 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePast, Present, and Future Approaches Using Computer Vision for Animal Re-Identification from Camera Trap Data
Nov 19, 2018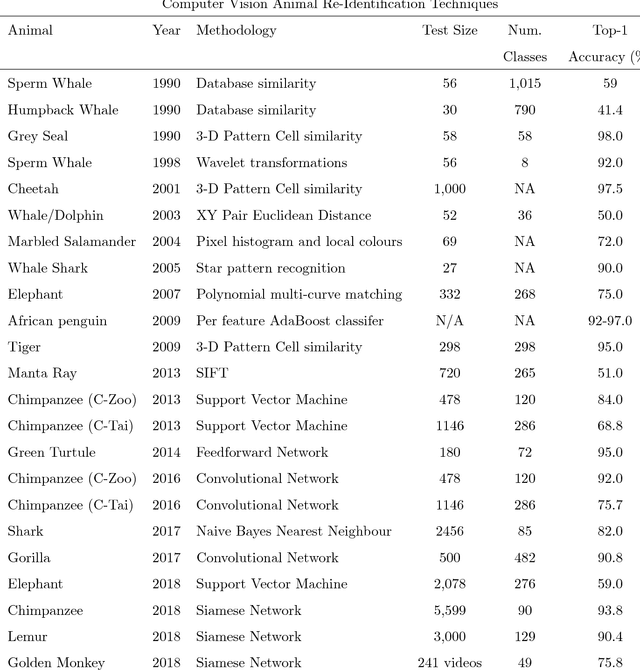
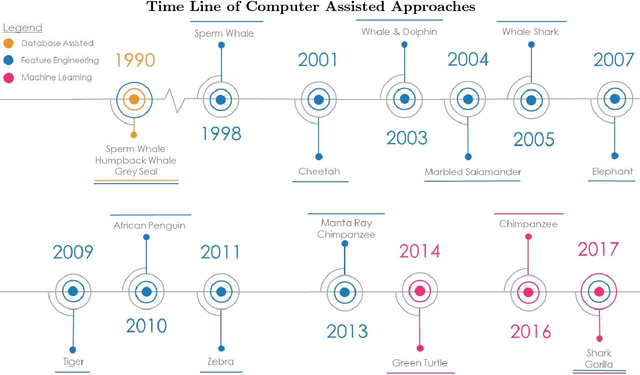
The ability of a researcher to re-identify (re-ID) an individual animal upon re-encounter is fundamental for addressing a broad range of questions in the study of ecosystem function, community and population dynamics, and behavioural ecology. In this review, we describe a brief history of camera traps for re-ID, present a collection of computer vision feature engineering methodologies previously used for animal re-ID, provide an introduction to the underlying mechanisms of deep learning relevant to animal re-ID, highlight the success of deep learning methods for human re-ID, describe the few ecological studies currently utilizing deep learning for camera trap analyses, and our predictions for near future methodologies based on the rapid development of deep learning methods. By utilizing novel deep learning methods for object detection and similarity comparisons, ecologists can extract animals from an image/video data and train deep learning classifiers to re-ID animal individuals beyond the capabilities of a human observer. This methodology will allow ecologists with camera/video trap data to re-identify individuals that exit and re-enter the camera frame. Our expectation is that this is just the beginning of a major trend that could stand to revolutionize the analysis of camera trap data and, ultimately, our approach to animal ecology.
