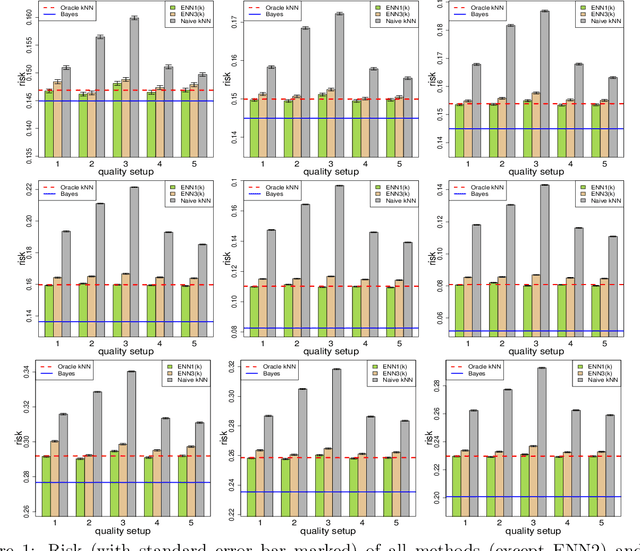
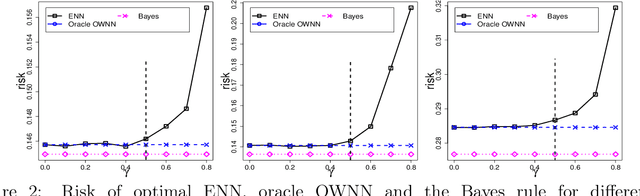
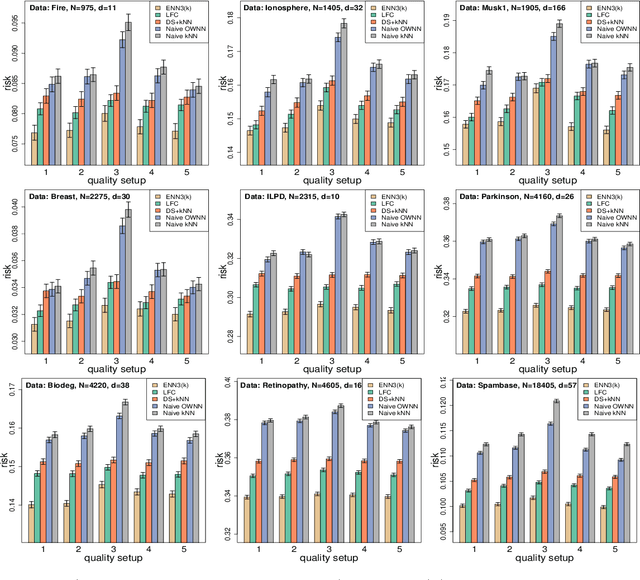
In machine learning, crowdsourcing is an economical way to label a large amount of data. However, the noise in the produced labels may deteriorate the accuracy of any classification method applied to the labelled data. We propose an enhanced nearest neighbor classifier (ENN) to overcome this issue. Two algorithms are developed to estimate the worker quality (which is often unknown in practice): one is to construct the estimate based on the denoised worker labels by applying the $k$NN classifier to the expert data; the other is an iterative algorithm that works even without access to the expert data. Other than strong numerical evidence, our proposed methods are proven to achieve the same regret as its oracle version based on high-quality expert data. As a technical by-product, a lower bound on the sample size assigned to each worker to reach the optimal convergence rate of regret is derived.
Attention Enables Zero Approximation Error
Feb 24, 2022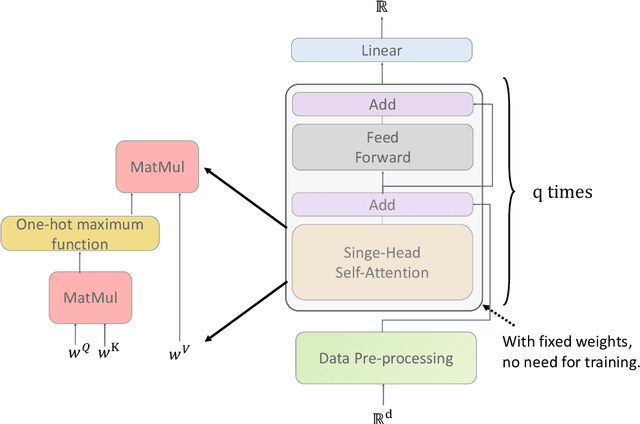

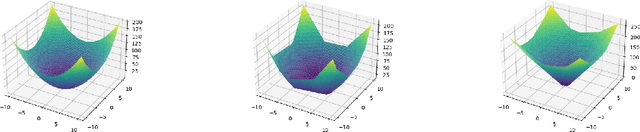
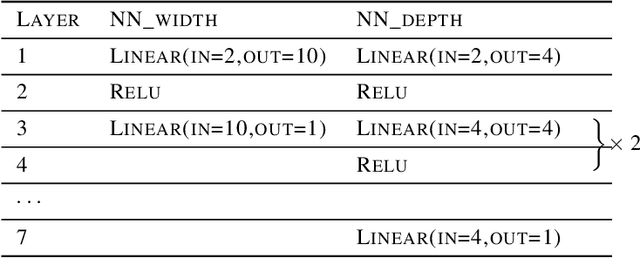
Deep learning models have been widely applied in various aspects of daily life. Many variant models based on deep learning structures have achieved even better performances. Attention-based architectures have become almost ubiquitous in deep learning structures. Especially, the transformer model has now defeated the convolutional neural network in image classification tasks to become the most widely used tool. However, the theoretical properties of attention-based models are seldom considered. In this work, we show that with suitable adaptations, the single-head self-attention transformer with a fixed number of transformer encoder blocks and free parameters is able to generate any desired polynomial of the input with no error. The number of transformer encoder blocks is the same as the degree of the target polynomial. Even more exciting, we find that these transformer encoder blocks in this model do not need to be trained. As a direct consequence, we show that the single-head self-attention transformer with increasing numbers of free parameters is universal. These surprising theoretical results clearly explain the outstanding performances of the transformer model and may shed light on future modifications in real applications. We also provide some experiments to verify our theoretical result.
