 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTheoretical Analysis of Engression and Reverse Markov Engression
May 31, 2026Engression is a recently proposed and effective framework for conditional distribution learning. Its multi-step Reverse Markov extension further improves generative flexibility by decomposing complex conditional sampling into sequential reverse transitions. Despite their strong empirical performance, rigorous finite-sample statistical guarantees for these methods remain unavailable. In this paper, under deep neural network parameterizations, we establish nonasymptotic convergence bounds for Engression by directly controlling the Energy Distance between the learned and target conditional distributions. For the Reverse Markov framework, we further develop an Energy-Distance-based chain rule that enables a rigorous analysis of error propagation across reverse steps. Our analysis yields corresponding excess-risk bounds that are near-optimal up to logarithmic factors relative to the classical minimax rate over a general Hölder class.
Efficient Synthetic Network Generation via Latent Embedding Reconstruction
May 31, 2026Network data are ubiquitous across the social sciences, biology, and information systems. Generating realistic synthetic network data has broad applications from network simulation to scientific discovery. However, many existing black-box approaches for network generation tend to overfit observed data while overlooking characteristic network structure, and incur substantial computational overhead at scale. These practical challenges call for synthetic network generation methods that are both efficient and capable of capturing structural properties of networks. In this paper, we introduce Synthetic Network Generation via Latent Embedding Reconstruction (SyNGLER), a general and efficient framework for synthetic network generation that builds on latent space network models. Given an observed network, SyNGLER first learns low-dimensional latent node embeddings via a latent space network model and then reconstructs the latent space by building a distribution-free generator over these embeddings. For generation, SyNGLER first samples (or resamples) node embeddings from the generator in the latent space and then produces synthetic networks using the latent space network model. Through the latent space framework, SyNGLER preserves unique characteristics in networks such as sparsity and node degree heterogeneity, while allowing for efficient training with lower computational cost than many existing deep architectures. We provide theoretical guarantees by developing consistency results on the distance between the true and synthetic edge distributions. Empirical studies further demonstrate the effectiveness of SyNGLER, which efficiently produces networks that better preserve key network characteristics such as network moments and degree distributions compared with existing approaches. Code is available at https://github.com/FeifanJiang/syngler.
