 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying and interpreting tuning dimensions in deep networks
Nov 05, 2020



In neuroscience, a tuning dimension is a stimulus attribute that accounts for much of the activation variance of a group of neurons. These are commonly used to decipher the responses of such groups. While researchers have attempted to manually identify an analogue to these tuning dimensions in deep neural networks, we are unaware of an automatic way to discover them. This work contributes an unsupervised framework for identifying and interpreting "tuning dimensions" in deep networks. Our method correctly identifies the tuning dimensions of a synthetic Gabor filter bank and tuning dimensions of the first two layers of InceptionV1 trained on ImageNet.
Instance Selection for GANs
Jul 30, 2020
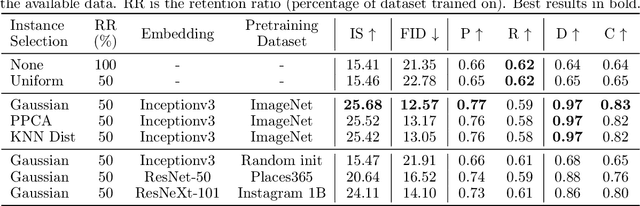
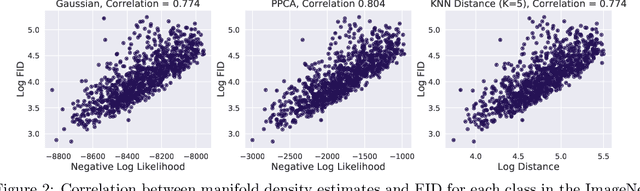
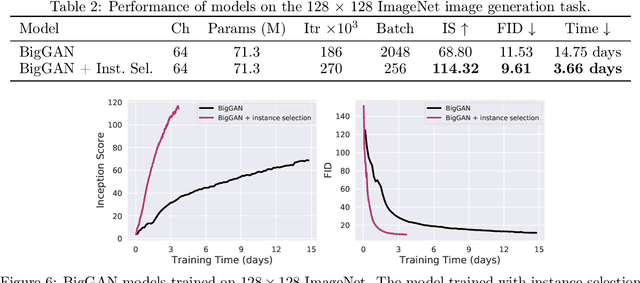
Recent advances in Generative Adversarial Networks (GANs) have led to their widespread adoption for the purposes of generating high quality synthetic imagery. While capable of generating photo-realistic images, these models often produce unrealistic samples which fall outside of the data manifold. Several recently proposed techniques attempt to avoid spurious samples, either by rejecting them after generation, or by truncating the model's latent space. While effective, these methods are inefficient, as large portions of model capacity are dedicated towards representing samples that will ultimately go unused. In this work we propose a novel approach to improve sample quality: altering the training dataset via instance selection before model training has taken place. To this end, we embed data points into a perceptual feature space and use a simple density model to remove low density regions from the data manifold. By refining the empirical data distribution before training we redirect model capacity towards high-density regions, which ultimately improves sample fidelity. We evaluate our method by training a Self-Attention GAN on ImageNet at 64x64 resolution, where we outperform the current state-of-the-art models on this task while using 1/2 of the parameters. We also highlight training time savings by training a BigGAN on ImageNet at 128x128 resolution, achieving a 66% increase in Inception Score and a 16% improvement in FID over the baseline model with less than 1/4 the training time.
Generative Graph Perturbations for Scene Graph Prediction
Jul 11, 2020



Inferring objects and their relationships from an image is useful in many applications at the intersection of vision and language. Due to a long tail data distribution, the task is challenging, with the inevitable appearance of zero-shot compositions of objects and relationships at test time. Current models often fail to properly understand a scene in such cases, as during training they only observe a tiny fraction of the distribution corresponding to the most frequent compositions. This motivates us to study whether increasing the diversity of the training distribution, by generating replacement for parts of real scene graphs, can lead to better generalization? We employ generative adversarial networks (GANs) conditioned on scene graphs to generate augmented visual features. To increase their diversity, we propose several strategies to perturb the conditioning. One of them is to use a language model, such as BERT, to synthesize plausible yet still unlikely scene graphs. By evaluating our model on Visual Genome, we obtain both positive and negative results. This prompts us to make several observations that can potentially lead to further improvements.
