 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning What to Learn for Video Object Segmentation
May 01, 2020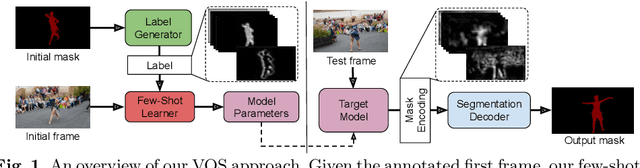

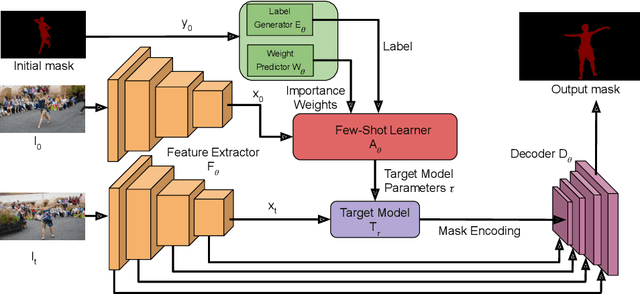
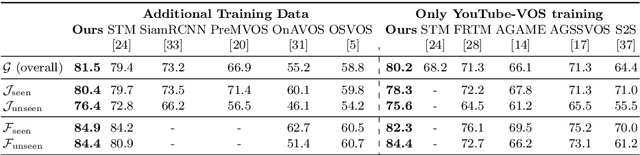
Video object segmentation (VOS) is a highly challenging problem, since the target object is only defined during inference with a given first-frame reference mask. The problem of how to capture and utilize this limited target information remains a fundamental research question. We address this by introducing an end-to-end trainable VOS architecture that integrates a differentiable few-shot learning module. This internal learner is designed to predict a powerful parametric model of the target by minimizing a segmentation error in the first frame. We further go beyond standard few-shot learning techniques by learning what the few-shot learner should learn. This allows us to achieve a rich internal representation of the target in the current frame, significantly increasing the segmentation accuracy of our approach. We perform extensive experiments on multiple benchmarks. Our approach sets a new state-of-the-art on the large-scale YouTube-VOS 2018 dataset by achieving an overall score of 81.5, corresponding to a 2.6% relative improvement over the previous best result.
DCTD: Deep Conditional Target Densities for Accurate Regression
Sep 26, 2019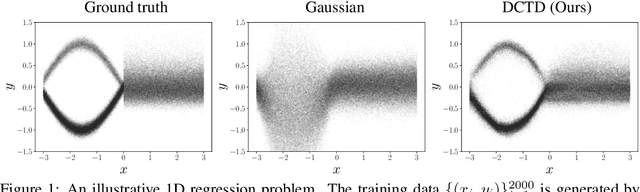


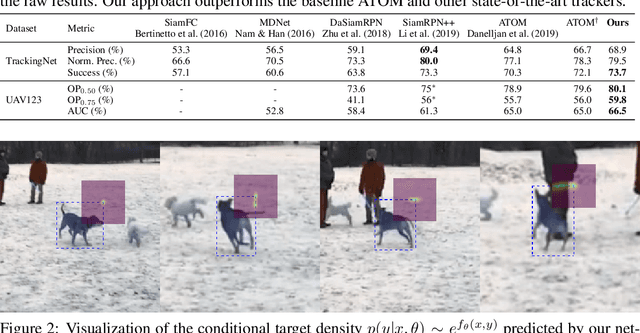
While deep learning-based classification is generally addressed using standardized approaches, a wide variety of techniques are employed for regression. In computer vision, one particularly popular such technique is that of confidence-based regression, which entails predicting a confidence value for each input-target pair (x, y). While this approach has demonstrated impressive results, it requires important task-dependent design choices, and the predicted confidences often lack a natural probabilistic meaning. We address these issues by proposing Deep Conditional Target Densities (DCTD), a novel and general regression method with a clear probabilistic interpretation. DCTD models the conditional target density p(y|x) by using a neural network to directly predict the un-normalized density from (x, y). This model of p(y|x) is trained by minimizing the associated negative log-likelihood, approximated using Monte Carlo sampling. We perform comprehensive experiments on four computer vision regression tasks. Our approach outperforms direct regression, as well as other probabilistic and confidence-based methods. Notably, our regression model achieves a 1.9% AP improvement over Faster-RCNN for object detection on the COCO dataset, and sets a new state-of-the-art on visual tracking when applied for bounding box regression.