tinyBenchmarks: evaluating LLMs with fewer examples
Feb 22, 2024



The versatility of large language models (LLMs) led to the creation of diverse benchmarks that thoroughly test a variety of language models' abilities. These benchmarks consist of tens of thousands of examples making evaluation of LLMs very expensive. In this paper, we investigate strategies to reduce the number of evaluations needed to assess the performance of an LLM on several key benchmarks. For example, we show that to accurately estimate the performance of an LLM on MMLU, a popular multiple-choice QA benchmark consisting of 14K examples, it is sufficient to evaluate this LLM on 100 curated examples. We release evaluation tools and tiny versions of popular benchmarks: Open LLM Leaderboard, MMLU, HELM, and AlpacaEval 2.0. Our empirical analysis demonstrates that these tools and tiny benchmarks are sufficient to reliably and efficiently reproduce the original evaluation results.
Learning Latent and Hierarchical Structures in Cognitive Diagnosis Models
Apr 05, 2021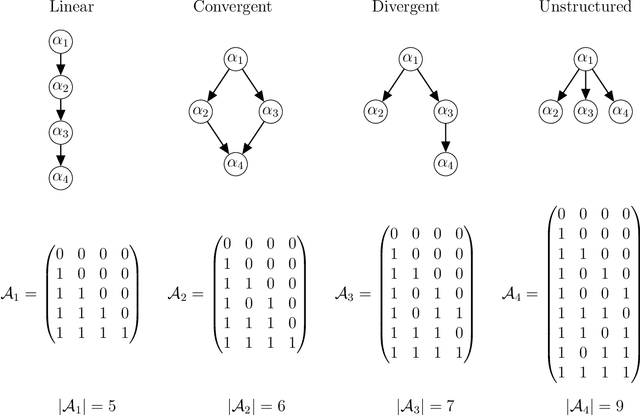
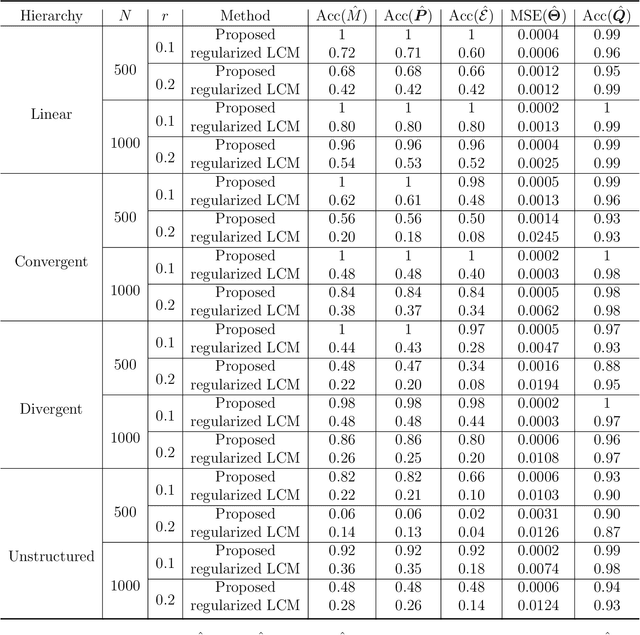

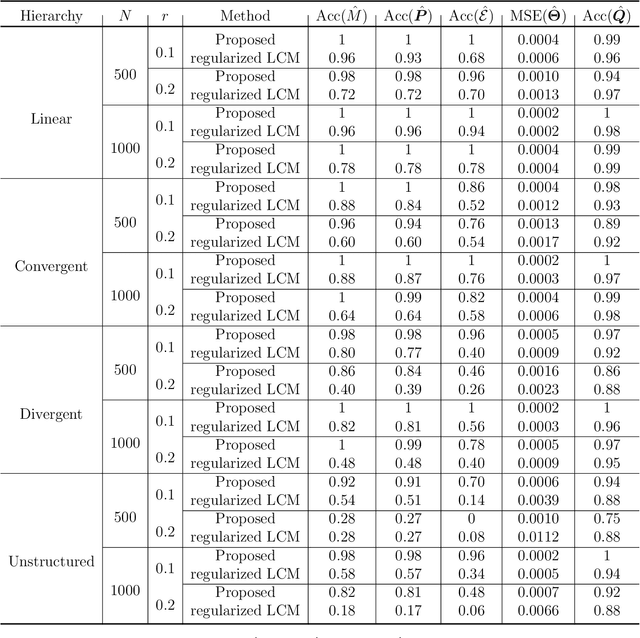
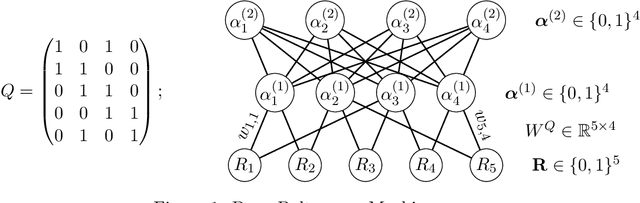
Cognitive Diagnosis Models (CDMs) are a special family of discrete latent variable models that are widely used in modern educational, psychological, social and biological sciences. A key component of CDMs is a binary $Q$-matrix characterizing the dependence structure between the items and the latent attributes. Additionally, researchers also assume in many applications certain hierarchical structures among the latent attributes to characterize their dependence. In most CDM applications, the attribute-attribute hierarchical structures, the item-attribute $Q$-matrix, the item-level diagnostic model, as well as the number of latent attributes, need to be fully or partially pre-specified, which however may be subjective and misspecified as noted by many recent studies. This paper considers the problem of jointly learning these latent and hierarchical structures in CDMs from observed data with minimal model assumptions. Specifically, a penalized likelihood approach is proposed to select the number of attributes and estimate the latent and hierarchical structures simultaneously. An efficient expectation-maximization (EM) algorithm and a latent structure recovery algorithm are developed, and statistical consistency theory is also established under mild conditions. The good performance of the proposed method is illustrated by simulation studies and a real data application in educational assessment.