Enabling Continual Learning with Differentiable Hebbian Plasticity
Jun 30, 2020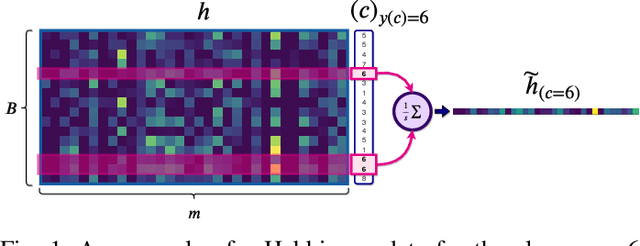
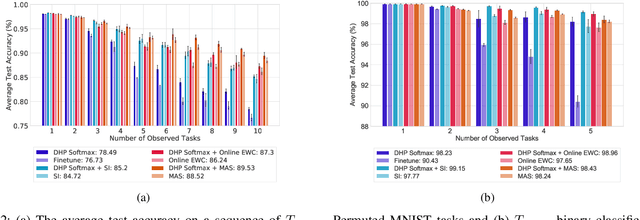
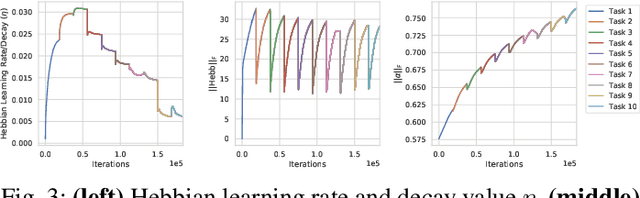
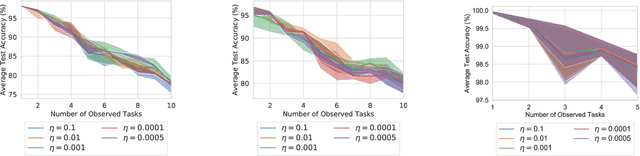
Continual learning is the problem of sequentially learning new tasks or knowledge while protecting previously acquired knowledge. However, catastrophic forgetting poses a grand challenge for neural networks performing such learning process. Thus, neural networks that are deployed in the real world often struggle in scenarios where the data distribution is non-stationary (concept drift), imbalanced, or not always fully available, i.e., rare edge cases. We propose a Differentiable Hebbian Consolidation model which is composed of a Differentiable Hebbian Plasticity (DHP) Softmax layer that adds a rapid learning plastic component (compressed episodic memory) to the fixed (slow changing) parameters of the softmax output layer; enabling learned representations to be retained for a longer timescale. We demonstrate the flexibility of our method by integrating well-known task-specific synaptic consolidation methods to penalize changes in the slow weights that are important for each target task. We evaluate our approach on the Permuted MNIST, Split MNIST and Vision Datasets Mixture benchmarks, and introduce an imbalanced variant of Permuted MNIST -- a dataset that combines the challenges of class imbalance and concept drift. Our proposed model requires no additional hyperparameters and outperforms comparable baselines by reducing forgetting.
Graph Density-Aware Losses for Novel Compositions in Scene Graph Generation
May 17, 2020
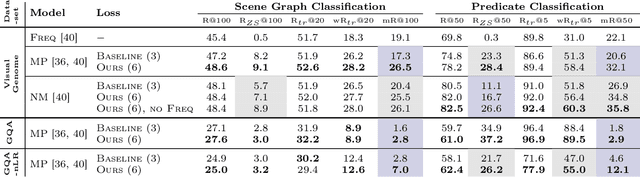
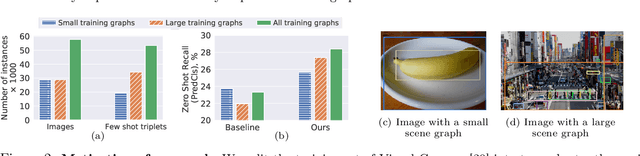
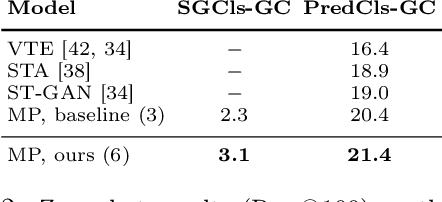
Scene graph generation (SGG) aims to predict graph-structured descriptions of input images, in the form of objects and relationships between them. This task is becoming increasingly useful for progress at the interface of vision and language. Here, it is important - yet challenging - to perform well on novel (zero-shot) or rare (few-shot) compositions of objects and relationships. In this paper, we identify two key issues that limit such generalization. Firstly, we show that the standard loss used in this task is unintentionally a function of scene graph density. This leads to the neglect of individual edges in large sparse graphs during training, even though these contain diverse few-shot examples that are important for generalization. Secondly, the frequency of relationships can create a strong bias in this task, such that a blind model predicting the most frequent relationship achieves good performance. Consequently, some state-of-the-art models exploit this bias to improve results. We show that such models can suffer the most in their ability to generalize to rare compositions, evaluating two different models on the Visual Genome dataset and its more recent, improved version, GQA. To address these issues, we introduce a density-normalized edge loss, which provides more than a two-fold improvement in certain generalization metrics. Compared to other works in this direction, our enhancements require only a few lines of code and no added computational cost. We also highlight the difficulty of accurately evaluating models using existing metrics, especially on zero/few shots, and introduce a novel weighted metric.