Glimpse Clouds: Human Activity Recognition from Unstructured Feature Points
Aug 21, 2018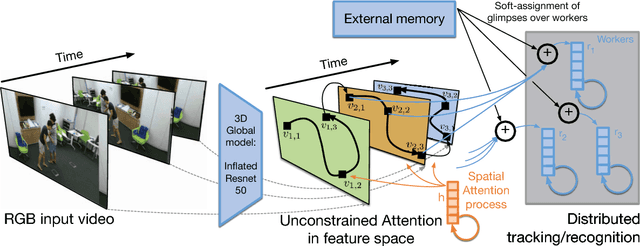
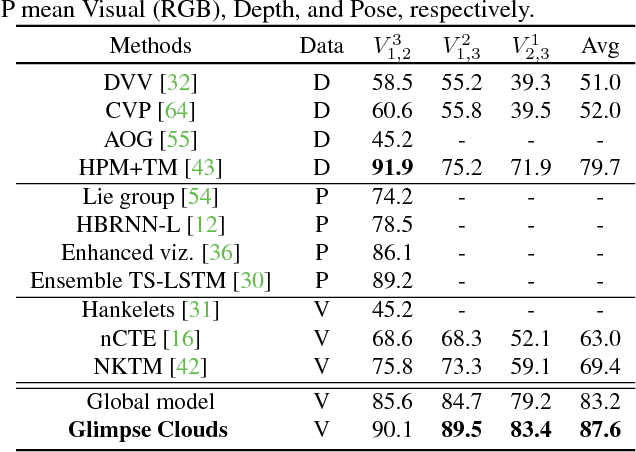
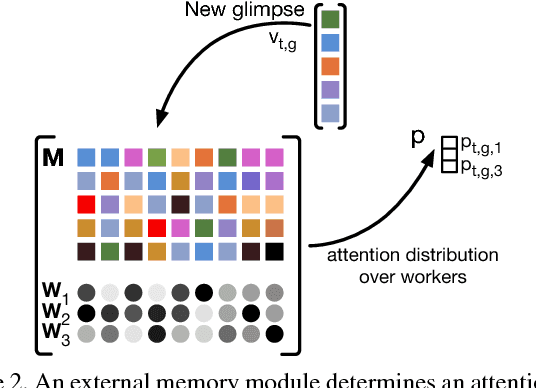
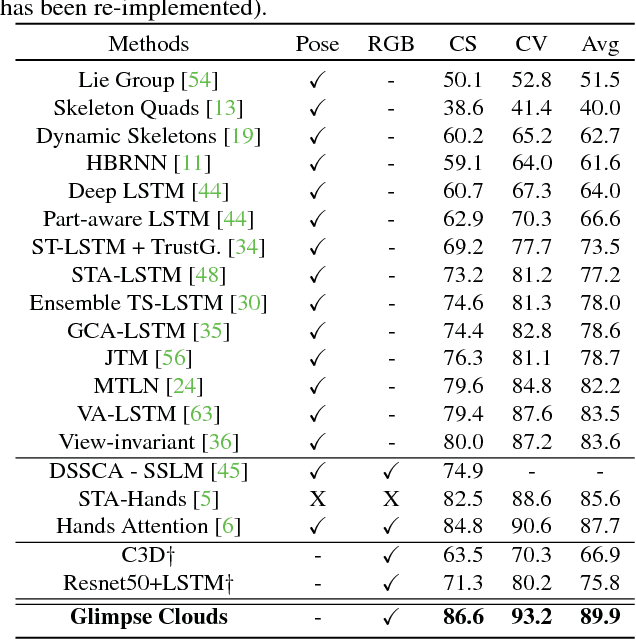
We propose a method for human activity recognition from RGB data that does not rely on any pose information during test time and does not explicitly calculate pose information internally. Instead, a visual attention module learns to predict glimpse sequences in each frame. These glimpses correspond to interest points in the scene that are relevant to the classified activities. No spatial coherence is forced on the glimpse locations, which gives the module liberty to explore different points at each frame and better optimize the process of scrutinizing visual information. Tracking and sequentially integrating this kind of unstructured data is a challenge, which we address by separating the set of glimpses from a set of recurrent tracking/recognition workers. These workers receive glimpses, jointly performing subsequent motion tracking and activity prediction. The glimpses are soft-assigned to the workers, optimizing coherence of the assignments in space, time and feature space using an external memory module. No hard decisions are taken, i.e. each glimpse point is assigned to all existing workers, albeit with different importance. Our methods outperform state-of-the-art methods on the largest human activity recognition dataset available to-date; NTU RGB+D Dataset, and on a smaller human action recognition dataset Northwestern-UCLA Multiview Action 3D Dataset. Our code is publicly available at https://github.com/fabienbaradel/glimpse_clouds.