Learning Discriminative Model Prediction for Tracking
Apr 15, 2019

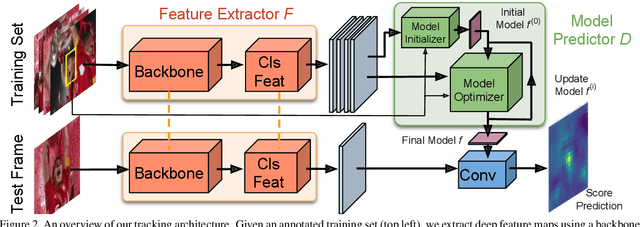
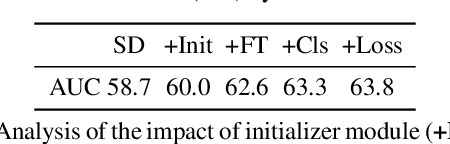
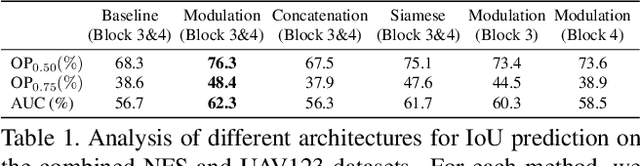
The current strive towards end-to-end trainable computer vision systems imposes major challenges for the task of visual tracking. In contrast to most other vision problems, tracking requires the learning of a robust target-specific appearance model online, during the inference stage. To be end-to-end trainable, the online learning of the target model thus needs to be embedded in the tracking architecture itself. Due to these difficulties, the popular Siamese paradigm simply predicts a target feature template. However, such a model possesses limited discriminative power due to its inability of integrating background information. We develop an end-to-end tracking architecture, capable of fully exploiting both target and background appearance information for target model prediction. Our architecture is derived from a discriminative learning loss by designing a dedicated optimization process that is capable of predicting a powerful model in only a few iterations. Furthermore, our approach is able to learn key aspects of the discriminative loss itself. The proposed tracker sets a new state-of-the-art on 6 tracking benchmarks, achieving an EAO score of 0.440 on VOT2018, while running at over 40 FPS.
ATOM: Accurate Tracking by Overlap Maximization
Nov 19, 2018
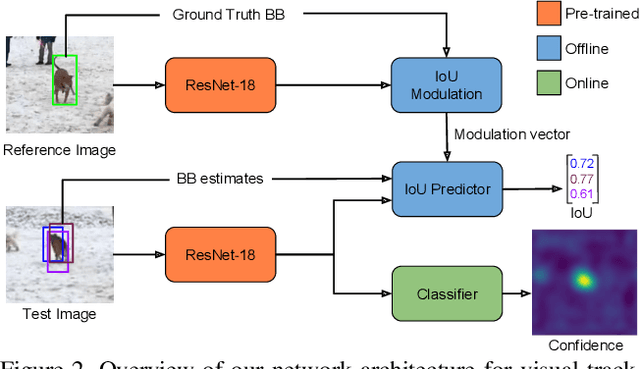
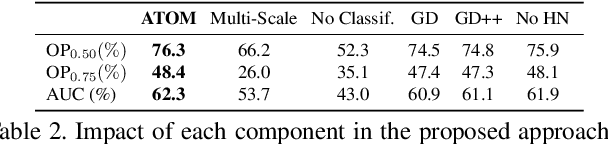
While recent years have witnessed astonishing improvements in visual tracking robustness, the advancements in tracking accuracy have been severely limited. As the focus has been directed towards the development of powerful classifiers, the problem of accurate target state estimation has been largely overlooked. Instead, the majority of methods resort to simple multi-scale search in order to estimate the target bounding box. We argue that this approach is fundamentally limited as target estimation is a complex task, requiring high-level knowledge about the object. We thus address the problem of target state estimation in tracking. We propose a novel tracking architecture consisting of dedicated target estimation and classification components. Due to the complex nature of target estimation, we propose a component that can be entirely trained offline on large-scale datasets. Our target estimation component is trained to predict the overlap between the target object and an estimated bounding box. By carefully integrating target-specific information in the prediction, our approach achieves previously unseen bounding box accuracy. Furthermore, we integrate a classification component that is trained online to guarantee high discriminative power in the presence of distractors. Our final tracking framework, comprised of a unified multi-task architecture, sets a new state-of-the-art on four challenging benchmarks. On the large-scale TrackingNet dataset, our tracker ATOM achieves a relative gain of 15%, while running at over 30 FPS.