Identification and Estimation of Hierarchical Latent Attribute Models
Jun 19, 2019
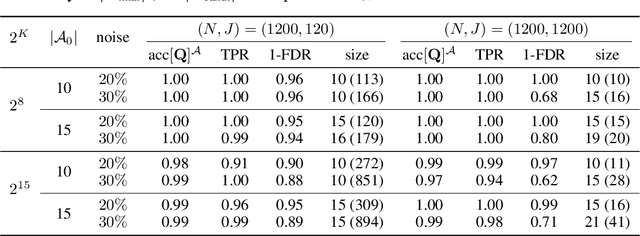
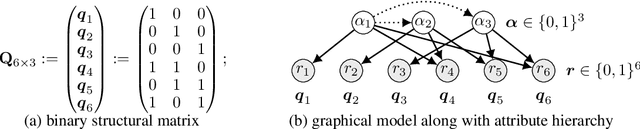
Hierarchical Latent Attribute Models (HLAMs) are a popular family of discrete latent variable models widely used in social and biological sciences. The key ingredients of an HLAM include a binary structural matrix specifying how the observed variables depend on the latent attributes, and also certain hierarchical constraints on allowable configurations of the latent attributes. This paper studies the theoretical identifiability issue and the practical estimation problem of HLAMs. For identification, the challenging problem of identifiability under a complex hierarchy is addressed and sufficient and almost necessary identification conditions are proposed. For estimation, a scalable algorithm for estimating both the structural matrix and the attribute hierarchy is developed. The superior performance of the proposed algorithm is demonstrated in various experimental settings, including both synthetic data and a real dataset from an international educational assessment.
Learning Attribute Patterns in High-Dimensional Structured Latent Attribute Models
Apr 08, 2019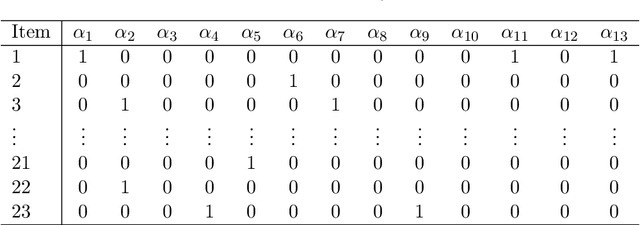
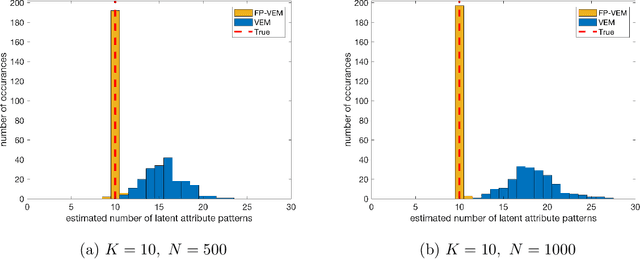
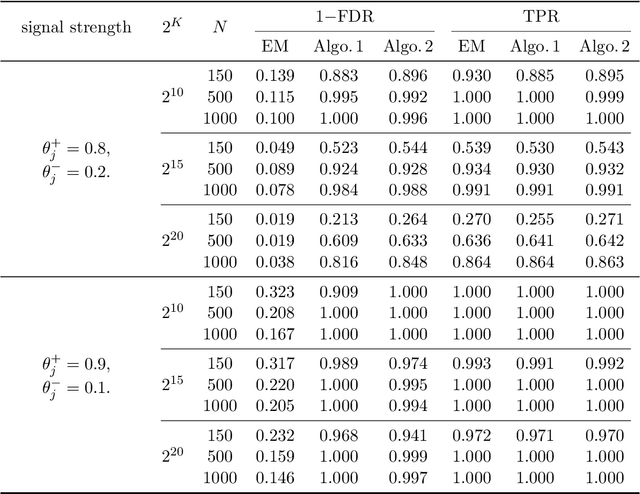
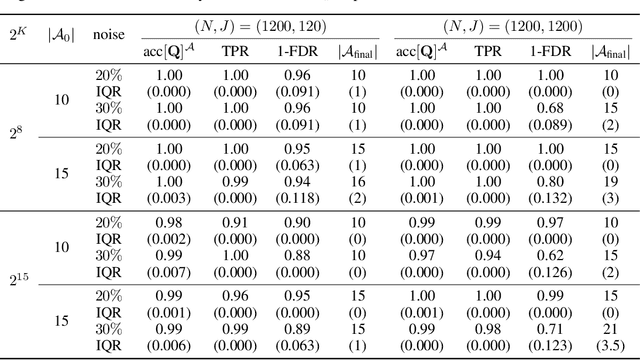
Structured latent attribute models (SLAMs) are a special family of discrete latent variable models widely used in social and biological sciences. This paper considers the problem of learning significant attribute patterns from a SLAM with potentially high-dimensional configurations of the latent attributes. We address the theoretical identifiability issue, propose a penalized likelihood method for the selection of the attribute patterns, and further establish the selection consistency in such an overfitted SLAM with diverging number of latent patterns. The good performance of the proposed methodology is illustrated by simulation studies and two real datasets in educational assessment.