* CVPR 2018 - project page: https://fabienbaradel.github.io/cvpr18_glimpseclouds/
Self-Paced Learning with Adaptive Deep Visual Embeddings
Jul 24, 2018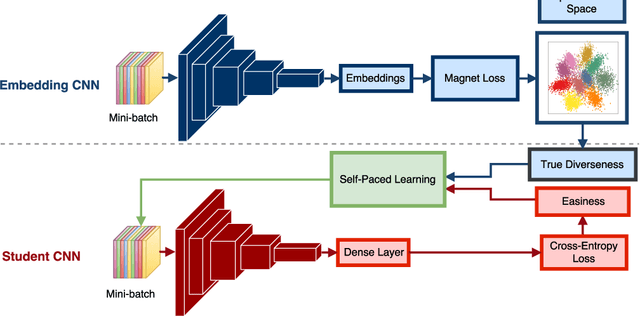

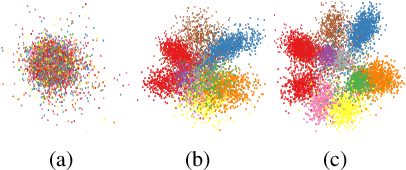
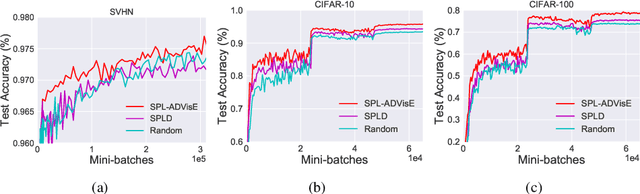
Selecting the most appropriate data examples to present a deep neural network (DNN) at different stages of training is an unsolved challenge. Though practitioners typically ignore this problem, a non-trivial data scheduling method may result in a significant improvement in both convergence and generalization performance. In this paper, we introduce Self-Paced Learning with Adaptive Deep Visual Embeddings (SPL-ADVisE), a novel end-to-end training protocol that unites self-paced learning (SPL) and deep metric learning (DML). We leverage the Magnet Loss to train an embedding convolutional neural network (CNN) to learn a salient representation space. The student CNN classifier dynamically selects similar instance-level training examples to form a mini-batch, where the easiness from the cross-entropy loss and the true diverseness of examples from the learned metric space serve as sample importance priors. To demonstrate the effectiveness of SPL-ADVisE, we use deep CNN architectures for the task of supervised image classification on several coarse- and fine-grained visual recognition datasets. Results show that, across all datasets, the proposed method converges faster and reaches a higher final accuracy than other SPL variants, particularly on fine-grained classes.
Adversarial Training Versus Weight Decay
Jul 23, 2018



Performance-critical machine learning models should be robust to input perturbations not seen during training. Adversarial training is a method for improving a model's robustness to some perturbations by including them in the training process, but this tends to exacerbate other vulnerabilities of the model. The adversarial training framework has the effect of translating the data with respect to the cost function, while weight decay has a scaling effect. Although weight decay could be considered a crude regularization technique, it appears superior to adversarial training as it remains stable over a broader range of regimes and reduces all generalization errors. Equipped with these abstractions, we provide key baseline results and methodology for characterizing robustness. The two approaches can be combined to yield one small model that demonstrates good robustness to several white-box attacks associated with different metrics.