Optimal Learning Rates of Deep Convolutional Neural Networks: Additive Ridge Functions
Feb 24, 2022Convolutional neural networks have shown extraordinary abilities in many applications, especially those related to the classification tasks. However, for the regression problem, the abilities of convolutional structures have not been fully understood, and further investigation is needed. In this paper, we consider the mean squared error analysis for deep convolutional neural networks. We show that, for additive ridge functions, convolutional neural networks followed by one fully connected layer with ReLU activation functions can reach optimal mini-max rates (up to a log factor). The convergence rates are dimension independent. This work shows the statistical optimality of convolutional neural networks and may shed light on why convolutional neural networks are able to behave well for high dimensional input.
Benefit of Interpolation in Nearest Neighbor Algorithms
Feb 23, 2022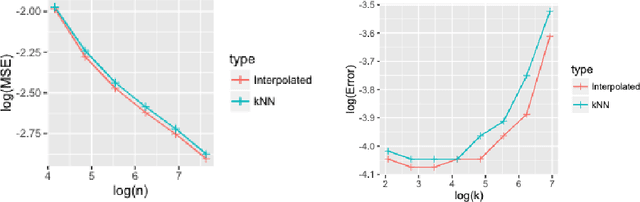
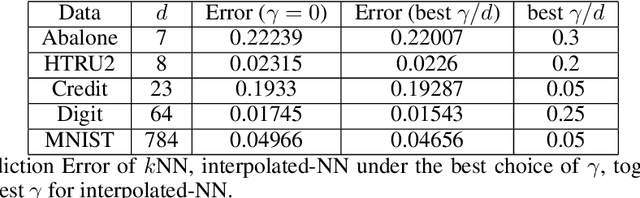
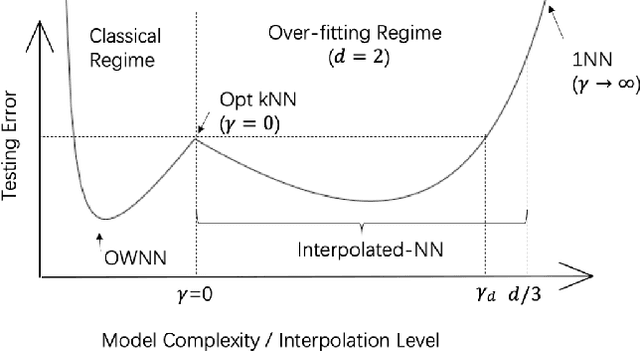
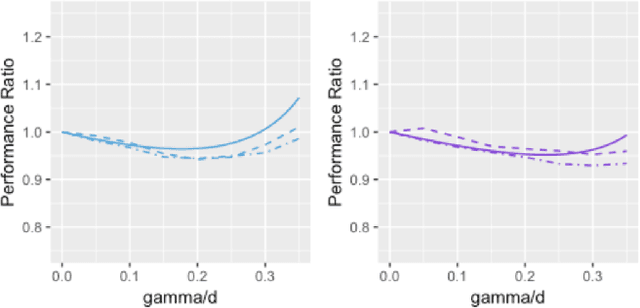
In some studies \citep[e.g.,][]{zhang2016understanding} of deep learning, it is observed that over-parametrized deep neural networks achieve a small testing error even when the training error is almost zero. Despite numerous works towards understanding this so-called "double descent" phenomenon \citep[e.g.,][]{belkin2018reconciling,belkin2019two}, in this paper, we turn into another way to enforce zero training error (without over-parametrization) through a data interpolation mechanism. Specifically, we consider a class of interpolated weighting schemes in the nearest neighbors (NN) algorithms. By carefully characterizing the multiplicative constant in the statistical risk, we reveal a U-shaped performance curve for the level of data interpolation in both classification and regression setups. This sharpens the existing result \citep{belkin2018does} that zero training error does not necessarily jeopardize predictive performances and claims a counter-intuitive result that a mild degree of data interpolation actually {\em strictly} improve the prediction performance and statistical stability over those of the (un-interpolated) $k$-NN algorithm. In the end, the universality of our results, such as change of distance measure and corrupted testing data, will also be discussed.