Sample-Efficient Model-based Actor-Critic for an Interactive Dialogue Task
Apr 28, 2020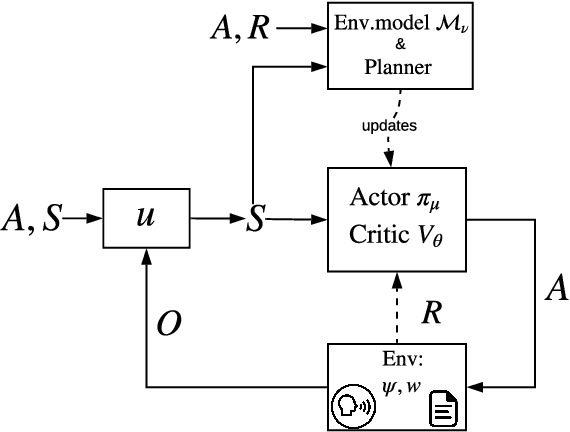
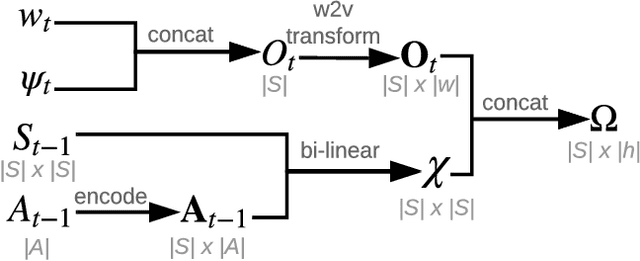
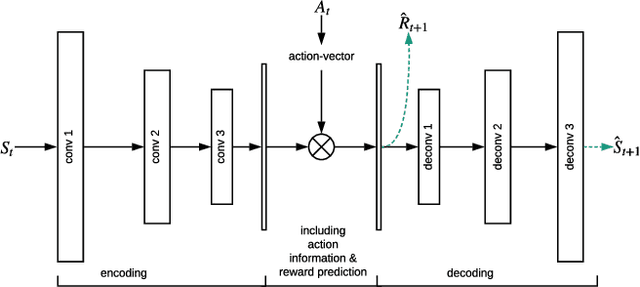
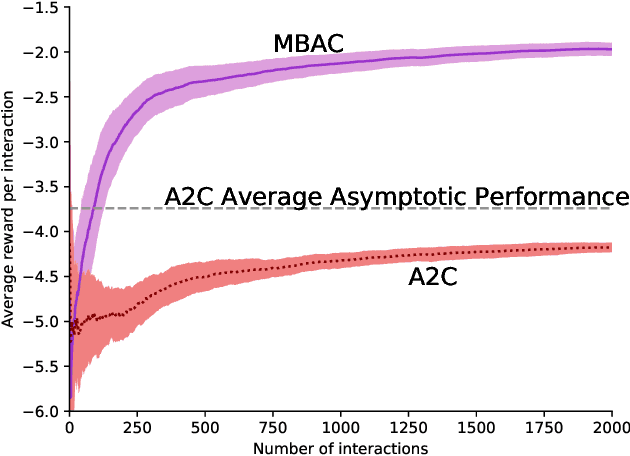
Human-computer interactive systems that rely on machine learning are becoming paramount to the lives of millions of people who use digital assistants on a daily basis. Yet, further advances are limited by the availability of data and the cost of acquiring new samples. One way to address this problem is by improving the sample efficiency of current approaches. As a solution path, we present a model-based reinforcement learning algorithm for an interactive dialogue task. We build on commonly used actor-critic methods, adding an environment model and planner that augments a learning agent to learn the model of the environment dynamics. Our results show that, on a simulation that mimics the interactive task, our algorithm requires 70 times fewer samples, compared to the baseline of commonly used model-free algorithm, and demonstrates 2~times better performance asymptotically. Moreover, we introduce a novel contribution of computing a soft planner policy and further updating a model-free policy yielding a less computationally expensive model-free agent as good as the model-based one. This model-based architecture serves as a foundation that can be extended to other human-computer interactive tasks allowing further advances in this direction.