Stochastic Layer-Wise Precision in Deep Neural Networks
Jul 03, 2018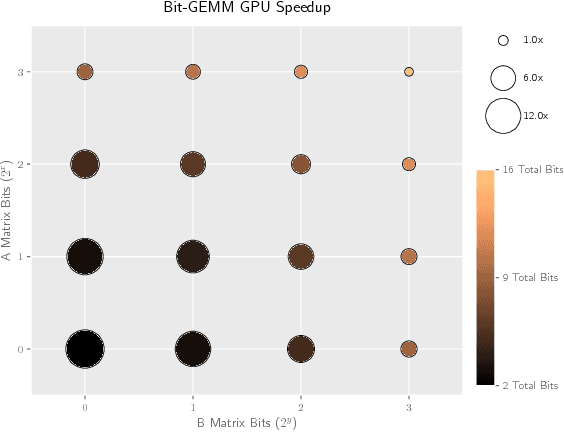
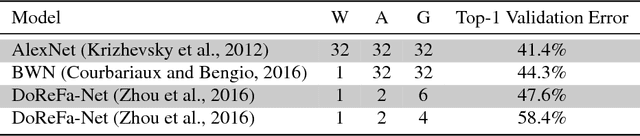
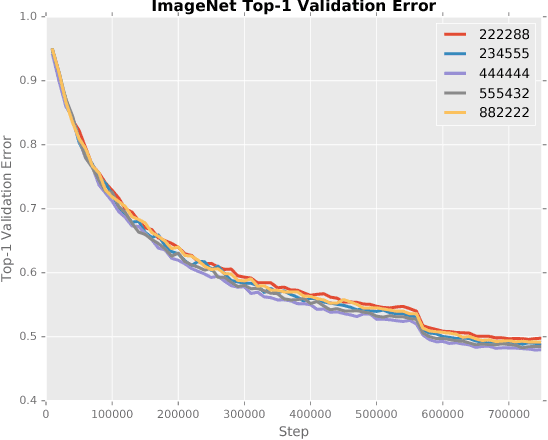
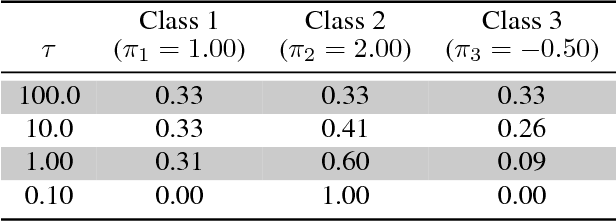
Low precision weights, activations, and gradients have been proposed as a way to improve the computational efficiency and memory footprint of deep neural networks. Recently, low precision networks have even shown to be more robust to adversarial attacks. However, typical implementations of low precision DNNs use uniform precision across all layers of the network. In this work, we explore whether a heterogeneous allocation of precision across a network leads to improved performance, and introduce a learning scheme where a DNN stochastically explores multiple precision configurations through learning. This permits a network to learn an optimal precision configuration. We show on convolutional neural networks trained on MNIST and ILSVRC12 that even though these nets learn a uniform or near-uniform allocation strategy respectively, stochastic precision leads to a favourable regularization effect improving generalization.