Unveiling the Power of Deep Tracking
Apr 18, 2018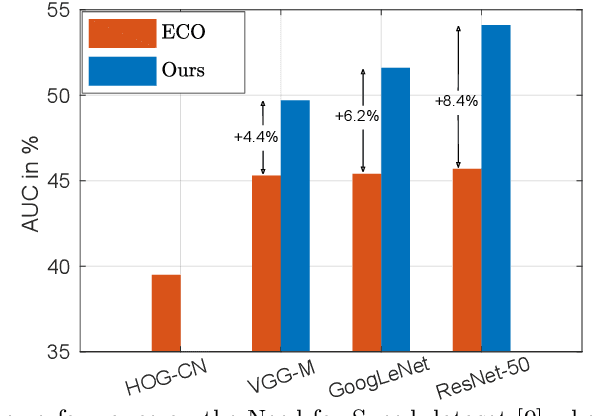

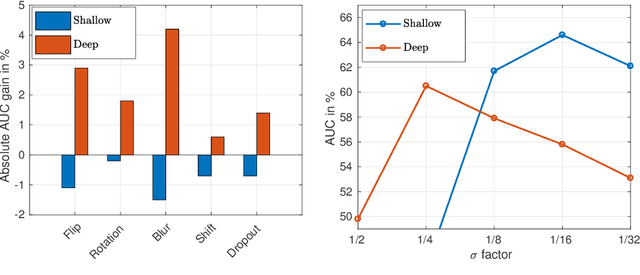
In the field of generic object tracking numerous attempts have been made to exploit deep features. Despite all expectations, deep trackers are yet to reach an outstanding level of performance compared to methods solely based on handcrafted features. In this paper, we investigate this key issue and propose an approach to unlock the true potential of deep features for tracking. We systematically study the characteristics of both deep and shallow features, and their relation to tracking accuracy and robustness. We identify the limited data and low spatial resolution as the main challenges, and propose strategies to counter these issues when integrating deep features for tracking. Furthermore, we propose a novel adaptive fusion approach that leverages the complementary properties of deep and shallow features to improve both robustness and accuracy. Extensive experiments are performed on four challenging datasets. On VOT2017, our approach significantly outperforms the top performing tracker from the challenge with a relative gain of 17% in EAO.
Deep Projective 3D Semantic Segmentation
May 09, 2017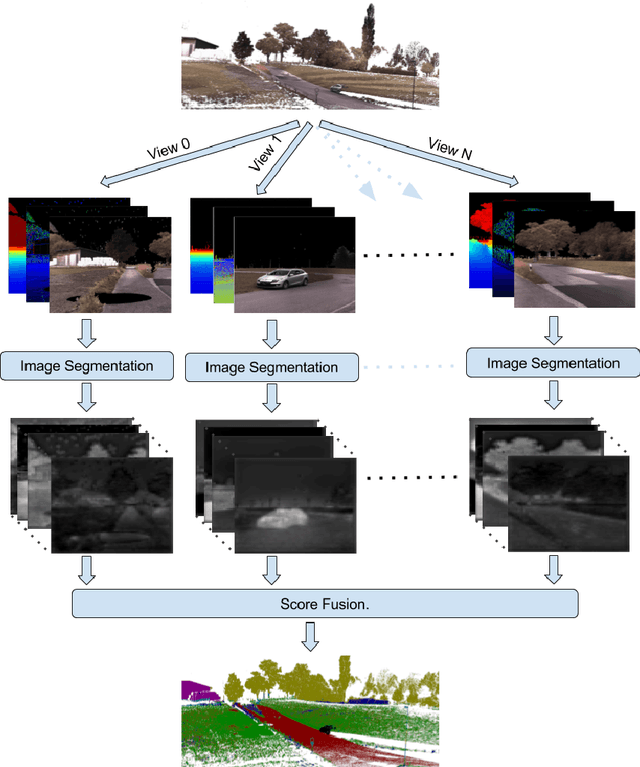


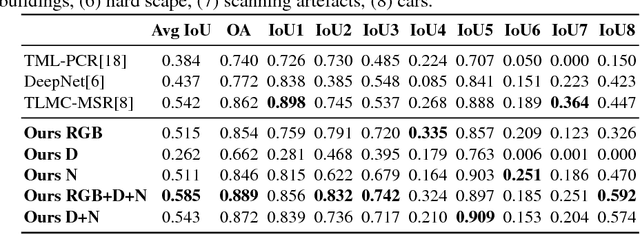
Semantic segmentation of 3D point clouds is a challenging problem with numerous real-world applications. While deep learning has revolutionized the field of image semantic segmentation, its impact on point cloud data has been limited so far. Recent attempts, based on 3D deep learning approaches (3D-CNNs), have achieved below-expected results. Such methods require voxelizations of the underlying point cloud data, leading to decreased spatial resolution and increased memory consumption. Additionally, 3D-CNNs greatly suffer from the limited availability of annotated datasets. In this paper, we propose an alternative framework that avoids the limitations of 3D-CNNs. Instead of directly solving the problem in 3D, we first project the point cloud onto a set of synthetic 2D-images. These