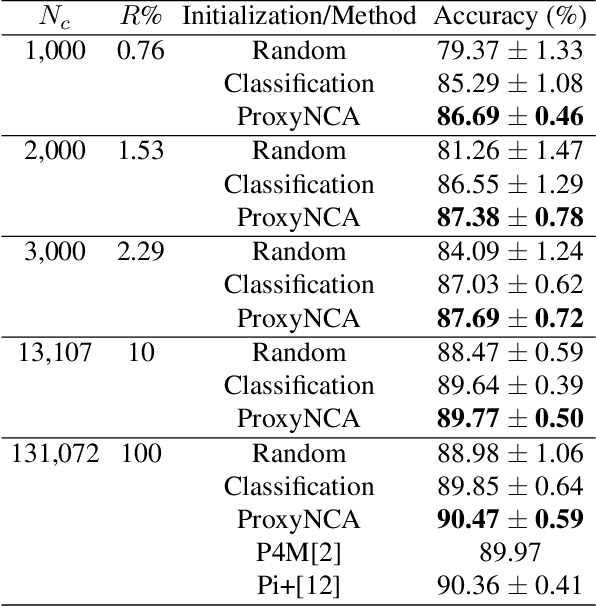
ProxyNCA++: Revisiting and Revitalizing Proxy Neighborhood Component Analysis
Apr 02, 2020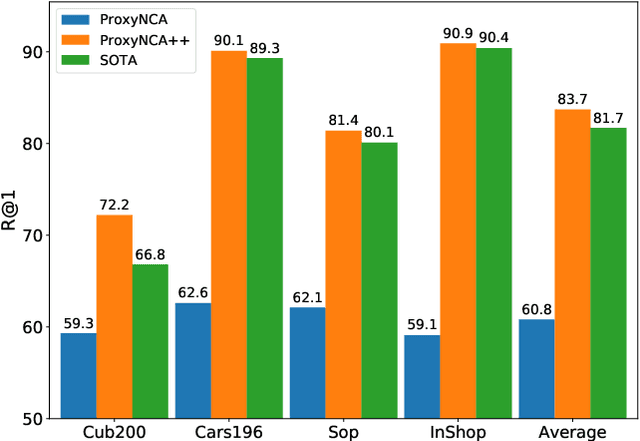
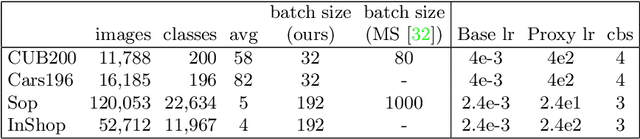
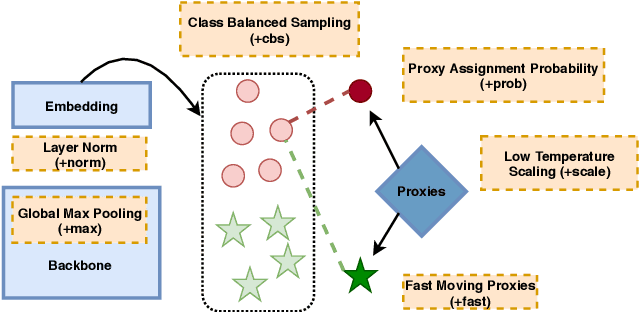

We consider the problem of distance metric learning (DML), where the task is to learn an effective similarity measure between images. We revisit ProxyNCA and incorporate several enhancements. We find that low temperature scaling is a performance-critical component and explain why it works. Besides, we also discover that Global Max Pooling works better in general when compared to Global Average Pooling. Additionally, our proposed fast moving proxies also addresses small gradient issue of proxies, and this component synergizes well with low temperature scaling and Global Max Pooling. Our enhanced model, called ProxyNCA++, achieves a 22.9 percentage point average improvement of Recall@1 across four different zero-shot retrieval datasets compared to the original ProxyNCA algorithm. Furthermore, we achieve state-of-the-art results on the CUB200, Cars196, Sop, and InShop datasets, achieving Recall@1 scores of 72.2, 90.1, 81.4, and 90.9, respectively.