Leveraging Uncertainty Estimates for Predicting Segmentation Quality
Jul 02, 2018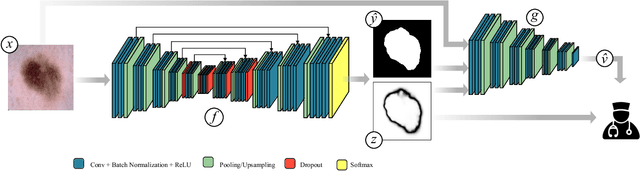
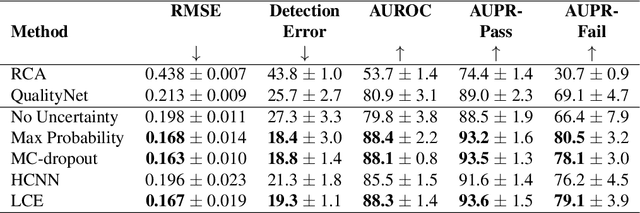
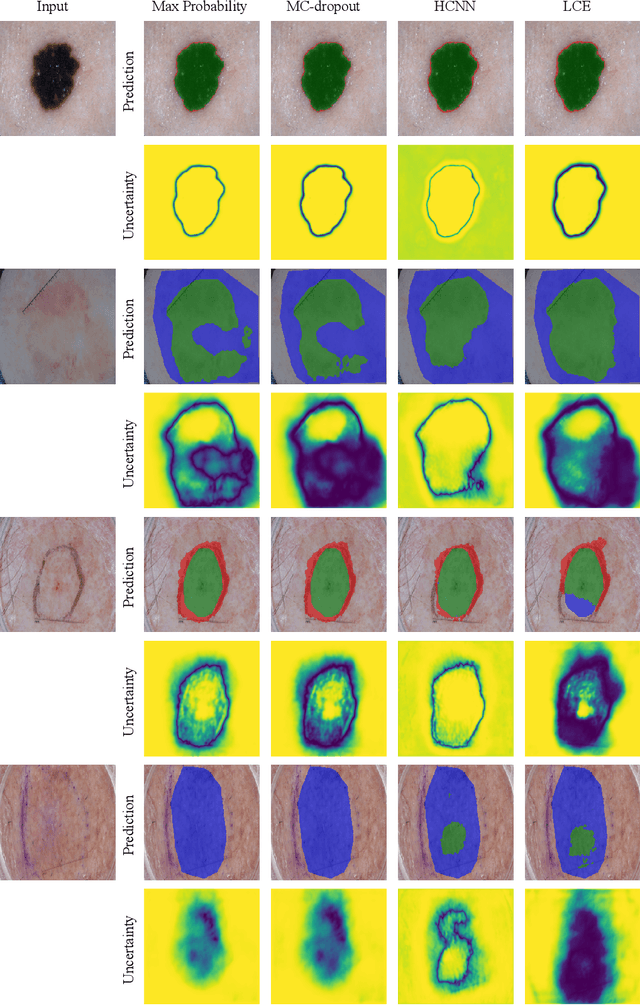
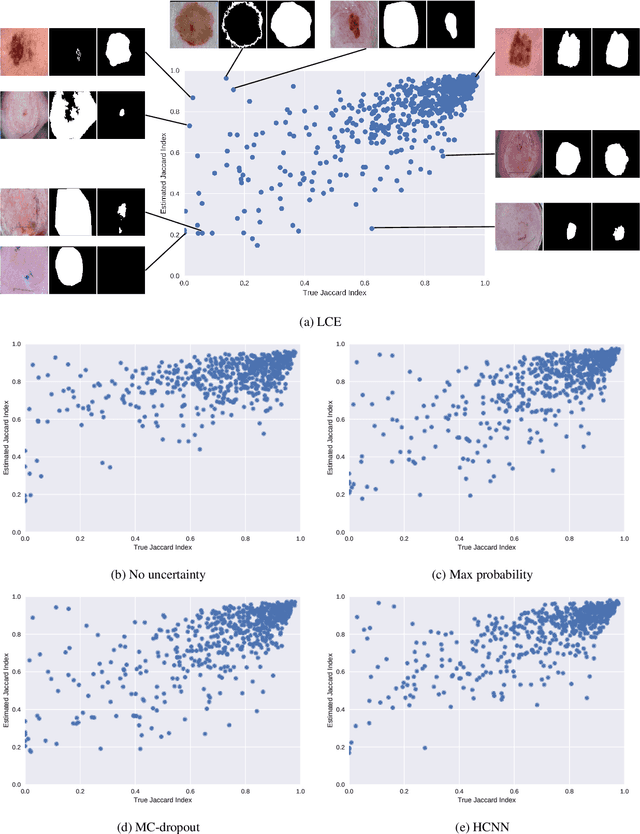
The use of deep learning for medical imaging has seen tremendous growth in the research community. One reason for the slow uptake of these systems in the clinical setting is that they are complex, opaque and tend to fail silently. Outside of the medical imaging domain, the machine learning community has recently proposed several techniques for quantifying model uncertainty (i.e.~a model knowing when it has failed). This is important in practical settings, as we can refer such cases to manual inspection or correction by humans. In this paper, we aim to bring these recent results on estimating uncertainty to bear on two important outputs in deep learning-based segmentation. The first is producing spatial uncertainty maps, from which a clinician can observe where and why a system thinks it is failing. The second is quantifying an image-level prediction of failure, which is useful for isolating specific cases and removing them from automated pipelines. We also show that reasoning about spatial uncertainty, the first output, is a useful intermediate representation for generating segmentation quality predictions, the second output. We propose a two-stage architecture for producing these measures of uncertainty, which can accommodate any deep learning-based medical segmentation pipeline.
