 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Family of LLMs Liberated from Static Vocabularies
Mar 16, 2026Tokenization is a central component of natural language processing in current large language models (LLMs), enabling models to convert raw text into processable units. Although learned tokenizers are widely adopted, they exhibit notable limitations, including their large, fixed vocabulary sizes and poor adaptability to new domains or languages. We present a family of models with up to 70 billion parameters based on the hierarchical autoregressive transformer (HAT) architecture. In HAT, an encoder transformer aggregates bytes into word embeddings and then feeds them to the backbone, a classical autoregressive transformer. The outputs of the backbone are then cross-attended by the decoder and converted back into bytes. We show that we can reuse available pre-trained models by converting the Llama 3.1 8B and 70B models into the HAT architecture: Llama-3.1-8B-TFree-HAT and Llama-3.1-70B-TFree-HAT are byte-level models whose encoder and decoder are trained from scratch, but where we adapt the pre-trained Llama backbone, i.e., the transformer blocks with the embedding matrix and head removed, to handle word embeddings instead of the original tokens. We also provide a 7B HAT model, Llama-TFree-HAT-Pretrained, trained entirely from scratch on nearly 4 trillion words. The HAT architecture improves text compression by reducing the number of required sequence positions and enhances robustness to intra-word variations, e.g., spelling differences. Through pre-training, as well as subsequent supervised fine-tuning and direct preference optimization in English and German, we show strong proficiency in both languages, improving on the original Llama 3.1 in most benchmarks. We release our models (including 200 pre-training checkpoints) on Hugging Face.
Quality-Diversity through AI Feedback
Oct 31, 2023



In many text-generation problems, users may prefer not only a single response, but a diverse range of high-quality outputs from which to choose. Quality-diversity (QD) search algorithms aim at such outcomes, by continually improving and diversifying a population of candidates. However, the applicability of QD to qualitative domains, like creative writing, has been limited by the difficulty of algorithmically specifying measures of quality and diversity. Interestingly, recent developments in language models (LMs) have enabled guiding search through AI feedback, wherein LMs are prompted in natural language to evaluate qualitative aspects of text. Leveraging this development, we introduce Quality-Diversity through AI Feedback (QDAIF), wherein an evolutionary algorithm applies LMs to both generate variation and evaluate the quality and diversity of candidate text. When assessed on creative writing domains, QDAIF covers more of a specified search space with high-quality samples than do non-QD controls. Further, human evaluation of QDAIF-generated creative texts validates reasonable agreement between AI and human evaluation. Our results thus highlight the potential of AI feedback to guide open-ended search for creative and original solutions, providing a recipe that seemingly generalizes to many domains and modalities. In this way, QDAIF is a step towards AI systems that can independently search, diversify, evaluate, and improve, which are among the core skills underlying human society's capacity for innovation.
Domain-Level Explainability -- A Challenge for Creating Trust in Superhuman AI Strategies
Nov 12, 2020
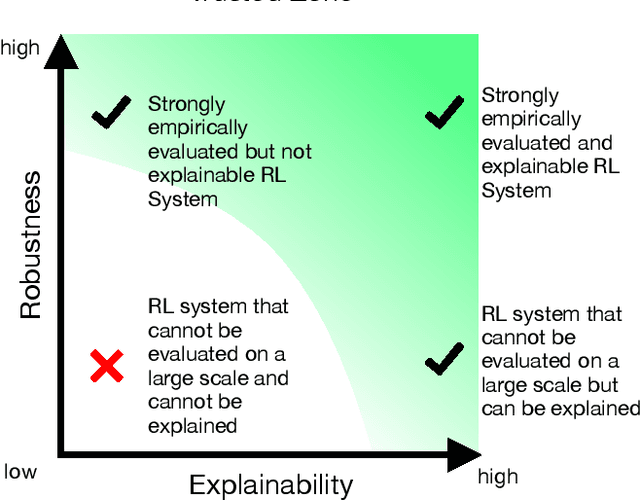
For strategic problems, intelligent systems based on Deep Reinforcement Learning (DRL) have demonstrated an impressive ability to learn advanced solutions that can go far beyond human capabilities, especially when dealing with complex scenarios. While this creates new opportunities for the development of intelligent assistance systems with groundbreaking functionalities, applying this technology to real-world problems carries significant risks and therefore requires trust in their transparency and reliability. With superhuman strategies being non-intuitive and complex by definition and real-world scenarios prohibiting a reliable performance evaluation, the key components for trust in these systems are difficult to achieve. Explainable AI (XAI) has successfully increased transparency for modern AI systems through a variety of measures, however, XAI research has not yet provided approaches enabling domain level insights for expert users in strategic situations. In this paper, we discuss the existence of superhuman DRL-based strategies, their properties, the requirements and challenges for transforming them into real-world environments, and the implications for trust through explainability as a key technology.