Learning with less data via Weakly Labeled Patch Classification in Digital Pathology
Jan 10, 2020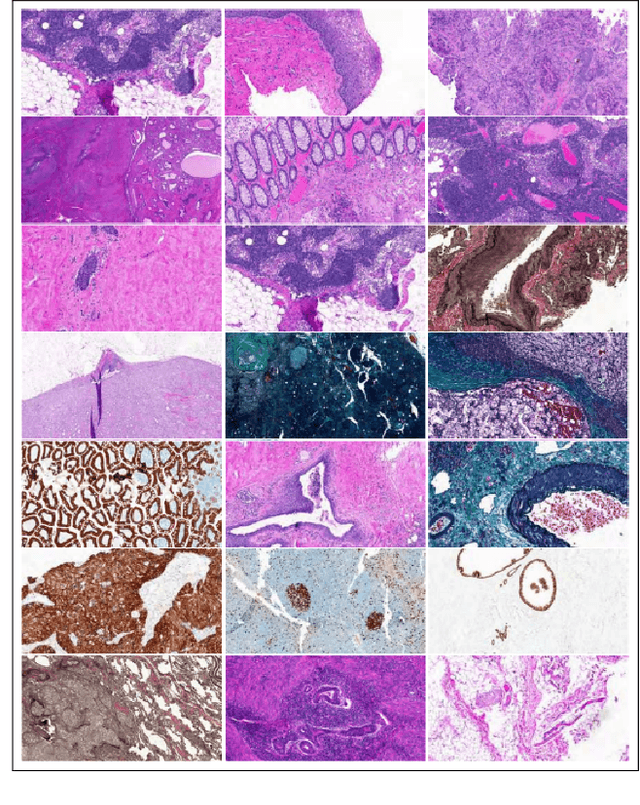

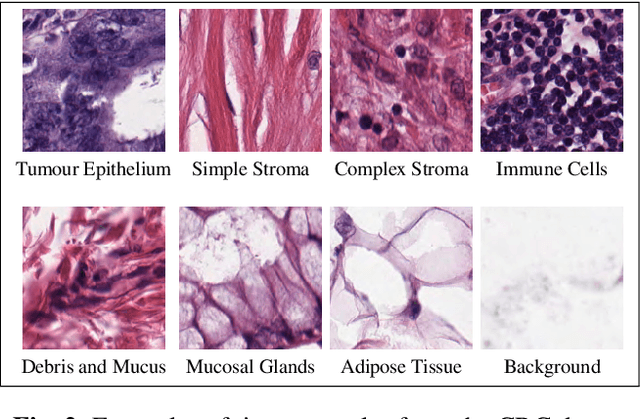
In Digital Pathology (DP), labeled data is generally very scarce due to the requirement that medical experts provide annotations. We address this issue by learning transferable features from weakly labeled data, which are collected from various parts of the body and are organized by non-medical experts. In this paper, we show that features learned from such weakly labeled datasets are indeed transferable and allow us to achieve highly competitive patch classification results on the colorectal cancer (CRC) dataset [1] and the PatchCamelyon (PCam) dataset [2] while using an order of magnitude less labeled data.
Skip-Clip: Self-Supervised Spatiotemporal Representation Learning by Future Clip Order Ranking
Oct 28, 2019

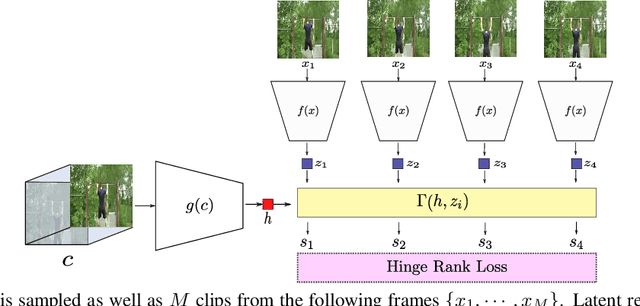

Deep neural networks require collecting and annotating large amounts of data to train successfully. In order to alleviate the annotation bottleneck, we propose a novel self-supervised representation learning approach for spatiotemporal features extracted from videos. We introduce Skip-Clip, a method that utilizes temporal coherence in videos, by training a deep model for future clip order ranking conditioned on a context clip as a surrogate objective for video future prediction. We show that features learned using our method are generalizable and transfer strongly to downstream tasks. For action recognition on the UCF101 dataset, we obtain 51.8% improvement over random initialization and outperform models initialized using inflated ImageNet parameters. Skip-Clip also achieves results competitive with state-of-the-art self-supervision methods.
A Nonparametric Bayesian Model for Sparse Temporal Multigraphs
Oct 11, 2019As the availability and importance of temporal interaction data--such as email communication--increases, it becomes increasingly important to understand the underlying structure that underpins these interactions. Often these interactions form a multigraph, where we might have multiple interactions between two entities. Such multigraphs tend to be sparse yet structured, and their distribution often evolves over time. Existing statistical models with interpretable parameters can capture some, but not all, of these properties. We propose a dynamic nonparametric model for interaction multigraphs that combines the sparsity of edge-exchangeable multigraphs with dynamic clustering patterns that tend to reinforce recent behavioral patterns. We show that our method yields improved held-out likelihood over stationary variants, and impressive predictive performance against a range of state-of-the-art dynamic graph models.