Generalized Hadamard-Product Fusion Operators for Visual Question Answering
Apr 06, 2018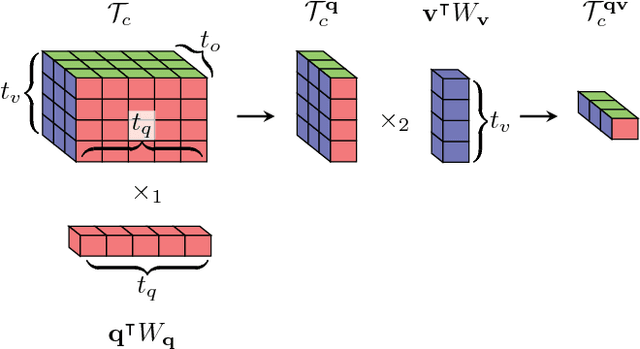
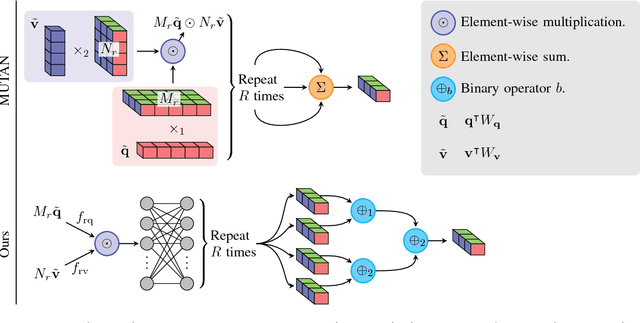
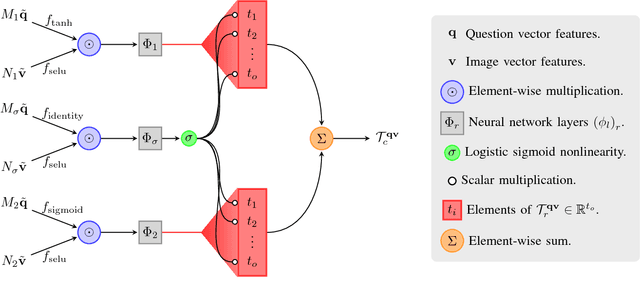
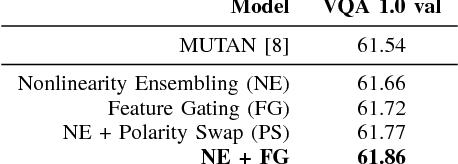
We propose a generalized class of multimodal fusion operators for the task of visual question answering (VQA). We identify generalizations of existing multimodal fusion operators based on the Hadamard product, and show that specific non-trivial instantiations of this generalized fusion operator exhibit superior performance in terms of OpenEnded accuracy on the VQA task. In particular, we introduce Nonlinearity Ensembling, Feature Gating, and post-fusion neural network layers as fusion operator components, culminating in an absolute percentage point improvement of $1.1\%$ on the VQA 2.0 test-dev set over baseline fusion operators, which use the same features as input. We use our findings as evidence that our generalized class of fusion operators could lead to the discovery of even superior task-specific operators when used as a search space in an architecture search over fusion operators.