images are then used as input to a 2D-CNN, designed for semantic segmentation. Finally, the obtained prediction scores are re-projected to the point cloud to obtain the segmentation results. We further investigate the impact of multiple modalities, such as color, depth and surface normals, in a multi-stream network architecture. Experiments are performed on the recent Semantic3D dataset. Our approach sets a new state-of-the-art by achieving a relative gain of 7.9 %, compared to the previous best approach.
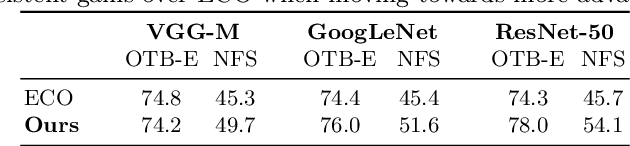
ECO: Efficient Convolution Operators for Tracking
Apr 10, 2017
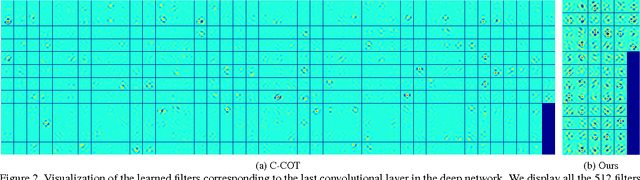
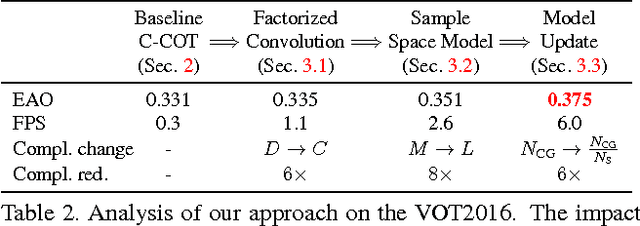
In recent years, Discriminative Correlation Filter (DCF) based methods have significantly advanced the state-of-the-art in tracking. However, in the pursuit of ever increasing tracking performance, their characteristic speed and real-time capability have gradually faded. Further, the increasingly complex models, with massive number of trainable parameters, have introduced the risk of severe over-fitting. In this work, we tackle the key causes behind the problems of computational complexity and over-fitting, with the aim of simultaneously improving both speed and performance. We revisit the core DCF formulation and introduce: (i) a factorized convolution operator, which drastically reduces the number of parameters in the model; (ii) a compact generative model of the training sample distribution, that significantly reduces memory and time complexity, while providing better diversity of samples; (iii) a conservative model update strategy with improved robustness and reduced complexity. We perform comprehensive experiments on four benchmarks: VOT2016, UAV123, OTB-2015, and TempleColor. When using expensive deep features, our tracker provides a 20-fold speedup and achieves a 13.0% relative gain in Expected Average Overlap compared to the top ranked method in the VOT2016 challenge. Moreover, our fast variant, using hand-crafted features, operates at 60 Hz on a single CPU, while obtaining 65.0% AUC on OTB-2015.