Deep Learning Object Detection Methods for Ecological Camera Trap Data
Mar 28, 2018



Deep learning methods for computer vision tasks show promise for automating the data analysis of camera trap images. Ecological camera traps are a common approach for monitoring an ecosystem's animal population, as they provide continual insight into an environment without being intrusive. However, the analysis of camera trap images is expensive, labour intensive, and time consuming. Recent advances in the field of deep learning for object detection show promise towards automating the analysis of camera trap images. Here, we demonstrate their capabilities by training and comparing two deep learning object detection classifiers, Faster R-CNN and YOLO v2.0, to identify, quantify, and localize animal species within camera trap images using the Reconyx Camera Trap and the self-labeled Gold Standard Snapshot Serengeti data sets. When trained on large labeled datasets, object recognition methods have shown success. We demonstrate their use, in the context of realistically sized ecological data sets, by testing if object detection methods are applicable for ecological research scenarios when utilizing transfer learning. Faster R-CNN outperformed YOLO v2.0 with average accuracies of 93.0\% and 76.7\% on the two data sets, respectively. Our findings show promising steps towards the automation of the labourious task of labeling camera trap images, which can be used to improve our understanding of the population dynamics of ecosystems across the planet.
Real-Time End-to-End Action Detection with Two-Stream Networks
Feb 23, 2018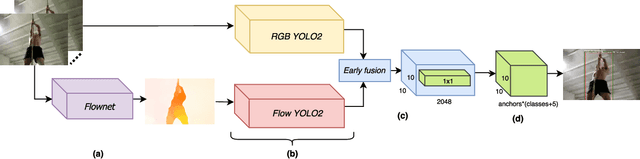
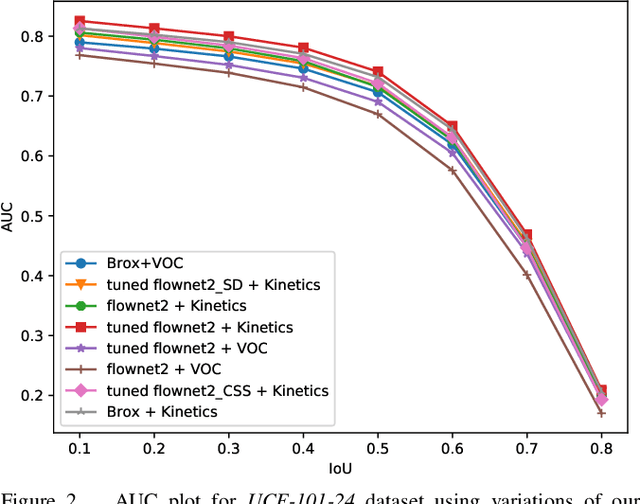

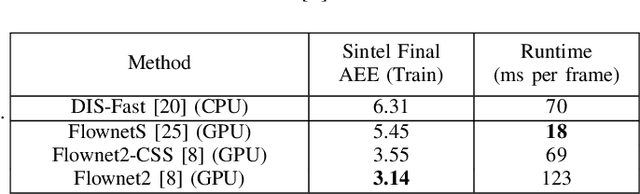
Two-stream networks have been very successful for solving the problem of action detection. However, prior work using two-stream networks train both streams separately, which prevents the network from exploiting regularities between the two streams. Moreover, unlike the visual stream, the dominant forms of optical flow computation typically do not maximally exploit GPU parallelism. We present a real-time end-to-end trainable two-stream network for action detection. First, we integrate the optical flow computation in our framework by using Flownet2. Second, we apply early fusion for the two streams and train the whole pipeline jointly end-to-end. Finally, for better network initialization, we transfer from the task of action recognition to action detection by pre-training our framework using the recently released large-scale Kinetics dataset. Our experimental results show that training the pipeline jointly end-to-end with fine-tuning the optical flow for the objective of action detection improves detection performance significantly. Additionally, we observe an improvement when initializing with parameters pre-trained using Kinetics. Last, we show that by integrating the optical flow computation, our framework is more efficient, running at real-time speeds (up to 31 fps).
Learning Confidence for Out-of-Distribution Detection in Neural Networks
Feb 13, 2018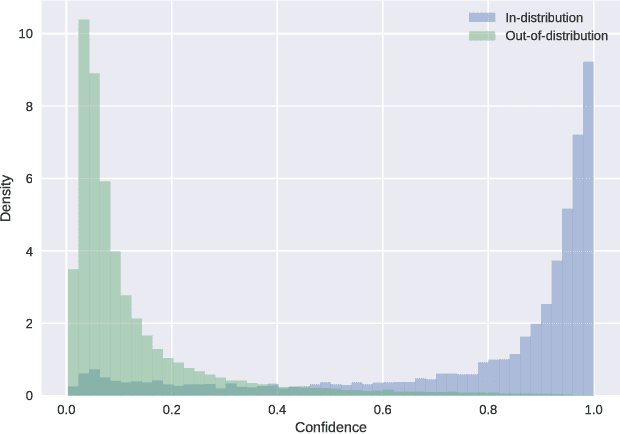
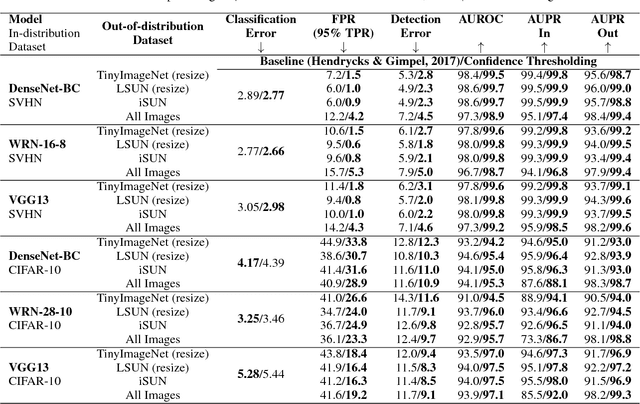
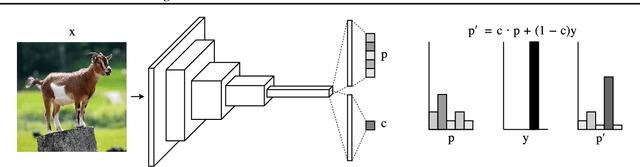
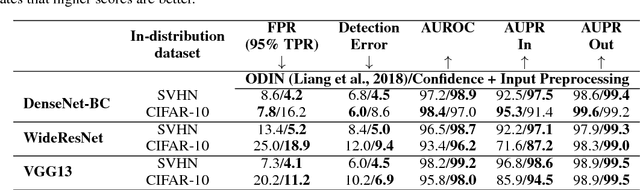
Modern neural networks are very powerful predictive models, but they are often incapable of recognizing when their predictions may be wrong. Closely related to this is the task of out-of-distribution detection, where a network must determine whether or not an input is outside of the set on which it is expected to safely perform. To jointly address these issues, we propose a method of learning confidence estimates for neural networks that is simple to implement and produces intuitively interpretable outputs. We demonstrate that on the task of out-of-distribution detection, our technique surpasses recently proposed techniques which construct confidence based on the network's output distribution, without requiring any additional labels or access to out-of-distribution examples. Additionally, we address the problem of calibrating out-of-distribution detectors, where we demonstrate that misclassified in-distribution examples can be used as a proxy for out-of-distribution examples.